Compare commits
merge into: Huawei_Technology:master
Huawei_Technology:master
Huawei_Technology:r0.1
Huawei_Technology:r0.2
Huawei_Technology:r0.3
Huawei_Technology:r0.5
Huawei_Technology:r0.6
Huawei_Technology:r0.7
Huawei_Technology:r1.0
Huawei_Technology:r1.1
Huawei_Technology:r1.2
Huawei_Technology:revert-merge-208-master
pull from: Huawei_Technology:r0.1
Huawei_Technology:master
Huawei_Technology:r0.1
Huawei_Technology:r0.2
Huawei_Technology:r0.3
Huawei_Technology:r0.5
Huawei_Technology:r0.6
Huawei_Technology:r0.7
Huawei_Technology:r1.0
Huawei_Technology:r1.1
Huawei_Technology:r1.2
Huawei_Technology:revert-merge-208-master
100 changed files with 696 additions and 8671 deletions
Split View
Diff Options
-
+2 -3.gitee/PULL_REQUEST_TEMPLATE.md
-
+0 -19.github/ISSUE_TEMPLATE/RFC.md
-
+0 -43.github/ISSUE_TEMPLATE/bug-report.md
-
+0 -19.github/ISSUE_TEMPLATE/task-tracking.md
-
+0 -24.github/PULL_REQUEST_TEMPLATE.md
-
+1 -1.gitignore
-
+28 -87README.md
-
+0 -130README_CN.md
-
+5 -248RELEASE.md
-
BINdocs/adversarial_robustness_cn.png
-
BINdocs/adversarial_robustness_en.png
-
BINdocs/differential_privacy_architecture_cn.png
-
BINdocs/differential_privacy_architecture_en.png
-
BINdocs/fuzzer_architecture_cn.png
-
BINdocs/fuzzer_architecture_en.png
-
BINdocs/mindarmour_architecture.png
-
BINdocs/privacy_leakage_cn.png
-
BINdocs/privacy_leakage_en.png
-
+62 -0example/data_processing.py
-
+46 -0example/mnist_demo/README.md
-
+5 -4example/mnist_demo/lenet5_net.py
-
+19 -11example/mnist_demo/mnist_attack_cw.py
-
+20 -11example/mnist_demo/mnist_attack_deepfool.py
-
+27 -19example/mnist_demo/mnist_attack_fgsm.py
-
+24 -19example/mnist_demo/mnist_attack_genetic.py
-
+27 -19example/mnist_demo/mnist_attack_hsja.py
-
+22 -13example/mnist_demo/mnist_attack_jsma.py
-
+30 -21example/mnist_demo/mnist_attack_lbfgs.py
-
+24 -15example/mnist_demo/mnist_attack_nes.py
-
+29 -21example/mnist_demo/mnist_attack_pgd.py
-
+23 -14example/mnist_demo/mnist_attack_pointwise.py
-
+20 -15example/mnist_demo/mnist_attack_pso.py
-
+22 -14example/mnist_demo/mnist_attack_salt_and_pepper.py
-
+144 -0example/mnist_demo/mnist_defense_nad.py
-
+44 -46example/mnist_demo/mnist_evaluation.py
-
+26 -26example/mnist_demo/mnist_similarity_detector.py
-
+46 -23example/mnist_demo/mnist_train.py
-
+0 -38examples/README.md
-
+0 -16examples/__init__.py
-
+0 -24examples/ai_fuzzer/README.md
-
+0 -169examples/ai_fuzzer/fuzz_testing_and_model_enhense.py
-
+0 -85examples/ai_fuzzer/lenet5_mnist_coverage.py
-
+0 -107examples/ai_fuzzer/lenet5_mnist_fuzzing.py
-
+0 -116examples/common/dataset/data_processing.py
-
+0 -0examples/common/networks/__init__.py
-
+0 -0examples/common/networks/lenet5/__init__.py
-
+0 -14examples/common/networks/vgg/__init__.py
-
+0 -45examples/common/networks/vgg/config.py
-
+0 -39examples/common/networks/vgg/crossentropy.py
-
+0 -23examples/common/networks/vgg/linear_warmup.py
-
+0 -0examples/common/networks/vgg/utils/__init__.py
-
+0 -36examples/common/networks/vgg/utils/util.py
