Browse Source
!4412 MASS support running on GPU.
Merge pull request !4412 from linqingke/masstags/v0.7.0-beta
 mindspore-ci-bot
mindspore-ci-bot
 Gitee
5 years ago
Gitee
5 years ago
7 changed files with 335 additions and 79 deletions
Unified View
Diff Options
-
+80 -29model_zoo/official/nlp/mass/README.md
-
+14 -0model_zoo/official/nlp/mass/eval.py
-
+2 -2model_zoo/official/nlp/mass/scripts/run_ascend.sh
-
+157 -0model_zoo/official/nlp/mass/scripts/run_gpu.sh
-
+37 -10model_zoo/official/nlp/mass/src/transformer/transformer_for_train.py
-
+4 -2model_zoo/official/nlp/mass/src/utils/loss_monitor.py
-
+41 -36model_zoo/official/nlp/mass/train.py
+ 80
- 29
model_zoo/official/nlp/mass/README.md
View File
| @@ -57,9 +57,6 @@ The overall network architecture of MASS is shown below, which is Transformer(Va | |||||
| MASS is consisted of 6-layer encoder and 6-layer decoder with 1024 embedding/hidden size, and 4096 intermediate size between feed forward network which has two full connection layers. | MASS is consisted of 6-layer encoder and 6-layer decoder with 1024 embedding/hidden size, and 4096 intermediate size between feed forward network which has two full connection layers. | ||||
| 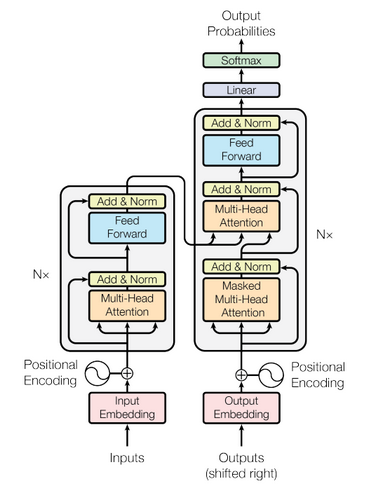 | |||||
| # Dataset | # Dataset | ||||
| Dataset used: | Dataset used: | ||||
| @@ -124,7 +121,8 @@ MASS script and code structure are as follow: | |||||
| │ ├──all.bpe.codes // BPE codes table(this file should be generated by user). | │ ├──all.bpe.codes // BPE codes table(this file should be generated by user). | ||||
| │ ├──all_en.dict.bin // Learned vocabulary file(this file should be generated by user). | │ ├──all_en.dict.bin // Learned vocabulary file(this file should be generated by user). | ||||
| ├── scripts | ├── scripts | ||||
| │ ├──run.sh // Train & evaluate model script. | |||||
| │ ├──run_ascend.sh // Ascend train & evaluate model script. | |||||
| │ ├──run_gpu.sh // GPU train & evaluate model script. | |||||
| │ ├──learn_subword.sh // Learn BPE codes. | │ ├──learn_subword.sh // Learn BPE codes. | ||||
| │ ├──stop_training.sh // Stop training. | │ ├──stop_training.sh // Stop training. | ||||
| ├── requirements.txt // Requirements of third party package. | ├── requirements.txt // Requirements of third party package. | ||||
| @@ -329,18 +327,24 @@ Almost all of the options and arguments needed could be assigned conveniently, i | |||||
| For more detailed information about the attributes, refer to the file `config/config.py`. | For more detailed information about the attributes, refer to the file `config/config.py`. | ||||
| ## Training & Evaluation process | ## Training & Evaluation process | ||||
| For training a model, the shell script `run.sh` is all you need. In this scripts, the environment variable is set and the training script `train.py` under `mass` is executed. | |||||
| For training a model, the shell script `run_ascend.sh` or `run_gpu.sh` is all you need. In this scripts, the environment variable is set and the training script `train.py` under `mass` is executed. | |||||
| You may start a task training with single device or multiple devices by assigning the options and run the command in bash: | You may start a task training with single device or multiple devices by assigning the options and run the command in bash: | ||||
| ```bash | |||||
| sh run.sh [--options] | |||||
| Ascend: | |||||
| ```ascend | |||||
| sh run_ascend.sh [--options] | |||||
| ``` | |||||
| GPU: | |||||
| ```gpu | |||||
| sh run_gpu.sh [--options] | |||||
| ``` | ``` | ||||
| The usage is shown as bellow: | |||||
| The usage of `run_ascend.sh` is shown as bellow: | |||||
| ```text | ```text | ||||
| Usage: run.sh [-h, --help] [-t, --task <CHAR>] [-n, --device_num <N>] | |||||
| [-i, --device_id <N>] [-j, --hccl_json <FILE>] | |||||
| [-c, --config <FILE>] [-o, --output <FILE>] | |||||
| [-v, --vocab <FILE>] | |||||
| Usage: run_ascend.sh [-h, --help] [-t, --task <CHAR>] [-n, --device_num <N>] | |||||
| [-i, --device_id <N>] [-j, --hccl_json <FILE>] | |||||
| [-c, --config <FILE>] [-o, --output <FILE>] | |||||
| [-v, --vocab <FILE>] | |||||
| options: | options: | ||||
| -h, --help show usage | -h, --help show usage | ||||
| @@ -350,20 +354,49 @@ options: | |||||
