 liuzx
2 years ago
liuzx
2 years ago
22 changed files with 1033 additions and 0 deletions
Split View
Diff Options
-
+7 -0README.md
-
BINgpu_mnist_example/Example_Picture/基础镜像.png
-
+100 -0gpu_mnist_example/Example_Picture/快速创建GPU训练任务.md
-
BINgpu_mnist_example/Example_Picture/结果下载.png
-
BINgpu_mnist_example/Example_Picture/适用A100的基础镜像.png
-
+54 -0gpu_mnist_example/README.md
-
+35 -0gpu_mnist_example/model.py
-
+115 -0gpu_mnist_example/train_gpu.py
-
+109 -0npu_mnist_example/Example_Picture/快速创建NPU训练任务.md
-
BINnpu_mnist_example/Example_Picture/数据集上传位置.png
-
BINnpu_mnist_example/Example_Picture/新建训练任务页面.png
-
BINnpu_mnist_example/Example_Picture/查看日志页面.png
-
BINnpu_mnist_example/Example_Picture/模型下载页面.png
-
BINnpu_mnist_example/Example_Picture/运行参数界面.png
-
+74 -0npu_mnist_example/README.md
-
+33 -0npu_mnist_example/config.py
-
+60 -0npu_mnist_example/dataset.py
-
+54 -0npu_mnist_example/dataset_distributed.py
-
+60 -0npu_mnist_example/lenet.py
-
+72 -0npu_mnist_example/read_imagenet.py
-
+122 -0npu_mnist_example/train_continue.py
-
+138 -0npu_mnist_example/train_npu.py
+ 7
- 0
README.md
View File
| @@ -10,6 +10,13 @@ | |||
| pip install -U openi | |||
| ``` | |||
| 若是在智算训练任务中无网络,可以使用以下指令安装 | |||
| ```text | |||
| import os | |||
| os.system("pip install {}".format(os.getenv("OPENI_SDK_PATH"))) | |||
| ``` | |||
| 使用openi包 | |||
| ``` | |||
BIN
gpu_mnist_example/Example_Picture/基础镜像.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 2071 | Height: 1265 | Size: 118 kB |
+ 100
- 0
gpu_mnist_example/Example_Picture/快速创建GPU训练任务.md
View File
| @@ -0,0 +1,100 @@ | |||
| # 如何在启智平台上进行模型训练 - GPU版本 | |||
| - 启智集群单数据集的训练,启智集群多数据集的训练,智算集群的单数据集训练,这3个的训练使用方式不同,请注意区分: | |||
| - 启智集群单数据集**加载模型**的训练示例请参考示例中[train_gpu.py](../train_gpu.py)的代码注释 | |||
| - 启智集群中数据集使用方式: | |||
| 多数据集时MNISTDataset_torch.zip的使用方式是:数据集位于/dataset/MNISTDataset_torch/下 | |||
| ## 1 概述 | |||
| - 本项目以#LeNet5-MNIST-PyTorch为例,简要介绍如何在启智AI协同平台上使用Pytorch完成训练任务,包括单数据集的训练,多数据集的训练,智算网络的训练,旨在为AI开发者提供启智训练示例。 | |||
| - 用户可以直接使用本项目提供的数据集和代码文件创建自己的训练任务。 | |||
| ## 2 准备工作 | |||
| - 启智平台使用准备,本项目需要用户创建启智平台账户,克隆代码到自己的账户,上传数据集,具体操作方法可以通过访问[OpenI_Learning](https://git.openi.org.cn/zeizei/OpenI_Learning)项目学习小白训练营系列课程进行学习。 | |||
| ### 2.1 数据准备 | |||
| #### 数据集获取 | |||
| - 如果你需要试运行本示例,则无需再次上传数据集,因为本示例中的数据集MnistDataset_torch.zip已经设置为公开数据集,可以直接引用,数据集也可从本项目的数据集目录中下载并查看数据结构,[MNISTDataset_torch.zip数据集下载](https://git.openi.org.cn/OpenIOSSG/MNIST_PytorchExample_GPU/datasets?type=0),[mnist_epoch1_0.73.pkl.zip数据集下载](https://git.openi.org.cn/OpenIOSSG/MNIST_PytorchExample_GPU/datasets?type=0)。 | |||
| - 数据文件说明 | |||
| - MNISTData数据集是由10类28∗28的灰度图片组成,训练数据集包含60000张图片,测试数据集包含10000张图片。 | |||
| - 数据集压缩包的目录结构如下: | |||
| > MNISTDataset_torch.zip | |||
| > ├── test | |||
| > │ └── MNIST | |||
| > │ │── raw | |||
| > │ │ ├── t10k-images-idx3-ubyte | |||
| > │ │ └── t10k-labels-idx1-ubyte | |||
| > │ │ ├── train-images-idx3-ubyte | |||
| > │ │ └── train-labels-idx1-ubyte | |||
| > │ └── processed | |||
| > │ ├── test.pt | |||
| > │ └── training.pt | |||
| > └── train | |||
| > └── MNIST | |||
| > │── raw | |||
| > │ ├── t10k-images-idx3-ubyte | |||
| > │ └── t10k-labels-idx1-ubyte | |||
| > │ ├── train-images-idx3-ubyte | |||
| > │ └── train-labels-idx1-ubyte | |||
| > └── processed | |||
| > ├── test.pt | |||
| > └── training.pt | |||
| > | |||
| > mnist_epoch1_0.73.pkl.zip | |||
| > ├── mnist_epoch1_0.73.pkl | |||
| > | |||
| #### 数据集上传 | |||
| 使用GPU进行训练,需要在GPU芯片上运行,所以上传的数据集需要传到GPU界面。(此步骤在本示例中不需要,可直接选择公开数据集MNISTDataset_torch.zip) | |||
| ### 2.2 执行脚本准备 | |||
| #### 示例代码 | |||
| - 示例代码可从本仓库中下载,[代码下载](https://git.openi.org.cn/OpenIOSSG/MNIST_PytorchExample_GPU) | |||
| - 代码文件说明 | |||
| - [train_gpu.py](../train_gpu.py),用于单数据集训练的脚本文件。具体说明请参考[train_gpu.py](../train_gpu.py) | |||
| - [model.py](../model.py),使用的训练网络,在单数据集训练,多数据集训练,智算网络训练中使用到。 | |||
| ## 3 创建训练任务 | |||
| 准备好数据和执行脚本以后,需要创建训练任务将Pytorch脚本运行。首次使用的用户可参考本示例代码。 | |||
| ### 训练界面示例 | |||
| 由于A100的适配性问题,A100需要使用cuda11以上的cuda版本,目前平台已提供基于A100的cuda基础镜像,只需要选择对应的公共镜像: | |||
|  | |||
| 训练界面参数参考如下: | |||
|  | |||
| 表1 创建训练作业界面参数说明 | |||
| | 参数名称 | 说明 | | |||
| | -------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | |||
| | 计算资源 | 选择CPU/GPU | | |||
| | 代码分支 | 选择仓库代码中要使用的代码分支,默认可选择master分支 | | |||
| | 镜像 | 镜像选择已在调试环境中调试好的镜像,目前版本请选择基础镜像:平台提供基于A100的cuda基础镜像,如dockerhub.pcl.ac.cn:5000/user-images/openi:cuda111_python37_pytorch191 | | |||
| | 启动文件 | 启动文件选择代码目录下的启动脚本train.py | | |||
| | 数据集 | 数据集选择已上传到启智平台的公共数据集MnistDataset_torch.zip | | |||
| | 运行参数 | 增加运行参数可以向脚本中其他参数传值,如epoch_size | | |||
| | 资源规格 | 规格选择含有GPU个数的规格 | | |||
| ## 4 查看运行结果 | |||
| ### 4.1 在训练作业界面可以查看运行日志 | |||