-
+0 -219examples/common/networks/vgg/utils/var_init.py
-
+0 -142examples/common/networks/vgg/vgg.py
-
+0 -40examples/common/networks/vgg/warmup_cosine_annealing_lr.py
-
+0 -84examples/common/networks/vgg/warmup_step_lr.py
-
+0 -0examples/community/__init__.py
-
+0 -40examples/model_security/README.md
-
+0 -0examples/model_security/__init__.py
-
+0 -0examples/model_security/model_attacks/__init__.py
-
+0 -0examples/model_security/model_attacks/black_box/__init__.py
-
+0 -47examples/model_security/model_attacks/cv/faster_rcnn/README.md
-
+0 -150examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_genetic.py
-
+0 -135examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_pgd.py
-
+0 -149examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_pso.py
-
+0 -31examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/__init__.py
-
+0 -84examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/anchor_generator.py
-
+0 -166examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/bbox_assign_sample.py
-
+0 -197examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/bbox_assign_sample_stage2.py
-
+0 -428examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/faster_rcnn_r50.py
-
+0 -114examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/fpn_neck.py
-
+0 -201examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/proposal_generator.py
-
+0 -173examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/rcnn.py
-
+0 -250examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/resnet50.py
-
+0 -181examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/roi_align.py
-
+0 -315examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/rpn.py
-
+0 -158examples/model_security/model_attacks/cv/faster_rcnn/src/config.py
-
+0 -505examples/model_security/model_attacks/cv/faster_rcnn/src/dataset.py
-
+0 -42examples/model_security/model_attacks/cv/faster_rcnn/src/lr_schedule.py
-
+0 -184examples/model_security/model_attacks/cv/faster_rcnn/src/network_define.py
-
+0 -227examples/model_security/model_attacks/cv/faster_rcnn/src/util.py
-
+0 -154examples/model_security/model_attacks/cv/yolov3_darknet53/coco_attack_deepfool.py
-
+0 -14examples/model_security/model_attacks/cv/yolov3_darknet53/src/__init__.py
-
+0 -68examples/model_security/model_attacks/cv/yolov3_darknet53/src/config.py
-
+0 -80examples/model_security/model_attacks/cv/yolov3_darknet53/src/convert_weight.py
-
+0 -212examples/model_security/model_attacks/cv/yolov3_darknet53/src/darknet.py
-
+0 -60examples/model_security/model_attacks/cv/yolov3_darknet53/src/distributed_sampler.py
-
+0 -204examples/model_security/model_attacks/cv/yolov3_darknet53/src/initializer.py
-
+0 -80examples/model_security/model_attacks/cv/yolov3_darknet53/src/logger.py
-
+0 -70examples/model_security/model_attacks/cv/yolov3_darknet53/src/loss.py
-
+0 -182examples/model_security/model_attacks/cv/yolov3_darknet53/src/lr_scheduler.py
-
+0 -595examples/model_security/model_attacks/cv/yolov3_darknet53/src/transforms.py