| -j, --hccl_json rank table file used for training with multiple devices: FILE. | -j, --hccl_json rank table file used for training with multiple devices: FILE. | ||||
| -c, --config configuration file as shown in the path 'mass/config': FILE. | -c, --config configuration file as shown in the path 'mass/config': FILE. | ||||
| -o, --output assign output file of inference: FILE. | -o, --output assign output file of inference: FILE. | ||||
| -v, --vocab set the vocabulary" | |||||
| -v, --vocab set the vocabulary. | |||||
| -m, --metric set the metric. | |||||
| ``` | ``` | ||||
| Notes: Be sure to assign the hccl_json file while running a distributed-training. | Notes: Be sure to assign the hccl_json file while running a distributed-training. | ||||
| The usage of `run_gpu.sh` is shown as bellow: | |||||
| ```text | |||||
| Usage: run_gpu.sh [-h, --help] [-t, --task <CHAR>] [-n, --device_num <N>] | |||||
| [-i, --device_id <N>] [-c, --config <FILE>] | |||||
| [-o, --output <FILE>] [-v, --vocab <FILE>] | |||||
| options: | |||||
| -h, --help show usage | |||||
| -t, --task select task: CHAR, 't' for train and 'i' for inference". | |||||
| -n, --device_num device number used for training: N, default is 1. | |||||
| -i, --device_id device id used for training with single device: N, 0<=N<=7, default is 0. | |||||
| -c, --config configuration file as shown in the path 'mass/config': FILE. | |||||
| -o, --output assign output file of inference: FILE. | |||||
| -v, --vocab set the vocabulary. | |||||
| -m, --metric set the metric. | |||||
| ``` | |||||
| The command followed shows a example for training with 2 devices. | The command followed shows a example for training with 2 devices. | ||||
| ```bash | |||||
| sh run.sh --task t --device_num 2 --hccl_json /{path}/rank_table.json --config /{path}/config.json | |||||
| Ascend: | |||||
| ```ascend | |||||
| sh run_ascend.sh --task t --device_num 2 --hccl_json /{path}/rank_table.json --config /{path}/config.json | |||||
| ``` | ``` | ||||
| ps. Discontinuous device id is not supported in `run.sh` at present, device id in `rank_table.json` must start from 0. | |||||
| ps. Discontinuous device id is not supported in `run_ascend.sh` at present, device id in `rank_table.json` must start from 0. | |||||
| GPU: | |||||
| ```gpu | |||||
| sh run_gpu.sh --task t --device_num 2 --config /{path}/config.json | |||||
| ``` | |||||
| If use a single chip, it would be like this: | If use a single chip, it would be like this: | ||||
| ```bash | |||||
| sh run.sh --task t --device_num 1 --device_id 0 --config /{path}/config.json | |||||
| Ascend: | |||||
| ```ascend | |||||
| sh run_ascend.sh --task t --device_num 1 --device_id 0 --config /{path}/config.json | |||||
| ``` | |||||
| GPU: | |||||
| ```gpu | |||||
| sh run_gpu.sh --task t --device_num 1 --device_id 0 --config /{path}/config.json | |||||
| ``` | ``` | ||||
| @@ -441,9 +474,6 @@ During testing, we use the fine-turned model to predict the result, and adopt a | |||||
| get the most possible prediction results. | get the most possible prediction results. | ||||
|  | |||||
| ## Performance | ## Performance | ||||
| ### Results | ### Results | ||||
| @@ -543,11 +573,18 @@ For pre-training a model, config the options in `config.json` firstly: | |||||
| - Set other arguments including dataset configurations and network configurations. | - Set other arguments including dataset configurations and network configurations. | ||||
| - If you have a trained model already, assign the `existed_ckpt` to the checkpoint file. | - If you have a trained model already, assign the `existed_ckpt` to the checkpoint file. | ||||
| Run the shell script `run.sh` as followed: | |||||
| If you use the ascend chip, run the shell script `run_ascend.sh` as followed: | |||||
| ```bash | |||||
| sh run.sh -t t -n 1 -i 1 -c /mass/config/config.json | |||||
| ```ascend | |||||
| sh run_ascend.sh -t t -n 1 -i 1 -c /mass/config/config.json | |||||
| ``` | ``` | ||||
| You can also run the shell script `run_gpu.sh` on gpu as followed: | |||||
| ```gpu | |||||
| sh run_gpu.sh -t t -n 1 -i 1 -c /mass/config/config.json | |||||
| ``` | |||||