| 目前训练任务的日志只能在代码中print输出,参考示例train.py代码相关print | |||
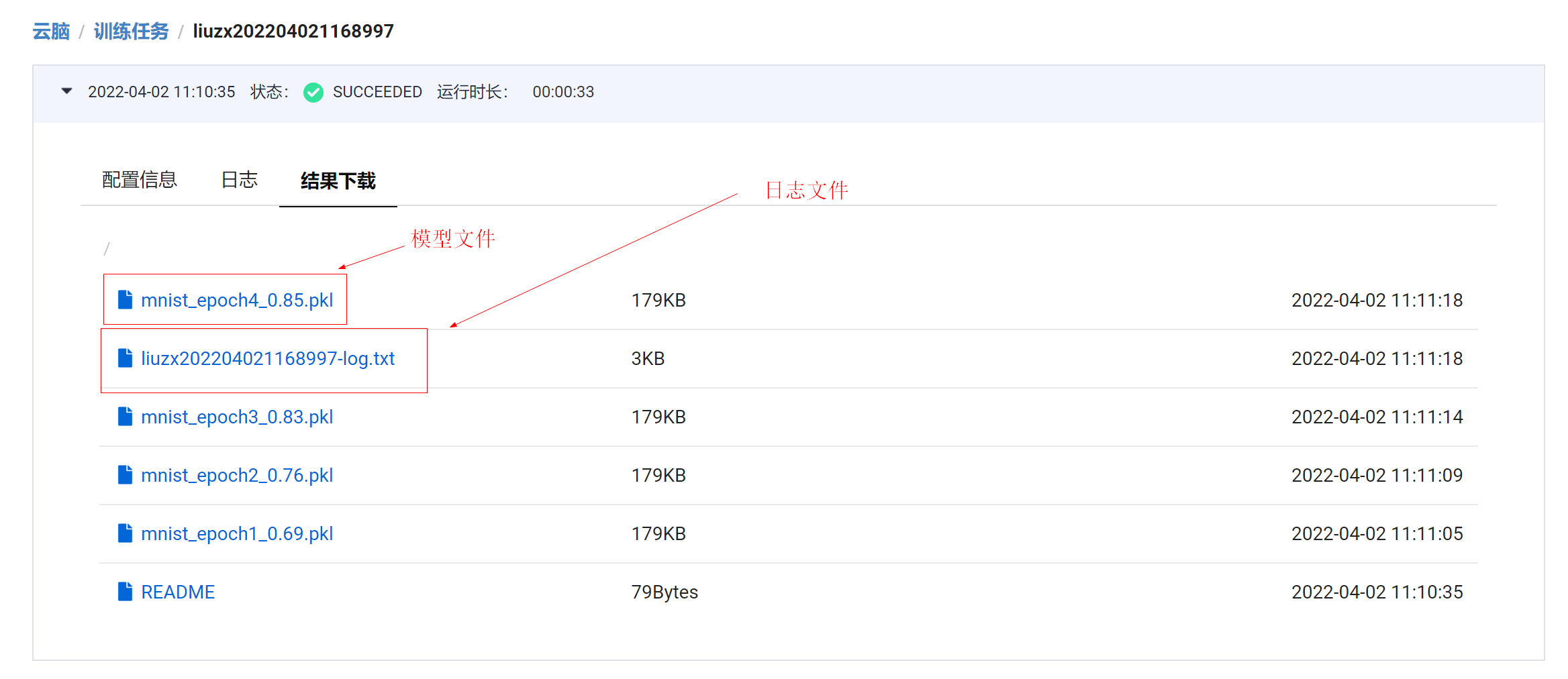
| ### 4.2 训练结束后可以下载模型文件 | |||
|  | |||
| ## 对于示例代码有任何问题,欢迎在本项目中提issue。 | |||
BIN
gpu_mnist_example/Example_Picture/结果下载.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 2336 | Height: 1012 | Size: 94 kB |
BIN
gpu_mnist_example/Example_Picture/适用A100的基础镜像.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1499 | Height: 676 | Size: 111 kB |
+ 54
- 0
gpu_mnist_example/README.md
View File
| @@ -0,0 +1,54 @@ | |||
| # 如何在启智平台上进行模型训练—GPU_手写数字识别示例 | |||
| ## 1.启智集群和智算集群的GPU训练样例 | |||
| ###### 启智集群的示例代码: | |||
| - 训练示例请参考示例中[train_npu.py](./train_npu.py)的代码注释 | |||
| ## 2. 在openi上获取数据集,预训练模型,输出路径 | |||
| 安装openi包 | |||
| ``` | |||
| pip install -U openi | |||
| ``` | |||
| 使用openi包 | |||
| ``` | |||
| #导入包 | |||
| from openi.context import prepare, upload_openi | |||
| #初始化导入数据集和预训练模型到容器内 | |||
| openi_context = prepare() | |||
| #获取数据集路径,预训练模型路径,输出路径 | |||
| dataset_path = openi_context.dataset_path | |||
| pretrain_model_path = openi_context.pretrain_model_path | |||
| output_path = openi_context.output_path | |||
| #回传结果到openi | |||
| upload_openi() | |||
| ``` | |||
| ## 3.[创建GPU训练示例任务界面教程](./Example_Picture/快速创建GPU训练任务.md) | |||
| ## 4.FAQ | |||
| ### 4.1 关于启智平台公共库[openi](https://openi.pcl.ac.cn/OpenIOSSG/openi-pypi): | |||
| 主要使用的方法有以下几个: | |||
| ``` | |||
| prepare 准备数据集,模型,输出路径 | |||
| upload_openi 将训练镜像的输出结果拷贝回启智平台 | |||
| obs_copy_file 通过mox拷贝文件 | |||
| obs_copy_folder 通过mox拷贝文件夹 | |||
| ``` | |||
| ### 4.2 解决参数报错问题: | |||
| 请在代码中加入 `args, unknown = parser.parse_known_args()`,可忽略掉 `--ckpt_url`,`--data_url`, `--multi_date_url`等参数报错问题 | |||
| ## 对于示例代码有任何问题,欢迎在本项目中提issue。 | |||
+ 35
- 0
gpu_mnist_example/model.py
View File
| @@ -0,0 +1,35 @@ | |||
| from torch.nn import Module | |||
| from torch import nn | |||
| class Model(Module): | |||
| def __init__(self): | |||
| super(Model, self).__init__() | |||
| self.conv1 = nn.Conv2d(1, 6, 5) | |||
| self.relu1 = nn.ReLU() | |||
| self.pool1 = nn.MaxPool2d(2) | |||
| self.conv2 = nn.Conv2d(6, 16, 5) | |||
| self.relu2 = nn.ReLU() | |||
| self.pool2 = nn.MaxPool2d(2) | |||
| self.fc1 = nn.Linear(256, 120) | |||
| self.relu3 = nn.ReLU() | |||
| self.fc2 = nn.Linear(120, 84) | |||
| self.relu4 = nn.ReLU() | |||
| self.fc3 = nn.Linear(84, 10) | |||
| self.relu5 = nn.ReLU() | |||
| def forward(self, x): | |||
| y = self.conv1(x) | |||
| y = self.relu1(y) | |||
| y = self.pool1(y) | |||
| y = self.conv2(y) | |||
| y = self.relu2(y) | |||
| y = self.pool2(y) | |||
| y = y.view(y.shape[0], -1) | |||
| y = self.fc1(y) | |||
| y = self.relu3(y) | |||
| y = self.fc2(y) | |||
| y = self.relu4(y) | |||
| y = self.fc3(y) | |||
| y = self.relu5(y) | |||
| return y | |||
+ 115
- 0
gpu_mnist_example/train_gpu.py
View File
| @@ -0,0 +1,115 @@ | |||
| #!/usr/bin/python | |||
| #coding=utf-8 | |||
| ''' | |||
| If there are Chinese comments in the code,please add at the beginning: | |||
| #!/usr/bin/python | |||
| #coding=utf-8 | |||
| 1,The dataset structure of the single-dataset in this example | |||
| MnistDataset_torch.zip | |||
| ├── test | |||
| └── train | |||
| ''' | |||
| from model import Model | |||
| import numpy as np | |||
| import torch | |||
| from torchvision.datasets import mnist | |||
| from torch.nn import CrossEntropyLoss | |||
| from torch.optim import SGD | |||
| from torch.utils.data import DataLoader | |||
| from torchvision.transforms import ToTensor | |||
| import argparse | |||
| import os | |||
| #导入openi包 | |||
| from openi.context import prepare, upload_openi | |||
| # Training settings | |||
| parser = argparse.ArgumentParser(description='PyTorch MNIST Example') | |||
| parser.add_argument('--epoch_size', type=int, default=10, help='how much epoch to train') | |||
| parser.add_argument('--batch_size', type=int, default=256, help='how much batch_size in epoch') | |||
| # 参数声明 | |||
| WORKERS = 0 # dataloder线程数 | |||
| device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||
| model = Model().to(device) | |||
| optimizer = SGD(model.parameters(), lr=1e-1) | |||
| cost = CrossEntropyLoss() | |||
| # 模型训练 | |||
| def train(model, train_loader, epoch): | |||
| model.train() | |||
| train_loss = 0 | |||
| for i, data in enumerate(train_loader, 0): | |||
| x, y = data | |||
| x = x.to(device) | |||
| y = y.to(device) | |||
| optimizer.zero_grad() | |||
| y_hat = model(x) | |||
| loss = cost(y_hat, y) | |||
| loss.backward() | |||
| optimizer.step() | |||
| train_loss += loss | |||
| loss_mean = train_loss / (i+1) | |||
| print('Train Epoch: {}\t Loss: {:.6f}'.format(epoch, loss_mean.item())) | |||