-
+0 -187examples/model_security/model_attacks/cv/yolov3_darknet53/src/util.py
-
+0 -441examples/model_security/model_attacks/cv/yolov3_darknet53/src/yolo.py
-
+0 -192examples/model_security/model_attacks/cv/yolov3_darknet53/src/yolo_dataset.py
-
+0 -0examples/model_security/model_attacks/white_box/__init__.py
-
+0 -111examples/model_security/model_attacks/white_box/mnist_attack_mdi2fgsm.py
-
+0 -0examples/model_security/model_defenses/__init__.py
-
+0 -116examples/model_security/model_defenses/mnist_defense_nad.py
-
+0 -66examples/privacy/README.md
+ 2
- 3
.gitee/PULL_REQUEST_TEMPLATE.md
View File
| @@ -11,7 +11,7 @@ If this is your first time, please read our contributor guidelines: https://gite | |||
| > /kind feature | |||
| **What does this PR do / why do we need it**: | |||
| **What this PR does / why we need it**: | |||
| **Which issue(s) this PR fixes**: | |||
| @@ -21,6 +21,5 @@ Usage: `Fixes #<issue number>`, or `Fixes (paste link of issue)`. | |||
| --> | |||
| Fixes # | |||
| **Special notes for your reviewers**: | |||
| **Special notes for your reviewer**: | |||
+ 0
- 19
.github/ISSUE_TEMPLATE/RFC.md
View File
| @@ -1,19 +0,0 @@ | |||
| --- | |||
| name: RFC | |||
| about: Use this template for the new feature or enhancement | |||
| labels: kind/feature or kind/enhancement | |||
| --- | |||
| ## Background | |||
| - Describe the status of the problem you wish to solve | |||
| - Attach the relevant issue if have | |||
| ## Introduction | |||
| - Describe the general solution, design and/or pseudo-code | |||
| ## Trail | |||
| | No. | Task Description | Related Issue(URL) | | |||
| | --- | ---------------- | ------------------ | | |||
| | 1 | | | | |||
| | 2 | | | | |||
+ 0
- 43
.github/ISSUE_TEMPLATE/bug-report.md
View File
| @@ -1,43 +0,0 @@ | |||
| --- | |||
| name: Bug Report | |||
| about: Use this template for reporting a bug | |||
| labels: kind/bug | |||
| --- | |||
| <!-- Thanks for sending an issue! Here are some tips for you: | |||
| If this is your first time, please read our contributor guidelines: https://github.com/mindspore-ai/mindspore/blob/master/CONTRIBUTING.md | |||
| --> | |||
| ## Environment | |||
| ### Hardware Environment(`Ascend`/`GPU`/`CPU`): | |||
| > Uncomment only one ` /device <>` line, hit enter to put that in a new line, and remove leading whitespaces from that line: | |||
| > | |||
| > `/device ascend`</br> | |||
| > `/device gpu`</br> | |||
| > `/device cpu`</br> | |||
| ### Software Environment: | |||
| - **MindSpore version (source or binary)**: | |||
| - **Python version (e.g., Python 3.7.5)**: | |||
| - **OS platform and distribution (e.g., Linux Ubuntu 16.04)**: | |||
| - **GCC/Compiler version (if compiled from source)**: | |||
| ## Describe the current behavior | |||
| ## Describe the expected behavior | |||
| ## Steps to reproduce the issue | |||
| 1. | |||
| 2. | |||
| 3. | |||
| ## Related log / screenshot | |||
| ## Special notes for this issue | |||