| Get the log and output files under the path `./train_mass_*/`, and the model file under the path assigned in the `config/config.json` file. | Get the log and output files under the path `./train_mass_*/`, and the model file under the path assigned in the `config/config.json` file. | ||||
| ## Fine-tuning | ## Fine-tuning | ||||
| @@ -558,10 +595,18 @@ For fine-tuning a model, config the options in `config.json` firstly: | |||||
| - Assign the `ckpt_prefix` and `ckpt_path` under `checkpoint_path` node to save the model files. | - Assign the `ckpt_prefix` and `ckpt_path` under `checkpoint_path` node to save the model files. | ||||
| - Set other arguments including dataset configurations and network configurations. | - Set other arguments including dataset configurations and network configurations. | ||||
| Run the shell script `run.sh` as followed: | |||||
| ```bash | |||||
| sh run.sh -t t -n 1 -i 1 -c config/config.json | |||||
| If you use the ascend chip, run the shell script `run_ascend.sh` as followed: | |||||
| ```ascend | |||||
| sh run_ascend.sh -t t -n 1 -i 1 -c config/config.json | |||||
| ``` | |||||
| You can also run the shell script `run_gpu.sh` on gpu as followed: | |||||
| ```gpu | |||||
| sh run_gpu.sh -t t -n 1 -i 1 -c config/config.json | |||||
| ``` | ``` | ||||
| Get the log and output files under the path `./train_mass_*/`, and the model file under the path assigned in the `config/config.json` file. | Get the log and output files under the path `./train_mass_*/`, and the model file under the path assigned in the `config/config.json` file. | ||||
| ## Inference | ## Inference | ||||
| @@ -573,10 +618,16 @@ For inference, config the options in `config.json` firstly: | |||||
| - Assign the `ckpt_prefix` and `ckpt_path` under `checkpoint_path` node to save the model files. | - Assign the `ckpt_prefix` and `ckpt_path` under `checkpoint_path` node to save the model files. | ||||
| - Set other arguments including dataset configurations and network configurations. | - Set other arguments including dataset configurations and network configurations. | ||||
| Run the shell script `run.sh` as followed: | |||||
| If you use the ascend chip, run the shell script `run_ascend.sh` as followed: | |||||
| ```bash | ```bash | ||||
| sh run.sh -t i -n 1 -i 1 -c config/config.json -o {outputfile} | |||||
| sh run_ascend.sh -t i -n 1 -i 1 -c config/config.json -o {outputfile} | |||||
| ``` | |||||
| You can also run the shell script `run_gpu.sh` on gpu as followed: | |||||
| ```gpu | |||||
| sh run_gpu.sh -t i -n 1 -i 1 -c config/config.json -o {outputfile} | |||||
| ``` | ``` | ||||
| # Description of random situation | # Description of random situation | ||||
+ 14
- 0
model_zoo/official/nlp/mass/eval.py
View File
| @@ -13,10 +13,12 @@ | |||||
| # limitations under the License. | # limitations under the License. | ||||
| # ============================================================================ | # ============================================================================ | ||||
| """Evaluation api.""" | """Evaluation api.""" | ||||
| import os | |||||
| import argparse | import argparse | ||||
| import pickle | import pickle | ||||
| from mindspore.common import dtype as mstype | from mindspore.common import dtype as mstype | ||||
| from mindspore import context | |||||
| from config import TransformerConfig | from config import TransformerConfig | ||||
| from src.transformer import infer, infer_ppl | from src.transformer import infer, infer_ppl | ||||
| @@ -32,6 +34,8 @@ parser.add_argument("--output", type=str, required=True, | |||||
| help="Result file path.") | help="Result file path.") | ||||
| parser.add_argument("--metric", type=str, default='rouge', | parser.add_argument("--metric", type=str, default='rouge', | ||||
| help='Set eval method.') | help='Set eval method.') | ||||
| parser.add_argument("--platform", type=str, required=True, | |||||
| help="model working platform.") | |||||
| def get_config(config): | def get_config(config): | ||||
| @@ -46,6 +50,16 @@ if __name__ == '__main__': | |||||
| vocab = Dictionary.load_from_persisted_dict(args.vocab) | vocab = Dictionary.load_from_persisted_dict(args.vocab) | ||||
| _config = get_config(args.config) | _config = get_config(args.config) | ||||
| device_id = os.getenv('DEVICE_ID', None) | |||||
| if device_id is None: | |||||
| device_id = 0 | |||||