| # 模型测试 | |||
| def test(model, test_loader, test_data): | |||
| model.eval() | |||
| test_loss = 0 | |||
| correct = 0 | |||
| with torch.no_grad(): | |||
| for i, data in enumerate(test_loader, 0): | |||
| x, y = data | |||
| x = x.to(device) | |||
| y = y.to(device) | |||
| optimizer.zero_grad() | |||
| y_hat = model(x) | |||
| test_loss += cost(y_hat, y).item() | |||
| pred = y_hat.max(1, keepdim=True)[1] | |||
| correct += pred.eq(y.view_as(pred)).sum().item() | |||
| test_loss /= (i+1) | |||
| print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( | |||
| test_loss, correct, len(test_data), 100. * correct / len(test_data))) | |||
| if __name__ == '__main__': | |||
| args, unknown = parser.parse_known_args() | |||
| #初始化导入数据集和预训练模型到容器内 | |||
| openi_context = prepare() | |||
| #获取数据集路径,预训练模型路径,输出路径 | |||
| dataset_path = openi_context.dataset_path | |||
| pretrain_model_path = openi_context.pretrain_model_path | |||
| output_path = openi_context.output_path | |||
| #log output | |||
| print('cuda is available:{}'.format(torch.cuda.is_available())) | |||
| device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||
| batch_size = args.batch_size | |||
| epochs = args.epoch_size | |||
| train_dataset = mnist.MNIST(root=os.path.join(dataset_path, "train"), train=True, transform=ToTensor(),download=False) | |||
| test_dataset = mnist.MNIST(root=os.path.join(dataset_path, "test"), train=False, transform=ToTensor(),download=False) | |||
| train_loader = DataLoader(train_dataset, batch_size=batch_size) | |||
| test_loader = DataLoader(test_dataset, batch_size=batch_size) | |||
| #如果有保存的模型,则加载模型,并在其基础上继续训练 | |||
| if os.path.exists(os.path.join(pretrain_model_path, "mnist_epoch1_0.76.pkl")): | |||
| checkpoint = torch.load(os.path.join(pretrain_model_path, "mnist_epoch1_0.76.pkl")) | |||
| model.load_state_dict(checkpoint['model']) | |||
| optimizer.load_state_dict(checkpoint['optimizer']) | |||
| start_epoch = checkpoint['epoch'] | |||
| print('加载 epoch {} 权重成功!'.format(start_epoch)) | |||
| else: | |||
| start_epoch = 0 | |||
| print('无保存模型,将从头开始训练!') | |||
| for epoch in range(start_epoch+1, epochs): | |||
| train(model, train_loader, epoch) | |||
| test(model, test_loader, test_dataset) | |||
| # 保存模型 | |||
| state = {'model':model.state_dict(), 'optimizer':optimizer.state_dict(), 'epoch':epoch} | |||
| torch.save(state, '{}/mnist_epoch{}.pkl'.format(output_path, epoch)) | |||
+ 109
- 0
npu_mnist_example/Example_Picture/快速创建NPU训练任务.md
View File
| @@ -0,0 +1,109 @@ | |||
| # 如何在启智平台上进行模型训练 - NPU版本 | |||
| ## 1 概述 | |||
| - 本项目以LeNet-MNIST为例,简要介绍如何在启智AI协同平台上使用MindSpore完成训练任务,并提供单数据集的训练,多数据集的训练,智算网络的训练,单数据集推理等训练代码示例,旨在为AI开发者提供启智npu训练示例。对于示例代码有任何问题,欢迎在本项目中提issue。 | |||
| - 用户可以直接使用本项目提供的数据集和代码文件创建自己的训练任务。 | |||
| - 启智平台对接ModelArts和OBS,将数据集,代码,训练资源池等整合在启智AI协同平台上供开发者使用。 | |||
| - ModelArts是华为云提供的面向开发者的一站式AI开发平台,集成了昇腾AI处理器资源池,用户可以在ModelArts下体验MindSpore。 | |||
| - OBS是华为云提供的存储方式。 | |||
| ## 2 准备工作 | |||
| - 启智平台使用准备,本项目需要用户创建启智平台账户,克隆代码到自己的账户,上传数据集,具体操作方法可以通过访问[OpenI_Learning](https://git.openi.org.cn/zeizei/OpenI_Learning)项目学习小白训练营系列课程进行学习。 | |||
| ### 2.1 数据准备 | |||
| #### 数据集下载 | |||
| - 数据集可从本项目的数据集目录中下载,[数据集下载](https://git.openi.org.cn/OpenIOSSG/MNIST_Example/datasets?type=1) | |||
| - 数据文件说明 | |||
| - MNISTData数据集是由10类28∗28的灰度图片组成,训练数据集包含60000张图片,测试数据集包含10000张图片。 | |||
| - 数据集压缩包的目录结构如下: | |||
| > MNIST_Data.zip | |||
| > ├── test | |||
| > │ ├── t10k-images-idx3-ubyte | |||
| > │ └── t10k-labels-idx1-ubyte | |||
| > └── train | |||
| > ├── train-images-idx3-ubyte | |||
| > └── train-labels-idx1-ubyte | |||
| > | |||
| > checkpoint_lenet-1_1875.zip | |||
| > ├── checkpoint_lenet-1_1875.ckpt | |||
| > | |||
| #### 数据集上传 | |||
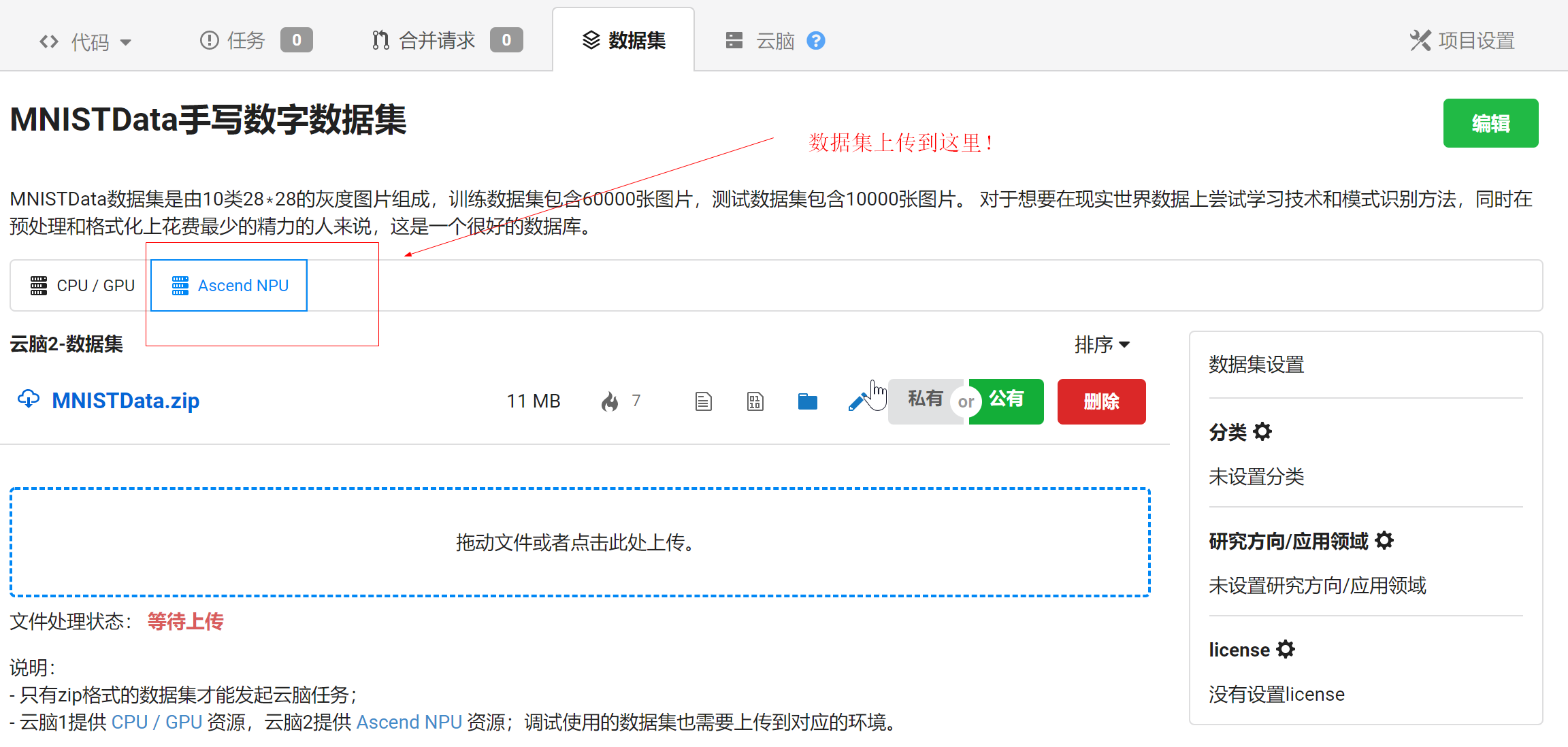
| - 由于本示例使用的是Mindspore开发,需要在NPU芯片运行,所以上传的数据集需要传到NPU界面。【注意:如果你需要试运行本示例,则无需再次上传数据集,因为本示例中的数据集MNIST_Example已经设置为公开数据集,可以直接引用或点赞收藏后使用】 | |||
| - 如下所示: | |||
| -  | |||
| #### imagenet-1k | |||
| - 平台已经将imagenet-1k挂载到了训练镜像中,可在训练脚本中直接读取,具体用法请参考上述示例代码。 | |||
| - imagenet-1k在训练镜像中的绝对路径: | |||
| ``` | |||
| . | |||
| └── cache/ | |||
| ├── ascend | |||
| ├── outputs | |||
| ├── user-job-dir | |||
| └── sfs/ | |||
| └── data/ | |||
| └── imagenet/ | |||
| ├── train/ | |||
| │ └── n01440764/ | |||
| │ └── n01440764_11063.JPEG | |||
| └── val/ | |||
| └── n01440764/ | |||
| └── ILSVRC2012_val_00011993.JPEG | |||
| ``` | |||
| ### 2.2 执行脚本准备 | |||
| #### 示例代码 | |||
| - 示例代码可从本仓库中下载,[代码下载](https://git.openi.org.cn/OpenIOSSG/MNIST_Example) | |||
| - 代码文件说明 | |||
| - [train_npu.py](../train_npu.py),启智集群单数据集训练的脚本文件,包括将数据集从obs拷贝到训练镜像中、指定迭代次数、把训练后的模型数据拷贝回obs等。具体说明请参考[train_npu.py](../train_npu.py)的代码注释 | |||