+ 0
- 19
.github/ISSUE_TEMPLATE/task-tracking.md
View File
| @@ -1,19 +0,0 @@ | |||
| --- | |||
| name: Task | |||
| about: Use this template for task tracking | |||
| labels: kind/task | |||
| --- | |||
| ## Task Description | |||
| ## Task Goal | |||
| ## Sub Task | |||
| | No. | Task Description | Issue ID | | |||
| | --- | ---------------- | -------- | | |||
| | 1 | | | | |||
| | 2 | | | | |||
+ 0
- 24
.github/PULL_REQUEST_TEMPLATE.md
View File
| @@ -1,24 +0,0 @@ | |||
| <!-- Thanks for sending a pull request! Here are some tips for you: | |||
| If this is your first time, please read our contributor guidelines: https://github.com/mindspore-ai/mindspore/blob/master/CONTRIBUTING.md | |||
| --> | |||
| **What type of PR is this?** | |||
| > Uncomment only one ` /kind <>` line, hit enter to put that in a new line, and remove leading whitespaces from that line: | |||
| > | |||
| > `/kind bug`</br> | |||
| > `/kind task`</br> | |||
| > `/kind feature`</br> | |||
| **What does this PR do / why do we need it**: | |||
| **Which issue(s) this PR fixes**: | |||
| <!-- | |||
| *Automatically closes linked issue when PR is merged. | |||
| Usage: `Fixes #<issue number>`, or `Fixes (paste link of issue)`. | |||
| --> | |||
| Fixes # | |||
| **Special notes for your reviewers**: | |||
+ 1
- 1
.gitignore
View File
| @@ -13,7 +13,7 @@ build/ | |||
| dist/ | |||
| local_script/ | |||
| example/dataset/ | |||
| example/mnist_demo/MNIST/ | |||
| example/mnist_demo/MNIST_unzip/ | |||
| example/mnist_demo/trained_ckpt_file/ | |||
| example/mnist_demo/model/ | |||
| example/cifar_demo/model/ | |||
+ 28
- 87
README.md
View File
| @@ -1,112 +1,53 @@ | |||
| # MindArmour | |||
| <!-- TOC --> | |||
| - [MindArmour](#mindarmour) | |||
| - [What is MindArmour](#what-is-mindarmour) | |||
| - [Adversarial Robustness Module](#adversarial-robustness-module) | |||
| - [Fuzz Testing Module](#fuzz-testing-module) | |||
| - [Privacy Protection and Evaluation Module](#privacy-protection-and-evaluation-module) | |||
| - [Differential Privacy Training Module](#differential-privacy-training-module) | |||
| - [Privacy Leakage Evaluation Module](#privacy-leakage-evaluation-module) | |||
| - [Starting](#starting) | |||
| - [System Environment Information Confirmation](#system-environment-information-confirmation) | |||
| - [Installation](#installation) | |||
| - [Installation by Source Code](#installation-by-source-code) | |||
| - [Installation by pip](#installation-by-pip) | |||
| - [Installation Verification](#installation-verification) | |||
| - [Docs](#docs) | |||
| - [Community](#community) | |||
| - [Contributing](#contributing) | |||
| - [Release Notes](#release-notes) | |||
| - [License](#license) | |||
| <!-- /TOC --> | |||
| [查看中文](./README_CN.md) | |||
| - [What is MindArmour](#what-is-mindarmour) | |||
| - [Setting up](#setting-up-mindarmour) | |||
| - [Docs](#docs) | |||
| - [Community](#community) | |||
| - [Contributing](#contributing) | |||