| device_id = int(device_id) | |||||
| context.set_context( | |||||
| mode=context.GRAPH_MODE, | |||||
| device_target=args.platform, | |||||
| reserve_class_name_in_scope=False, | |||||
| device_id=device_id) | |||||
| if args.metric == 'rouge': | if args.metric == 'rouge': | ||||
| result = infer(_config) | result = infer(_config) | ||||
| else: | else: | ||||
model_zoo/official/nlp/mass/scripts/run.sh → model_zoo/official/nlp/mass/scripts/run_ascend.sh
View File
| @@ -165,10 +165,10 @@ do | |||||
| echo $task | echo $task | ||||
| if [ "$task" == "train" ] | if [ "$task" == "train" ] | ||||
| then | then | ||||
| python train.py --config ${configurations##*/} >>log.log 2>&1 & | |||||
| python train.py --config ${configurations##*/} --platform Ascend >>log.log 2>&1 & | |||||
| elif [ "$task" == "infer" ] | elif [ "$task" == "infer" ] | ||||
| then | then | ||||
| python eval.py --config ${configurations##*/} --output ${output} --vocab ${vocab##*/} --metric ${metric} >>log_infer.log 2>&1 & | |||||
| python eval.py --config ${configurations##*/} --output ${output} --vocab ${vocab##*/} --metric ${metric} --platform Ascend >>log_infer.log 2>&1 & | |||||
| fi | fi | ||||
| cd ../ | cd ../ | ||||
| done | done | ||||
+ 157
- 0
model_zoo/official/nlp/mass/scripts/run_gpu.sh
View File
| @@ -0,0 +1,157 @@ | |||||
| #!/usr/bin/env bash | |||||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||||
| # | |||||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||||
| # you may not use this file except in compliance with the License. | |||||
| # You may obtain a copy of the License at | |||||
| # | |||||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||||
| # | |||||
| # Unless required by applicable law or agreed to in writing, software | |||||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||||
| # See the License for the specific language governing permissions and | |||||
| # limitations under the License. | |||||
| # ============================================================================ | |||||
| export DEVICE_ID=0 | |||||
| export RANK_ID=0 | |||||
| export RANK_SIZE=1 | |||||
| options=`getopt -u -o ht:n:i::o:v:m: -l help,task:,device_num:,device_id:,config:,output:,vocab:,metric: -- "$@"` | |||||
| eval set -- "$options" | |||||
| echo $options | |||||
| echo_help() | |||||
| { | |||||
| echo "Usage:" | |||||
| echo "bash train.sh [-h] [-t t|i] [-n N] [-i N] [-j FILE] [-c FILE] [-o FILE] [-v FILE]" | |||||
| echo "options:" | |||||
| echo " -h --help show usage" | |||||
| echo " -t --task select task, 't' for training and 'i' for inference" | |||||
| echo " -n --device_num training with N devices" | |||||
| echo " -i --device_id training with device i" | |||||
| echo " -c --config set the configuration file" | |||||
| echo " -o --output set the output file of inference" | |||||
| echo " -v --vocab set the vocabulary" | |||||
| echo " -m --metric set the metric" | |||||
| } | |||||
| set_device_id() | |||||
| { | |||||
| while [ -n "$1" ] | |||||
| do | |||||
| if [[ "$1" == "-i" || "$1" == "--device_id" ]] | |||||
| then | |||||
| if [[ $2 -ge 0 && $2 -le 7 ]] | |||||
| then | |||||
| export DEVICE_ID=$2 | |||||
| fi | |||||
| break | |||||
| fi | |||||
| shift | |||||
| done | |||||
| } | |||||
| while [ -n "$1" ] | |||||
| do | |||||
| case "$1" in | |||||
| -h|--help) | |||||
| echo_help | |||||
| shift | |||||
| ;; | |||||
| -t|--task) | |||||
| echo "task:" | |||||
| if [ "$2" == "t" ] | |||||
| then | |||||
| task=train | |||||
| elif [ "$2" == "i" ] | |||||
| then | |||||
| task=infer | |||||
| fi | |||||
| shift 2 | |||||
| ;; | |||||
| -n|--device_num) | |||||
| echo "device_num" | |||||
| if [ $2 -eq 1 ] | |||||
| then | |||||
| set_device_id $options | |||||
| elif [ $2 -gt 1 ] | |||||
| then | |||||
| export RANK_SIZE=$2 | |||||
| fi | |||||
| shift 2 | |||||
| ;; | |||||
| -i|--device_id) | |||||
| echo "set device id" | |||||
| export DEVICE_ID=$2 | |||||
| shift 2 | |||||
| ;; | |||||
| -c|--config) | |||||
| echo "config"; | |||||
| configurations=$2 | |||||
| shift 2 | |||||
| ;; | |||||
| -o|--output) | |||||
| echo "output"; | |||||
| output=$2 | |||||
| shift 2 | |||||
| ;; | |||||
| -v|--vocab) | |||||
| echo "vocab"; | |||||
| vocab=$2 | |||||
| shift 2 | |||||