| - [config.py](../config.py),网络配置信息,在单数据集训练,多数据集训练,智算网络训练等训练脚本中会使用到。 | |||
| - [dataset.py](../dataset.py),对原始数据集进行预处理,产生可用于网络训练的数据集,在单数据集的训练,多数据集的训练,智算网络的训练等训练脚本中会使用到。 | |||
| - [lenet.py](../lenet.py),使用的训练网络,在单数据集训练,多数据集训练,智算网络训练等训练脚本中会使用到。 | |||
| - [dataset_distributes.py](../dataset_distributes.py),对原始数据集进行预处理,产生可用于单机多卡训练的数据集。 | |||
| ## 3 创建训练任务 | |||
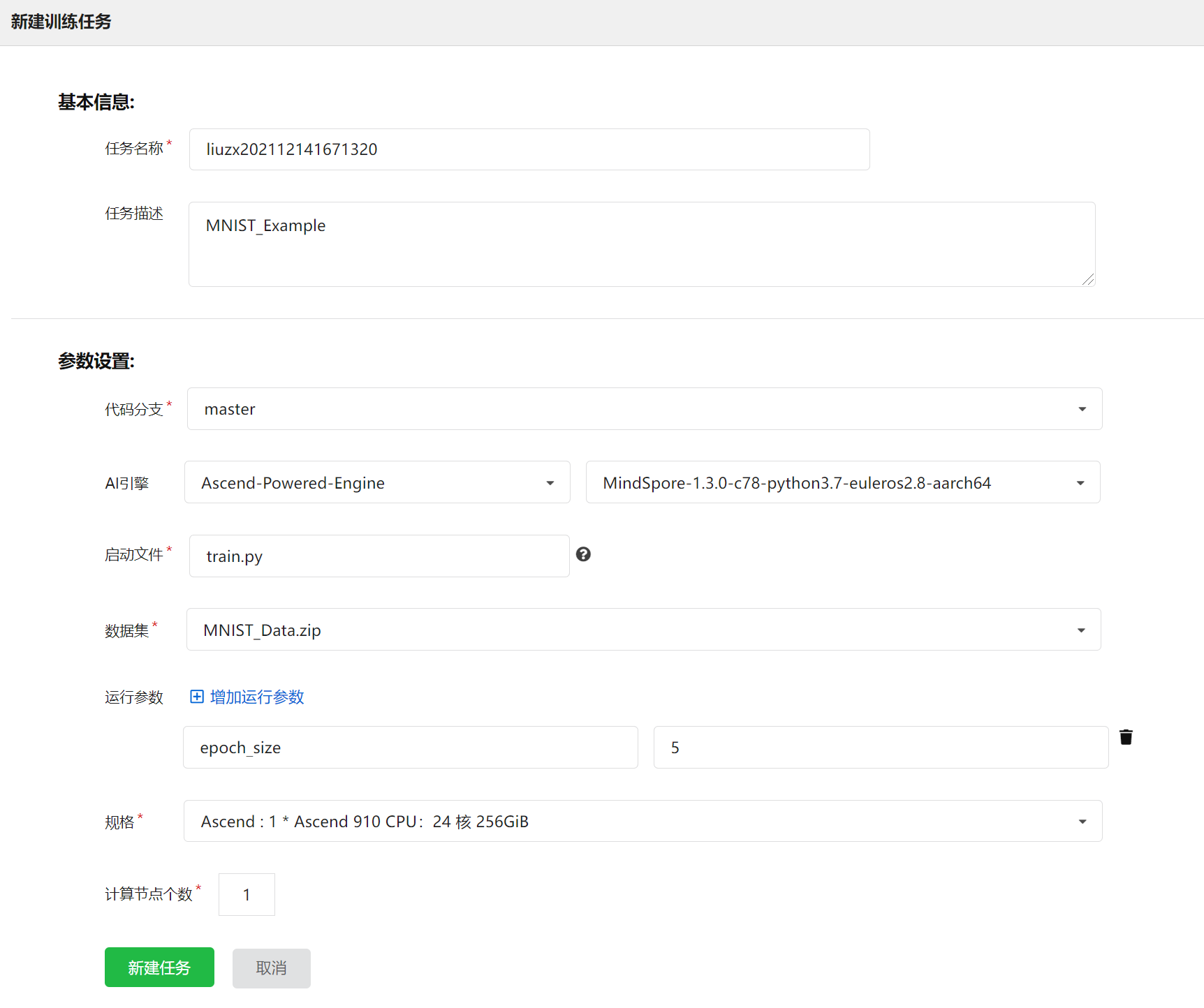
| - 准备好数据和执行脚本以后,需要创建训练任务将MindSpore脚本真正运行起来。首次使用的用户可参考本示例代码。 | |||
| ### 使用MindSpore作为训练框架创建训练作业,界面截图如下图所示。 | |||
|  | |||
| 表1 创建训练作业界面参数说明 | |||
| | 参数名称 | 说明 | | |||
| | -------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | |||
| | 代码分支 | 选择仓库代码中要使用的代码分支,默认可选择master分支。 | | |||
| | AI引擎 | AI引擎选择[Ascend-Powered-Engine]和所需的MindSpore版本(本示例图片为 [Mindspore-1.3.0-python3.7-aarch64],请注意使用与所选版本对应的脚本)。 | | |||
| | 启动文件 | 启动文件选择代码目录下的启动脚本。 | | |||
| | 数据集 | 数据集选择已上传到启智平台的数据集。 | | |||
| | 运行参数 | 单数据集数据存储位置和训练输出位置分别对应运行参数data_url和train_url,注意多数据集需要增加参数multi_data_url并在代码中声明,选择增加运行参数可以向脚本中其他参数传值,如epoch_size。在这里只需填入其他参数传值,data_url和train_url已默认加入运行参数,用户无需重复指定,只需在代码中指定。 | | |||
| | 资源池 | 规格选择[Ascend: 1 * Ascend 910 CPU:24 核 256GiB],表示单机单卡 | | |||
| <!-- 注:若要在启智平台上使用CPU,需要在启智平台训练界面上加上运行参数device_target=CPU,否则默认是Ascend,如下图所示 | |||
|  --> | |||
| ## 4 查看运行结果 | |||
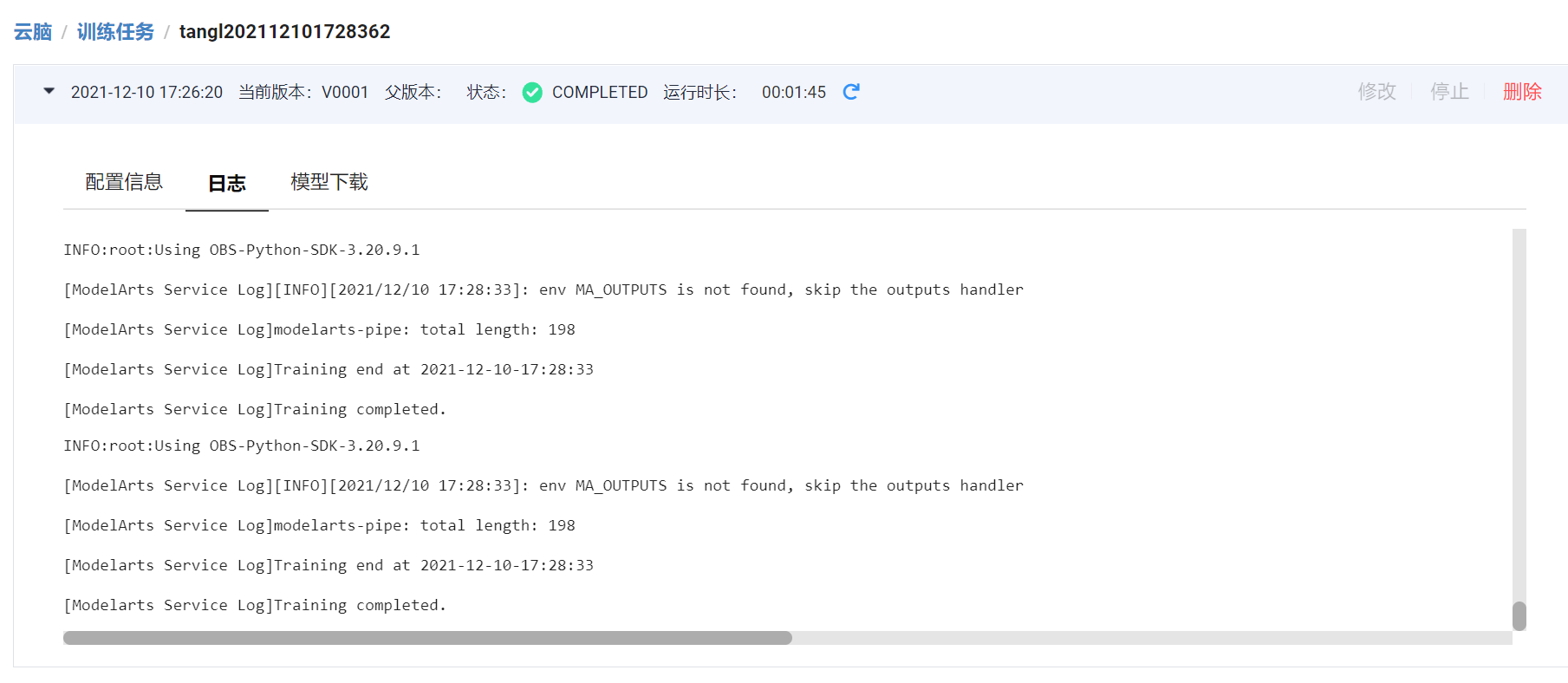
| ### 4.1 在训练作业界面可以查看运行日志 | |||
|  | |||
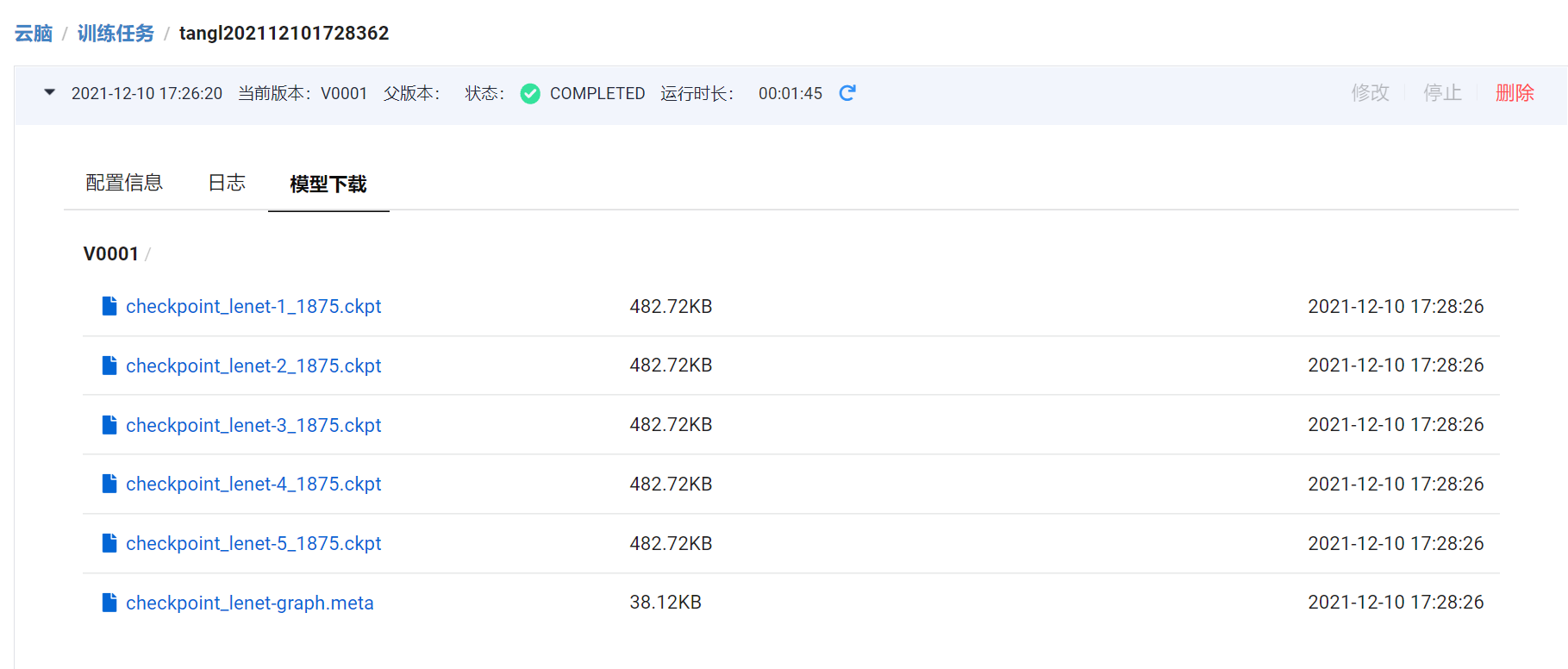
| ### 4.2 训练结束后可以下载模型文件 | |||
|  | |||
| ## 对于示例代码有任何问题,欢迎在本项目中提issue。 | |||
BIN
npu_mnist_example/Example_Picture/数据集上传位置.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 2304 | Height: 1098 | Size: 189 kB |
BIN
npu_mnist_example/Example_Picture/新建训练任务页面.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1724 | Height: 1444 | Size: 73 kB |
BIN
npu_mnist_example/Example_Picture/查看日志页面.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1809 | Height: 788 | Size: 67 kB |
BIN
npu_mnist_example/Example_Picture/模型下载页面.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1819 | Height: 776 | Size: 73 kB |
BIN
npu_mnist_example/Example_Picture/运行参数界面.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 2146 | Height: 1294 | Size: 108 kB |
+ 74
- 0
npu_mnist_example/README.md
View File
| @@ -0,0 +1,74 @@ | |||
| # 如何在启智平台上进行模型训练—NPU_手写数字识别示例 | |||
| ## 1.启智集群和智算集群的NPU训练样例 | |||
| ###### 启智集群的示例代码: | |||
| - 训练示例请参考示例中[train_npu.py](./train_npu.py)的代码注释 | |||
| - 启智集群训练任务已经将ImageNet-1k数据集挂载到训练镜像,具体使用方法请参考示例中[read_imagenet.py](./read_imagenet.py)的代码注释 | |||
| - 继续训练功能示例代码请参考[train_continue.py](./train_continue.py) ,启智与智算的用法相同 | |||
| ## 2. 在openi上获取数据集,预训练模型,输出路径 | |||
| 安装openi包 | |||
| ``` | |||
| pip install -U openi | |||
| ``` | |||
| 使用openi包 | |||
| ``` | |||
| #导入包 | |||
| from openi.context import prepare, upload_openi | |||
| #初始化导入数据集和预训练模型到容器内 | |||
| openi_context = prepare() | |||
| #获取数据集路径,预训练模型路径,输出路径 | |||
| dataset_path = openi_context.dataset_path | |||
| pretrain_model_path = openi_context.pretrain_model_path | |||
| output_path = openi_context.output_path | |||
| #回传结果到openi | |||
| upload_openi() | |||
| ``` | |||
| ## 3.[创建NPU训练示例任务界面教程](./Example_Picture/快速创建NPU训练任务.md) | |||
| ## 4.FAQ | |||
| ### 4.1 关于启智平台公共库[openi](https://openi.pcl.ac.cn/OpenIOSSG/openi-pypi): | |||
| 主要使用的方法有以下几个: | |||
| ``` | |||
| prepare 准备数据集,模型,输出路径 | |||
| upload_openi 将训练镜像的输出结果拷贝回启智平台 | |||
| obs_copy_file 通过mox拷贝文件 | |||
| obs_copy_folder 通过mox拷贝文件夹 | |||
| ``` | |||
| ### 4.2 解决参数报错问题: | |||
| 请在代码中加入 `args, unknown = parser.parse_known_args()`,可忽略掉 `--ckpt_url`,`--data_url`, `--multi_date_url`等参数报错问题 | |||
| ### 4.3 多卡训练任务如何只让数据集只拷贝一次 | |||
| 使用缓存文件和local_rank%8作为判断,若第0卡拷贝完成,则其它卡不拷贝,并在第0卡拷贝数据完成后才执行之后的代码 | |||
| ``` | |||
| if local_rank%8==0: | |||
| 这里省略下载数据的代码... | |||
| f = open("/cache/download_input.txt", 'w') | |||
| f.close() | |||
| try: | |||
| if os.path.exists("/cache/download_input.txt"): | |||
| print("download_input succeed") | |||
| except Exception as e: | |||
| print("download_input failed") | |||
| while not os.path.exists("/cache/download_input.txt"): | |||
| time.sleep(1) | |||
| ``` | |||
| ## 对于示例代码有任何问题,欢迎在本项目中提issue。 | |||
+ 33
- 0
npu_mnist_example/config.py
View File
| @@ -0,0 +1,33 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| network config setting, will be used in train.py | |||
| """ | |||
| from easydict import EasyDict as edict | |||
| mnist_cfg = edict({ | |||
| 'num_classes': 10, | |||
| 'lr': 0.01, | |||
| 'momentum': 0.9, | |||
| 'epoch_size': 10, | |||
| 'batch_size': 32, | |||
| 'buffer_size': 1000, | |||
| 'image_height': 32, | |||
| 'image_width': 32, | |||