| - [Release Notes](#release-notes) | |||
| - [License](#license) | |||
| ## What is MindArmour | |||
| MindArmour focus on security and privacy of artificial intelligence. MindArmour can be used as a tool box for MindSpore users to enhance model security and trustworthiness and protect privacy data. MindArmour contains three module: Adversarial Robustness Module, Fuzz Testing Module, Privacy Protection and Evaluation Module. | |||
| A tool box for MindSpore users to enhance model security and trustworthiness. | |||
| ### Adversarial Robustness Module | |||
| MindArmour is designed for adversarial examples, including four submodule: adversarial examples generation, adversarial example detection, model defense and evaluation. The architecture is shown as follow: | |||
| Adversarial robustness module is designed for evaluating the robustness of the model against adversarial examples, and provides model enhancement methods to enhance the model's ability to resist the adversarial attack and improve the model's robustness. | |||
| This module includes four submodule: Adversarial Examples Generation, Adversarial Examples Detection, Model Defense and Evaluation. | |||
|  | |||
| The architecture is shown as follow: | |||
| ## Setting up MindArmour | |||
|  | |||
| ### Dependencies | |||
| ### Fuzz Testing Module | |||
| Fuzz Testing module is a security test for AI models. We introduce neuron coverage gain as a guide to fuzz testing according to the characteristics of neural networks. | |||
| Fuzz testing is guided to generate samples in the direction of increasing neuron coverage rate, so that the input can activate more neurons and neuron values have a wider distribution range to fully test neural networks and explore different types of model output results and wrong behaviors. | |||
| The architecture is shown as follow: | |||
|  | |||
| ### Privacy Protection and Evaluation Module | |||
| Privacy Protection and Evaluation Module includes two modules: Differential Privacy Training Module and Privacy Leakage Evaluation Module. | |||
| #### Differential Privacy Training Module | |||
| Differential Privacy Training Module implements the differential privacy optimizer. Currently, `SGD`, `Momentum` and `Adam` are supported. They are differential privacy optimizers based on the Gaussian mechanism. | |||
| This mechanism supports both non-adaptive and adaptive policy. Rényi differential privacy (RDP) and Zero-Concentrated differential privacy(ZCDP) are provided to monitor differential privacy budgets. | |||
| The architecture is shown as follow: | |||
|  | |||
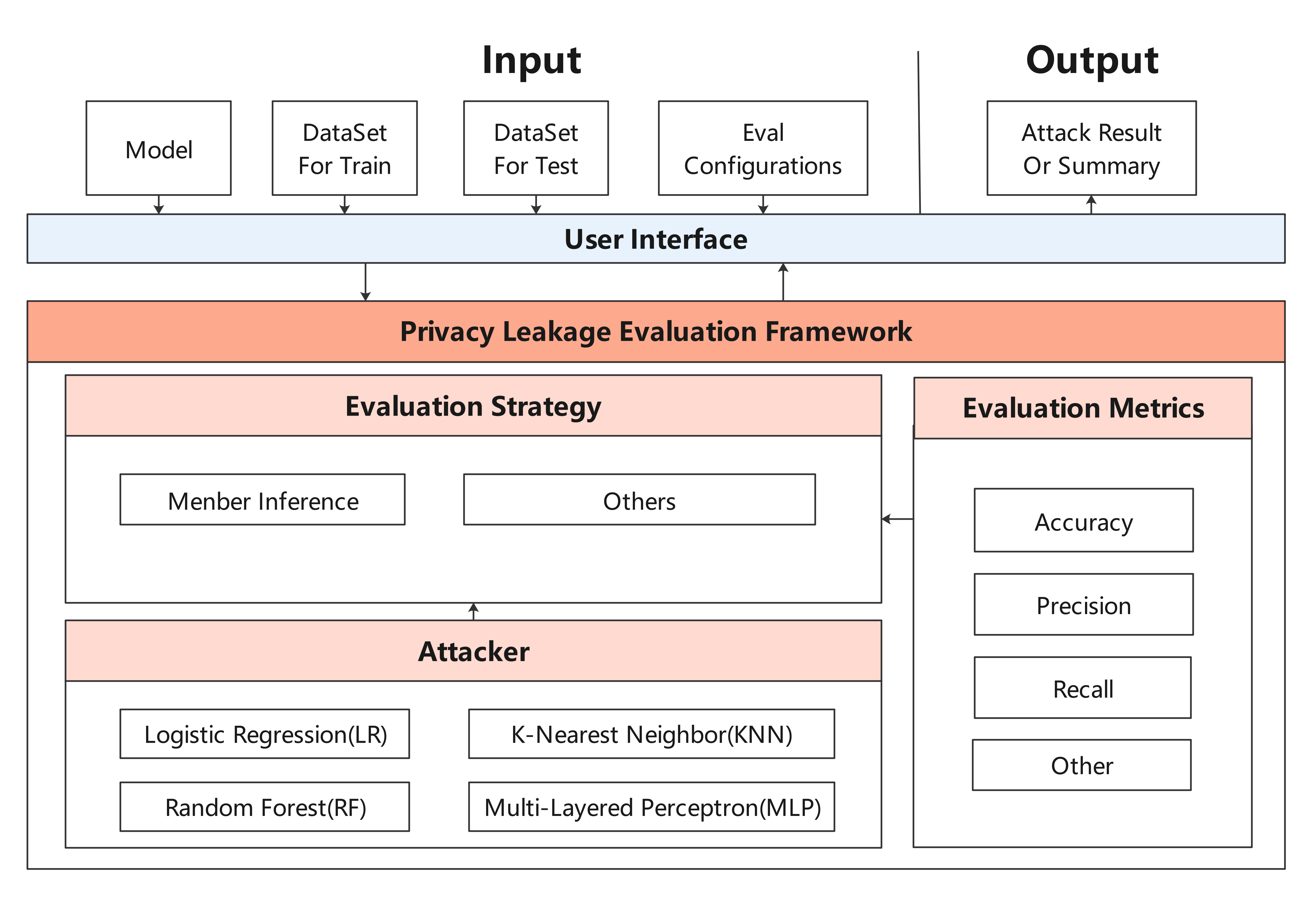
| #### Privacy Leakage Evaluation Module | |||
| Privacy Leakage Evaluation Module is used to assess the risk of a model revealing user privacy. The privacy data security of the deep learning model is evaluated by using membership inference method to infer whether the sample belongs to training dataset. | |||
| The architecture is shown as follow: | |||
|  | |||