| ;; | |||||
| -m|--metric) | |||||
| echo "metric"; | |||||
| metric=$2 | |||||
| shift 2 | |||||
| ;; | |||||
| --) | |||||
| shift | |||||
| break | |||||
| ;; | |||||
| *) | |||||
| shift | |||||
| ;; | |||||
| esac | |||||
| done | |||||
| file_path=$(cd "$(dirname $0)" || exit; pwd) | |||||
| if [ $RANK_SIZE -gt 1 ] | |||||
| then | |||||
| echo "Working on $RANK_SIZE device" | |||||
| fi | |||||
| echo "Working on file ${task}_mass_$DEVICE_ID" | |||||
| cd $file_path || exit | |||||
| cd ../ || exit | |||||
| rm -rf ./${task}_mass_$DEVICE_ID | |||||
| mkdir ./${task}_mass_$DEVICE_ID | |||||
| cp train.py ./${task}_mass_$DEVICE_ID | |||||
| cp eval.py ./${task}_mass_$DEVICE_ID | |||||
| cp $configurations ./${task}_mass_$DEVICE_ID | |||||
| if [ $vocab ] | |||||
| then | |||||
| cp $vocab ./${task}_mass_$DEVICE_ID | |||||
| fi | |||||
| cd ./${task}_mass_$DEVICE_ID || exit | |||||
| env > log.log | |||||
| echo $task | |||||
| if [ "$task" == "train" ] | |||||
| then | |||||
| if [ $RANK_SIZE -gt 1 ] | |||||
| then | |||||
| mpirun -n $RANK_SIZE python train.py --config ${configurations##*/} --platform GPU >>log.log 2>&1 & | |||||
| fi | |||||
| python train.py --config ${configurations##*/} --platform GPU >>log.log 2>&1 & | |||||
| elif [ "$task" == "infer" ] | |||||
| then | |||||
| python eval.py --config ${configurations##*/} --output ${output} --vocab ${vocab##*/} --metric ${metric} --platform GPU >>log_infer.log 2>&1 & | |||||
| fi | |||||
| cd ../ | |||||
+ 37
- 10
model_zoo/official/nlp/mass/src/transformer/transformer_for_train.py
View File
| @@ -14,6 +14,7 @@ | |||||
| # ============================================================================ | # ============================================================================ | ||||
| """Transformer for training.""" | """Transformer for training.""" | ||||
| from mindspore import nn | from mindspore import nn | ||||
| import mindspore.context as context | |||||
| from mindspore.ops import operations as P | from mindspore.ops import operations as P | ||||
| from mindspore.ops import functional as F | from mindspore.ops import functional as F | ||||
| from mindspore.ops import composite as C | from mindspore.ops import composite as C | ||||
| @@ -204,11 +205,16 @@ class TransformerNetworkWithLoss(nn.Cell): | |||||
| grad_scale = C.MultitypeFuncGraph("grad_scale") | grad_scale = C.MultitypeFuncGraph("grad_scale") | ||||
| reciprocal = P.Reciprocal() | reciprocal = P.Reciprocal() | ||||
| @grad_scale.register("Tensor", "Tensor") | @grad_scale.register("Tensor", "Tensor") | ||||
| def tensor_grad_scale(scale, grad): | def tensor_grad_scale(scale, grad): | ||||
| return grad * F.cast(reciprocal(scale), F.dtype(grad)) | return grad * F.cast(reciprocal(scale), F.dtype(grad)) | ||||
| _grad_overflow = C.MultitypeFuncGraph("_grad_overflow") | |||||
| grad_overflow = P.FloatStatus() | |||||
| @_grad_overflow.register("Tensor") | |||||
| def _tensor_grad_overflow(grad): | |||||
| return grad_overflow(grad) | |||||
| class TransformerTrainOneStepWithLossScaleCell(nn.Cell): | class TransformerTrainOneStepWithLossScaleCell(nn.Cell): | ||||
| """ | """ | ||||
| @@ -251,9 +257,16 @@ class TransformerTrainOneStepWithLossScaleCell(nn.Cell): | |||||
| self.is_distributed = (self.parallel_mode != ParallelMode.STAND_ALONE) | self.is_distributed = (self.parallel_mode != ParallelMode.STAND_ALONE) | ||||
| self.clip_gradients = ClipGradients() | self.clip_gradients = ClipGradients() | ||||
| self.cast = P.Cast() | self.cast = P.Cast() | ||||
| self.alloc_status = P.NPUAllocFloatStatus() | |||||
| self.get_status = P.NPUGetFloatStatus() | |||||
| self.clear_before_grad = P.NPUClearFloatStatus() | |||||
| if context.get_context("device_target") == "GPU": | |||||
| self.gpu_target = True | |||||
| self.float_status = P.FloatStatus() | |||||
| self.addn = P.AddN() | |||||
| self.reshape = P.Reshape() | |||||
| else: | |||||
| self.gpu_target = False | |||||
| self.alloc_status = P.NPUAllocFloatStatus() | |||||
| self.get_status = P.NPUGetFloatStatus() | |||||
| self.clear_status = P.NPUClearFloatStatus() | |||||
| self.reduce_sum = P.ReduceSum(keep_dims=False) | self.reduce_sum = P.ReduceSum(keep_dims=False) | ||||