| 'save_checkpoint_steps': 1875, | |||
| 'keep_checkpoint_max': 150, | |||
| 'air_name': "lenet", | |||
| }) | |||
+ 60
- 0
npu_mnist_example/dataset.py
View File
| @@ -0,0 +1,60 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| Produce the dataset | |||
| """ | |||
| import mindspore.dataset as ds | |||
| import mindspore.dataset.vision.c_transforms as CV | |||
| import mindspore.dataset.transforms.c_transforms as C | |||
| from mindspore.dataset.vision import Inter | |||
| from mindspore.common import dtype as mstype | |||
| def create_dataset(data_path, batch_size=32, repeat_size=1, | |||
| num_parallel_workers=1): | |||
| """ | |||
| create dataset for train or test | |||
| """ | |||
| # define dataset | |||
| mnist_ds = ds.MnistDataset(data_path) | |||
| resize_height, resize_width = 32, 32 | |||
| rescale = 1.0 / 255.0 | |||
| shift = 0.0 | |||
| rescale_nml = 1 / 0.3081 | |||
| shift_nml = -1 * 0.1307 / 0.3081 | |||
| # define map operations | |||
| resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR) # Bilinear mode | |||
| rescale_nml_op = CV.Rescale(rescale_nml, shift_nml) | |||
| rescale_op = CV.Rescale(rescale, shift) | |||
| hwc2chw_op = CV.HWC2CHW() | |||
| type_cast_op = C.TypeCast(mstype.int32) | |||
| # apply map operations on images | |||
| mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers) | |||
| mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers) | |||
| mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers) | |||
| mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers) | |||
| mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers) | |||
| # apply DatasetOps | |||
| buffer_size = 10000 | |||
| mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size) # 10000 as in LeNet train script | |||
| mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True) | |||
| mnist_ds = mnist_ds.repeat(repeat_size) | |||
| return mnist_ds | |||
+ 54
- 0
npu_mnist_example/dataset_distributed.py
View File
| @@ -0,0 +1,54 @@ | |||
| """ | |||
| Produce the dataset: | |||
| 与单机不同的是,在数据集接口需要传入num_shards和shard_id参数,分别对应卡的数量和逻辑序号,建议通过HCCL接口获取: | |||
| get_rank:获取当前设备在集群中的ID。 | |||
| get_group_size:获取集群数量。 | |||
| """ | |||
| import mindspore.dataset as ds | |||
| import mindspore.dataset.vision.c_transforms as CV | |||
| import mindspore.dataset.transforms.c_transforms as C | |||
| from mindspore.dataset.vision import Inter | |||
| from mindspore.common import dtype as mstype | |||
| from mindspore.communication.management import get_rank, get_group_size | |||
| def create_dataset_parallel(data_path, batch_size=32, repeat_size=1, | |||
| num_parallel_workers=1, shard_id=0, num_shards=8): | |||
| """ | |||
| create dataset for train or test | |||
| """ | |||
| resize_height, resize_width = 32, 32 | |||
| rescale = 1.0 / 255.0 | |||
| shift = 0.0 | |||
| rescale_nml = 1 / 0.3081 | |||
| shift_nml = -1 * 0.1307 / 0.3081 | |||
| # get shard_id and num_shards.Get the ID of the current device in the cluster And Get the number of clusters. | |||
| shard_id = get_rank() | |||
| num_shards = get_group_size() | |||
| # define dataset | |||
| mnist_ds = ds.MnistDataset(data_path, num_shards=num_shards, shard_id=shard_id) | |||
| # define map operations | |||
| resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR) # Bilinear mode | |||
| rescale_nml_op = CV.Rescale(rescale_nml, shift_nml) | |||
| rescale_op = CV.Rescale(rescale, shift) | |||
| hwc2chw_op = CV.HWC2CHW() | |||
| type_cast_op = C.TypeCast(mstype.int32) | |||
| # apply map operations on images | |||
| mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers) | |||
| mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers) | |||
| mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers) | |||
| mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers) | |||
| mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers) | |||
| # apply DatasetOps | |||
| buffer_size = 10000 | |||
| mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size) # 10000 as in LeNet train script | |||
| mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True) | |||
| mnist_ds = mnist_ds.repeat(repeat_size) | |||
| return mnist_ds | |||
+ 60
- 0
npu_mnist_example/lenet.py
View File
| @@ -0,0 +1,60 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """LeNet.""" | |||
| import mindspore.nn as nn | |||
| from mindspore.common.initializer import Normal | |||
| class LeNet5(nn.Cell): | |||
| """ | |||
| Lenet network | |||
| Args: | |||
| num_class (int): Number of classes. Default: 10. | |||
| num_channel (int): Number of channels. Default: 1. | |||
| Returns: | |||
