 scruel
8 years ago
scruel
8 years ago
9 changed files with 29 additions and 30 deletions
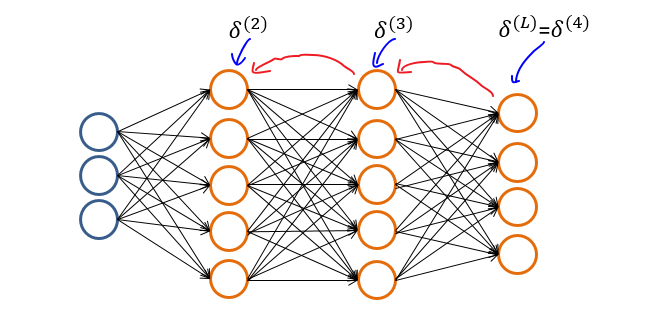
BIN
image/20180120_105744.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 653 | Height: 317 | Size: 74 kB |
BIN
image/20180121_110111.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 625 | Height: 331 | Size: 76 kB |
+ 2
- 1
index.html
View File
+ 2
- 2
week2.html
File diff suppressed because it is too large
View File
+ 2
- 2
week2.md
View File
+ 10
- 11
week3.html
File diff suppressed because it is too large
View File
+ 11
- 12
week3.md
View File
+ 1
- 1
week4.html
File diff suppressed because it is too large
View File
+ 1
- 1
week4.md
View File
Loading…