| self.depend_parameter_use = P.ControlDepend(depend_mode=1) | self.depend_parameter_use = P.ControlDepend(depend_mode=1) | ||||
| self.base = Tensor(1, mstype.float32) | self.base = Tensor(1, mstype.float32) | ||||
| @@ -304,14 +317,18 @@ class TransformerTrainOneStepWithLossScaleCell(nn.Cell): | |||||
| target_mask, | target_mask, | ||||
| label_ids, | label_ids, | ||||
| label_weights) | label_weights) | ||||
| # Alloc status. | |||||
| init = self.alloc_status() | |||||
| # Clear overflow buffer. | |||||
| self.clear_before_grad(init) | |||||
| init = False | |||||
| if not self.gpu_target: | |||||
| # init overflow buffer | |||||
| init = self.alloc_status() | |||||
| # clear overflow buffer | |||||
| self.clear_status(init) | |||||
| if sens is None: | if sens is None: | ||||
| scaling_sens = self.loss_scale | scaling_sens = self.loss_scale | ||||
| else: | else: | ||||
| scaling_sens = sens | scaling_sens = sens | ||||
| grads = self.grad(self.network, weights)(source_ids, | grads = self.grad(self.network, weights)(source_ids, | ||||
| source_mask, | source_mask, | ||||
| target_ids, | target_ids, | ||||
| @@ -323,11 +340,21 @@ class TransformerTrainOneStepWithLossScaleCell(nn.Cell): | |||||
| grads = self.hyper_map(F.partial(grad_scale, scaling_sens), grads) | grads = self.hyper_map(F.partial(grad_scale, scaling_sens), grads) | ||||
| grads = self.clip_gradients(grads, GRADIENT_CLIP_TYPE, GRADIENT_CLIP_VALUE) | grads = self.clip_gradients(grads, GRADIENT_CLIP_TYPE, GRADIENT_CLIP_VALUE) | ||||
| if self.reducer_flag: | if self.reducer_flag: | ||||
| # Apply grad reducer on grads. | # Apply grad reducer on grads. | ||||
| grads = self.grad_reducer(grads) | grads = self.grad_reducer(grads) | ||||
| self.get_status(init) | |||||
| flag_sum = self.reduce_sum(init, (0,)) | |||||
| # get the overflow buffer | |||||
| if not self.gpu_target: | |||||
| self.get_status(init) | |||||
| # sum overflow buffer elements, 0:not overflow , >0:overflow | |||||
| flag_sum = self.reduce_sum(init, (0,)) | |||||
| else: | |||||
| flag_sum = self.hyper_map(F.partial(_grad_overflow), grads) | |||||
| flag_sum = self.addn(flag_sum) | |||||
| # convert flag_sum to scalar | |||||
| flag_sum = self.reshape(flag_sum, (())) | |||||
| if self.is_distributed: | if self.is_distributed: | ||||
| # Sum overflow flag over devices. | # Sum overflow flag over devices. | ||||
+ 4
- 2
model_zoo/official/nlp/mass/src/utils/loss_monitor.py
View File
| @@ -49,11 +49,13 @@ class LossCallBack(Callback): | |||||
| file_name = "./loss.log" | file_name = "./loss.log" | ||||
| with open(file_name, "a+") as f: | with open(file_name, "a+") as f: | ||||
| time_stamp_current = self._get_ms_timestamp() | time_stamp_current = self._get_ms_timestamp() | ||||
| f.write("time: {}, epoch: {}, step: {}, outputs are {}.\n".format( | |||||
| f.write("time: {}, epoch: {}, step: {}, outputs are {},{},{}.\n".format( | |||||
| time_stamp_current - self.time_stamp_first, | time_stamp_current - self.time_stamp_first, | ||||
| cb_params.cur_epoch_num, | cb_params.cur_epoch_num, | ||||
| cb_params.cur_step_num, | cb_params.cur_step_num, | ||||
| str(cb_params.net_outputs) | |||||
| str(cb_params.net_outputs[0].asnumpy()), | |||||
| str(cb_params.net_outputs[1].asnumpy()), | |||||
| str(cb_params.net_outputs[2].asnumpy()) | |||||
| )) | )) | ||||
| @staticmethod | @staticmethod | ||||
+ 41
- 36
model_zoo/official/nlp/mass/train.py
View File
| @@ -24,7 +24,7 @@ from mindspore.common.tensor import Tensor | |||||
| from mindspore.nn import Momentum | from mindspore.nn import Momentum | ||||
| from mindspore.nn.optim import Adam, Lamb | from mindspore.nn.optim import Adam, Lamb | ||||
| from mindspore.train.model import Model | from mindspore.train.model import Model | ||||
| from mindspore.train.loss_scale_manager import DynamicLossScaleManager | |||||
| from mindspore.train.loss_scale_manager import DynamicLossScaleManager, FixedLossScaleManager | |||||
| from mindspore.train.callback import CheckpointConfig, ModelCheckpoint | from mindspore.train.callback import CheckpointConfig, ModelCheckpoint | ||||
| from mindspore import context, ParallelMode, Parameter | from mindspore import context, ParallelMode, Parameter | ||||
| from mindspore.communication import management as MultiAscend | from mindspore.communication import management as MultiAscend | ||||