| Tensor, output tensor | |||
| Examples: | |||
| >>> LeNet(num_class=10) | |||
| """ | |||
| def __init__(self, num_class=10, num_channel=1, include_top=True): | |||
| super(LeNet5, self).__init__() | |||
| self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid') | |||
| self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid') | |||
| self.relu = nn.ReLU() | |||
| self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) | |||
| self.include_top = include_top | |||
| if self.include_top: | |||
| self.flatten = nn.Flatten() | |||
| self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02)) | |||
| self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02)) | |||
| self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02)) | |||
| def construct(self, x): | |||
| x = self.conv1(x) | |||
| x = self.relu(x) | |||
| x = self.max_pool2d(x) | |||
| x = self.conv2(x) | |||
| x = self.relu(x) | |||
| x = self.max_pool2d(x) | |||
| if not self.include_top: | |||
| return x | |||
| x = self.flatten(x) | |||
| x = self.relu(self.fc1(x)) | |||
| x = self.relu(self.fc2(x)) | |||
| x = self.fc3(x) | |||
| return x | |||
+ 72
- 0
npu_mnist_example/read_imagenet.py
View File
| @@ -0,0 +1,72 @@ | |||
| ''' | |||
| imagnet-1k 数据集已通过磁盘挂载的方式挂载在训练镜像中, | |||
| 用户可参考下列示例代码读取直接使用。 | |||
| 挂载路径为 | |||
| . | |||
| └── cache/ | |||
| ├── ascend | |||
| ├── outputs | |||
| ├── user-job-dir | |||
| └── sfs/ | |||
| └── data/ | |||
| └── imagenet/ | |||
| ├── train/ | |||
| │ └── n01440764/ | |||
| │ └── n01440764_11063.JPEG | |||
| └── val/ | |||
| └── n01440764/ | |||
| └── ILSVRC2012_val_00011993.JPEG | |||
| mindspore.dataset.ImageFolderDataset | |||
| - 读取imagenet-1k数据,同一文件夹下的数据为同一类class。 | |||
| mindspore.dataset.vision.c_transforms | |||
| - 数据加载和预处理。 | |||
| mindspore.dataset.ImageFolderDataset | |||
| - map:给定一组数据增强列表,按顺序将数据增强作用在数据集对象上。 | |||
| - batch:将数据集中连续 batch_size 条数据合并为一个批处理数据。 | |||
| - to_json:将数据处理管道序列化为JSON字符串,如果提供了文件名,则转储到文件中。 | |||
| ''' | |||
| import os | |||
| import argparse | |||
| import moxing as mox | |||
| import mindspore as ms | |||
| from mindspore.dataset import ImageFolderDataset | |||
| import mindspore.dataset.vision.c_transforms as transforms | |||
| from openi.context import upload_openi | |||
| parser = argparse.ArgumentParser(description='Read big dataset ImageNet Example') | |||
| parser.add_argument('--train_url', | |||
| help='output folder to save/load', | |||
| default= '/cache/output/') | |||
| if __name__ == "__main__": | |||
| args, unknown = parser.parse_known_args() | |||
| data_path = '/cache/sfs/data/imagenet/' | |||
| modelart_output = '/cache/output' | |||
| if not os.path.exists(modelart_output): | |||
| os.makedirs(modelart_output) | |||
| mean = [0.485 * 255, 0.456 * 255, 0.406 * 255] | |||
| std = [0.229 * 255, 0.224 * 255, 0.225 * 255] | |||
| dataset_train = ImageFolderDataset(os.path.join(data_path, "train"), | |||
| shuffle=True) | |||
| trans_train = [ | |||
| transforms.RandomCropDecodeResize(size=224, | |||
| scale=(0.08, 1.0), | |||
| ratio=(0.75, 1.333)), | |||
| transforms.RandomHorizontalFlip(prob=0.5), | |||
| transforms.Normalize(mean=mean, std=std), | |||
| transforms.HWC2CHW() | |||
| ] | |||
| dataset_train = dataset_train.map(operations=trans_train, | |||
| input_columns=["image"]) | |||
| dataset_train = dataset_train.batch(batch_size=16, drop_remainder=True) | |||
| data_info = dataset_train.to_json(filename= modelart_output + '/data_info.json') | |||
| print(data_info) | |||
| upload_openi() | |||
+ 122
- 0
npu_mnist_example/train_continue.py
View File
| @@ -0,0 +1,122 @@ | |||
| ##################################################################################################### | |||
| # 继续训练功能:修改训练任务时,若勾选复用上次结果,则可在新训练任务的输出路径中读取到上次结果 | |||
| # | |||
| # 示例用法 | |||
| # - 增加两个训练参数 | |||
| # 'ckpt_save_name' 此次任务的输出文件名,用于保存此次训练的模型文件名称(不带后缀) | |||
| # 'ckpt_load_name' 上一次任务的输出文件名,用于加载上一次输出的模型文件名称(不带后缀),首次训练默认为空,则不读取任何文件 | |||
| # - 训练代码中判断 'ckpt_load_name' 是否为空,若不为空,则为继续训练任务 | |||
| ##################################################################################################### | |||
| import os | |||
| import argparse | |||
| from config import mnist_cfg as cfg | |||
| from dataset import create_dataset | |||
| from dataset_distributed import create_dataset_parallel | |||
| from lenet import LeNet5 | |||
| import mindspore.nn as nn | |||
| from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor | |||
| from mindspore import load_checkpoint, load_param_into_net | |||
| from mindspore.train import Model | |||
| from mindspore.nn.metrics import Accuracy | |||
| from mindspore.communication.management import get_rank | |||
| #导入openi包 | |||
| from openi.context import prepare, upload_openi | |||
| from openi.context.helper import obs_copy_file, obs_copy_folder | |||
| parser = argparse.ArgumentParser(description='MindSpore Lenet Example') | |||
| parser.add_argument( | |||
| '--device_target', | |||
| type=str, | |||
| default="Ascend", | |||
| choices=['Ascend', 'CPU'], | |||
| help='device where the code will be implemented (default: Ascend),if to use the CPU on the Qizhi platform:device_target=CPU') | |||
| parser.add_argument('--epoch_size', | |||
| type=int, | |||
| default=5, | |||
| help='Training epochs.') | |||
| ### continue task parameters | |||
| parser.add_argument('--ckpt_load_name', | |||
| help='model name to save/load', | |||
| default= '') | |||
| parser.add_argument('--ckpt_save_name', | |||
| help='model name to save/load', | |||
| default= 'checkpoint') | |||
| if __name__ == "__main__": | |||
| args, unknown = parser.parse_known_args() | |||
| ###Initialize and copy data to training image | |||
| openi_context = prepare() | |||
| data_dir = openi_context.dataset_path | |||
| pretrain_model_dir = openi_context.pretrain_model_path | |||
| train_dir = openi_context.output_path | |||
| device_num = int(os.getenv('RANK_SIZE')) | |||
| ds_train = create_dataset(os.path.join(data_dir + "/MNISTData", "train"), cfg.batch_size) | |||
| if ds_train.get_dataset_size() == 0: | |||
| raise ValueError("Please check dataset size > 0 and batch_size <= dataset size") | |||
| network = LeNet5(cfg.num_classes) | |||
| net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean") | |||
| net_opt = nn.Momentum(network.trainable_params(), cfg.lr, cfg.momentum) | |||
| time_cb = TimeMonitor(data_size=ds_train.get_dataset_size()) | |||
| ### 继续训练模型加载 | |||
| if args.ckpt_load_name: | |||
| obs_copy_folder(args.train_url, base_path) | |||
| load_path = "{}/{}.ckpt".format(base_path,args.ckpt_load_name) | |||
| param_dict = load_checkpoint(load_path) | |||
| load_param_into_net(network, param_dict) | |||
| print("Successfully load ckpt file:{}, saved_net_work:{}".format(load_path,param_dict)) | |||
| ### 保存已有模型名避免重复回传结果 | |||
| outputFiles = os.listdir(base_path) | |||
| if args.device_target != "Ascend": | |||
| model = Model(network, | |||
| net_loss, | |||
| net_opt, | |||
| metrics={"accuracy": Accuracy()}) | |||
| else: | |||
| model = Model(network, | |||
| net_loss, | |||
| net_opt, | |||
| metrics={"accuracy": Accuracy()}, | |||
| amp_level="O2") | |||
| config_ck = CheckpointConfig( | |||
| save_checkpoint_steps=cfg.save_checkpoint_steps, | |||
| keep_checkpoint_max=cfg.keep_checkpoint_max) | |||
| #Note that this method saves the model file on each card. You need to specify the save path on each card. | |||
| # In this example, get_rank() is added to distinguish different paths. | |||
| if device_num == 1: | |||
| save_path = base_path + "/" | |||
| if device_num > 1: | |||
| save_path = base_path + "/" + str(get_rank()) + "/" | |||
| ckpoint_cb = ModelCheckpoint(prefix=args.ckpt_save_name, | |||
| directory=save_path, | |||
| config=config_ck) | |||
| print("============== Starting Training ==============") | |||
| epoch_size = cfg['epoch_size'] | |||
| if (args.epoch_size): | |||
| epoch_size = args.epoch_size | |||
| print('epoch_size is: ', epoch_size) | |||
| model.train(epoch_size, | |||
| ds_train, | |||
| callbacks=[time_cb, ckpoint_cb, | |||
| LossMonitor()]) | |||
| ### 将训练容器中的新输出模型 回传到启智社区 | |||
| outputFilesNew = os.listdir(base_path) | |||
| new_models = [i for i in outputFilesNew if i not in outputFiles] | |||
| for n in new_models: | |||
| ckpt_url = base_path + "/" + n | |||
| obs_ckpt_url = args.train_url + "/" + n | |||
| obs_copy_file(ckpt_url, obs_ckpt_url) | |||
+ 138
- 0
npu_mnist_example/train_npu.py
View File
| @@ -0,0 +1,138 @@ | |||
| """ | |||
| 示例选用的数据集是MNISTData.zip | |||
| 数据集结构是: | |||
| MNISTData.zip | |||
| ├── test | |||
| │ ├── t10k-images-idx3-ubyte | |||
| │ └── t10k-labels-idx1-ubyte | |||
| └── train | |||
| ├── train-images-idx3-ubyte | |||
| └── train-labels-idx1-ubyte | |||
| 使用注意事项: | |||
| 1、在代码中加入args, unknown = parser.parse_known_args(),可忽略掉--ckpt_url参数报错等参数问题 | |||
| 2、用户需要调用openi的python sdk包 | |||
| """ | |||
| import os | |||
| import argparse | |||
| from config import mnist_cfg as cfg | |||
| from dataset import create_dataset | |||
| from dataset_distributed import create_dataset_parallel | |||
| from lenet import LeNet5 | |||
| import mindspore.nn as nn | |||
| from mindspore import context | |||
| from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor | |||