| @@ -41,18 +41,7 @@ from src.utils.lr_scheduler import polynomial_decay_scheduler, BertLearningRate | |||||
| parser = argparse.ArgumentParser(description='MASS train entry point.') | parser = argparse.ArgumentParser(description='MASS train entry point.') | ||||
| parser.add_argument("--config", type=str, required=True, help="model config json file path.") | parser.add_argument("--config", type=str, required=True, help="model config json file path.") | ||||
| device_id = os.getenv('DEVICE_ID', None) | |||||
| if device_id is None: | |||||
| raise RuntimeError("`DEVICE_ID` can not be None.") | |||||
| device_id = int(device_id) | |||||
| context.set_context( | |||||
| mode=context.GRAPH_MODE, | |||||
| device_target="Ascend", | |||||
| reserve_class_name_in_scope=False, | |||||
| device_id=device_id) | |||||
| parser.add_argument("--platform", type=str, required=True, help="model working platform.") | |||||
| def get_config(config): | def get_config(config): | ||||
| config = TransformerConfig.from_json_file(config) | config = TransformerConfig.from_json_file(config) | ||||
| @@ -79,12 +68,11 @@ def _train(model, config: TransformerConfig, | |||||
| if pre_training_dataset is not None: | if pre_training_dataset is not None: | ||||
| print(" | Start pre-training job.") | print(" | Start pre-training job.") | ||||
| epoch_size = config.epochs * pre_training_dataset.get_dataset_size() // config.dataset_sink_step | |||||
| if os.getenv("RANK_SIZE") is not None and int(os.getenv("RANK_SIZE")) > 1: | if os.getenv("RANK_SIZE") is not None and int(os.getenv("RANK_SIZE")) > 1: | ||||
| print(f" | Rank {MultiAscend.get_rank()} Call model train.") | print(f" | Rank {MultiAscend.get_rank()} Call model train.") | ||||
| model.train(epoch_size, pre_training_dataset, | |||||
| model.train(config.epochs, pre_training_dataset, | |||||
| callbacks=callbacks, dataset_sink_mode=config.dataset_sink_mode, | callbacks=callbacks, dataset_sink_mode=config.dataset_sink_mode, | ||||
| sink_size=config.dataset_sink_step) | sink_size=config.dataset_sink_step) | ||||
| @@ -97,9 +85,8 @@ def _train(model, config: TransformerConfig, | |||||
| if fine_tune_dataset is not None: | if fine_tune_dataset is not None: | ||||
| print(" | Start fine-tuning job.") | print(" | Start fine-tuning job.") | ||||
| epoch_size = config.epochs * fine_tune_dataset.get_dataset_size() // config.dataset_sink_step | |||||
| model.train(epoch_size, fine_tune_dataset, | |||||
| model.train(config.epochs, fine_tune_dataset, | |||||
| callbacks=callbacks, dataset_sink_mode=config.dataset_sink_mode, | callbacks=callbacks, dataset_sink_mode=config.dataset_sink_mode, | ||||
| sink_size=config.dataset_sink_step) | sink_size=config.dataset_sink_step) | ||||
| @@ -114,7 +101,8 @@ def _train(model, config: TransformerConfig, | |||||
| def _build_training_pipeline(config: TransformerConfig, | def _build_training_pipeline(config: TransformerConfig, | ||||
| pre_training_dataset=None, | pre_training_dataset=None, | ||||
| fine_tune_dataset=None, | fine_tune_dataset=None, | ||||
| test_dataset=None): | |||||
| test_dataset=None, | |||||
| platform="Ascend"): | |||||
| """ | """ | ||||
| Build training pipeline. | Build training pipeline. | ||||
| @@ -198,14 +186,15 @@ def _build_training_pipeline(config: TransformerConfig, | |||||
| else: | else: | ||||
| raise ValueError(f"optimizer only support `adam` and `momentum` now.") | raise ValueError(f"optimizer only support `adam` and `momentum` now.") | ||||
| # Dynamic loss scale. | |||||
| scale_manager = DynamicLossScaleManager(init_loss_scale=config.init_loss_scale, | |||||
| scale_factor=config.loss_scale_factor, | |||||
| scale_window=config.scale_window) | |||||
| net_with_grads = TransformerTrainOneStepWithLossScaleCell( | |||||
| network=net_with_loss, optimizer=optimizer, | |||||
| scale_update_cell=scale_manager.get_update_cell() | |||||
| ) | |||||
| # loss scale. | |||||
| if platform == "Ascend": | |||||
| scale_manager = DynamicLossScaleManager(init_loss_scale=config.init_loss_scale, | |||||
| scale_factor=config.loss_scale_factor, | |||||
| scale_window=config.scale_window) | |||||
| else: | |||||
| scale_manager = FixedLossScaleManager(loss_scale=1.0, drop_overflow_update=True) | |||||
| net_with_grads = TransformerTrainOneStepWithLossScaleCell(network=net_with_loss, optimizer=optimizer, | |||||
| scale_update_cell=scale_manager.get_update_cell()) | |||||
| net_with_grads.set_train(True) | net_with_grads.set_train(True) | ||||
| model = Model(net_with_grads) | model = Model(net_with_grads) | ||||
| loss_monitor = LossCallBack(config) | loss_monitor = LossCallBack(config) | ||||
| @@ -236,9 +225,12 @@ def _build_training_pipeline(config: TransformerConfig, | |||||
| callbacks=callbacks) | callbacks=callbacks) | ||||
| def _setup_parallel_env(): | |||||
| def _setup_parallel_env(platform): | |||||
| context.reset_auto_parallel_context() | context.reset_auto_parallel_context() | ||||
| MultiAscend.init() | |||||
| if platform == "GPU": | |||||
| MultiAscend.init("nccl") | |||||
| else: | |||||
| MultiAscend.init() | |||||
| context.set_auto_parallel_context( | context.set_auto_parallel_context( | ||||
| parallel_mode=ParallelMode.DATA_PARALLEL, | parallel_mode=ParallelMode.DATA_PARALLEL, | ||||
| device_num=MultiAscend.get_group_size(), | device_num=MultiAscend.get_group_size(), | ||||
| @@ -247,14 +239,14 @@ def _setup_parallel_env(): | |||||
| ) | ) | ||||
| def train_parallel(config: TransformerConfig): | |||||
| def train_parallel(config: TransformerConfig, platform: "Ascend"): | |||||
| """ | """ | ||||
| Train model with multi ascend chips. | Train model with multi ascend chips. | ||||
| Args: | Args: | ||||
| config (TransformerConfig): Config for MASS model. | config (TransformerConfig): Config for MASS model. | ||||
| """ | """ | ||||
| _setup_parallel_env() | |||||
| _setup_parallel_env(platform) | |||||
| print(f" | Starting training on {os.getenv('RANK_SIZE', None)} devices.") | print(f" | Starting training on {os.getenv('RANK_SIZE', None)} devices.") | ||||
| @@ -286,10 +278,11 @@ def train_parallel(config: TransformerConfig): | |||||
| _build_training_pipeline(config=config, | _build_training_pipeline(config=config, | ||||
| pre_training_dataset=pre_train_dataset, | pre_training_dataset=pre_train_dataset, | ||||
| fine_tune_dataset=fine_tune_dataset, | fine_tune_dataset=fine_tune_dataset, | ||||
| test_dataset=test_dataset) | |||||
| test_dataset=test_dataset, | |||||
| platform=platform) | |||||
| def train_single(config: TransformerConfig): | |||||
| def train_single(config: TransformerConfig, platform: "Ascend"): | |||||
| """ | """ | ||||
| Train model on single device. | Train model on single device. | ||||
| @@ -316,7 +309,8 @@ def train_single(config: TransformerConfig): | |||||
| _build_training_pipeline(config=config, | _build_training_pipeline(config=config, | ||||
| pre_training_dataset=pre_train_dataset, | pre_training_dataset=pre_train_dataset, | ||||
| fine_tune_dataset=fine_tune_dataset, | fine_tune_dataset=fine_tune_dataset, | ||||
| test_dataset=test_dataset) | |||||
| test_dataset=test_dataset, | |||||
| platform=platform) | |||||
| def _check_args(config): | def _check_args(config): | ||||
| @@ -327,9 +321,20 @@ def _check_args(config): | |||||
| if __name__ == '__main__': | if __name__ == '__main__': | ||||
| args, _ = parser.parse_known_args() | |||||
| device_id = os.getenv('DEVICE_ID', None) | |||||
| if device_id is None: | |||||
| device_id = 0 | |||||
| device_id = int(device_id) | |||||
| context.set_context( | |||||
| mode=context.GRAPH_MODE, | |||||
| device_target=args.platform, | |||||
| reserve_class_name_in_scope=False, | |||||
| device_id=device_id) | |||||
| _rank_size = os.getenv('RANK_SIZE') | _rank_size = os.getenv('RANK_SIZE') | ||||
| args, _ = parser.parse_known_args() | |||||
| _check_args(args.config) | _check_args(args.config) | ||||
| _config = get_config(args.config) | _config = get_config(args.config) | ||||
| @@ -337,6 +342,6 @@ if __name__ == '__main__': | |||||
| context.set_context(save_graphs=_config.save_graphs) | context.set_context(save_graphs=_config.save_graphs) | ||||
| if _rank_size is not None and int(_rank_size) > 1: | if _rank_size is not None and int(_rank_size) > 1: | ||||
| train_parallel(_config) | |||||
| train_parallel(_config, args.platform) | |||||
| else: | else: | ||||
| train_single(_config) | |||||
| train_single(_config, args.platform) | |||||