| from mindspore.train import Model | |||
| from mindspore.context import ParallelMode | |||
| from mindspore.communication.management import init, get_rank | |||
| import time | |||
| #导入openi包 | |||
| from openi.context import prepare, upload_openi | |||
| parser = argparse.ArgumentParser(description='MindSpore Lenet Example') | |||
| parser.add_argument( | |||
| '--device_target', | |||
| type=str, | |||
| default="Ascend", | |||
| choices=['Ascend', 'CPU'], | |||
| help='device where the code will be implemented (default: Ascend),if to use the CPU on the Qizhi platform:device_target=CPU') | |||
| parser.add_argument('--epoch_size', | |||
| type=int, | |||
| default=5, | |||
| help='Training epochs.') | |||
| if __name__ == "__main__": | |||
| ###请在代码中加入args, unknown = parser.parse_known_args(),可忽略掉--ckpt_url参数报错等参数问题 | |||
| args, unknown = parser.parse_known_args() | |||
| data_dir = '' | |||
| pretrain_dir = '' | |||
| train_dir = '' | |||
| #回传结果到openi | |||
| upload_openi() | |||
| device_num = int(os.getenv('RANK_SIZE')) | |||
| #使用单卡时 | |||
| if device_num == 1: | |||
| context.set_context(mode=context.GRAPH_MODE,device_target=args.device_target) | |||
| #初始化导入数据集和预训练模型到容器内 | |||
| openi_context = prepare() | |||
| data_dir = openi_context.dataset_path | |||
| pretrain_dir = openi_context.pretrain_model_path | |||
| train_dir = openi_context.output_path | |||
| #使用数据集的方式 | |||
| ds_train = create_dataset(os.path.join(data_dir + "/MNISTData", "train"), cfg.batch_size) | |||
| #使用多卡时 | |||
| if device_num > 1: | |||
| # set device_id and init for multi-card training | |||
| context.set_context(mode=context.GRAPH_MODE, device_target=args.device_target, device_id=int(os.getenv('ASCEND_DEVICE_ID'))) | |||
| context.reset_auto_parallel_context() | |||
| context.set_auto_parallel_context(device_num = device_num, parallel_mode=ParallelMode.DATA_PARALLEL, gradients_mean=True, parameter_broadcast=True) | |||
| init() | |||
| #Copying obs data does not need to be executed multiple times, just let the 0th card copy the data | |||
| local_rank=int(os.getenv('RANK_ID')) | |||
| if local_rank%8==0: | |||
| ###初始化导入数据集和预训练模型到容器内 | |||
| openi_context = prepare() | |||
| #初始化导入数据集和预训练模型到容器内 | |||
| openi_context = prepare() | |||
| data_dir = openi_context.dataset_path | |||
| pretrain_dir = openi_context.pretrain_model_path | |||
| train_dir = openi_context.output_path | |||
| #Set a cache file to determine whether the data has been copied to obs. | |||
| #If this file exists during multi-card training, there is no need to copy the dataset multiple times. | |||
| f = open("/cache/download_input.txt", 'w') | |||
| f.close() | |||
| try: | |||
| if os.path.exists("/cache/download_input.txt"): | |||
| print("download_input succeed") | |||
| except Exception as e: | |||
| print("download_input failed") | |||
| while not os.path.exists("/cache/download_input.txt"): | |||
| time.sleep(1) | |||
| ds_train = create_dataset_parallel(os.path.join(data_dir + "/MNISTData", "train"), cfg.batch_size) | |||
| network = LeNet5(cfg.num_classes) | |||
| net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean") | |||
| net_opt = nn.Momentum(network.trainable_params(), cfg.lr, cfg.momentum) | |||
| time_cb = TimeMonitor(data_size=ds_train.get_dataset_size()) | |||
| if args.device_target != "Ascend": | |||
| model = Model(network, | |||
| net_loss, | |||
| net_opt, | |||
| metrics={"accuracy"}) | |||
| else: | |||
| model = Model(network, | |||
| net_loss, | |||
| net_opt, | |||
| metrics={"accuracy"}, | |||
| amp_level="O2") | |||
| config_ck = CheckpointConfig( | |||
| save_checkpoint_steps=cfg.save_checkpoint_steps, | |||
| keep_checkpoint_max=cfg.keep_checkpoint_max) | |||
| #Note that this method saves the model file on each card. You need to specify the save path on each card. | |||
| # In this example, get_rank() is added to distinguish different paths. | |||
| if device_num == 1: | |||
| outputDirectory = train_dir + "/" | |||
| if device_num > 1: | |||
| outputDirectory = train_dir + "/" + str(get_rank()) + "/" | |||
| ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", | |||
| directory=outputDirectory, | |||
| config=config_ck) | |||
| print("============== Starting Training ==============") | |||
| epoch_size = cfg['epoch_size'] | |||
| if (args.epoch_size): | |||
| epoch_size = args.epoch_size | |||
| print('epoch_size is: ', epoch_size) | |||
| model.train(epoch_size, ds_train,callbacks=[time_cb, ckpoint_cb,LossMonitor()]) | |||
| ###上传训练结果到启智平台,注意必须将要输出的模型存储在openi_context.output_path | |||
| upload_openi() | |||