| ## Starting | |||
| ### System Environment Information Confirmation | |||
| - The hardware platform should be Ascend, GPU or CPU. | |||
| - See our [MindSpore Installation Guide](https://www.mindspore.cn/install) to install MindSpore. | |||
| The versions of MindArmour and MindSpore must be consistent. | |||
| - All other dependencies are included in [setup.py](https://gitee.com/mindspore/mindarmour/blob/master/setup.py). | |||
| This library uses MindSpore to accelerate graph computations performed by many machine learning models. Therefore, installing MindSpore is a pre-requisite. All other dependencies are included in `setup.py`. | |||
| ### Installation | |||
| #### Installation by Source Code | |||
| #### Installation for development | |||
| 1. Download source code from Gitee. | |||
| ```bash | |||
| git clone https://gitee.com/mindspore/mindarmour.git | |||
| ``` | |||
| 2. Compile and install in MindArmour directory. | |||
| ```bash | |||
| cd mindarmour | |||
| python setup.py install | |||
| ``` | |||
| ```bash | |||
| git clone https://gitee.com/mindspore/mindarmour.git | |||
| ``` | |||
| #### Installation by pip | |||
| 2. Compile and install in MindArmour directory. | |||
| ```bash | |||
| pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/{version}/MindArmour/{arch}/mindarmour-{version}-cp37-cp37m-linux_{arch}.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple | |||
| $ cd mindarmour | |||
| $ python setup.py install | |||
| ``` | |||
| > - When the network is connected, dependency items are automatically downloaded during .whl package installation. (For details about other dependency items, see [setup.py](https://gitee.com/mindspore/mindarmour/blob/master/setup.py)). In other cases, you need to manually install dependency items. | |||
| > - `{version}` denotes the version of MindArmour. For example, when you are downloading MindArmour 1.0.1, `{version}` should be 1.0.1. | |||
| > - `{arch}` denotes the system architecture. For example, the Linux system you are using is x86 architecture 64-bit, `{arch}` should be `x86_64`. If the system is ARM architecture 64-bit, then it should be `aarch64`. | |||
| #### `Pip` installation | |||
| 1. Download whl package from [MindSpore website](https://www.mindspore.cn/versions/en), then run the following command: | |||
| ### Installation Verification | |||
| ``` | |||
| pip install mindarmour-{version}-cp37-cp37m-linux_{arch}.whl | |||
| ``` | |||
| Successfully installed, if there is no error message such as `No module named 'mindarmour'` when execute the following command: | |||
| 2. Successfully installed, if there is no error message such as `No module named 'mindarmour'` when execute the following command: | |||
| ```bash | |||
| python -c 'import mindarmour' | |||
| @@ -118,7 +59,7 @@ Guidance on installation, tutorials, API, see our [User Documentation](https://g | |||
| ## Community | |||
| [MindSpore Slack](https://join.slack.com/t/mindspore/shared_invite/enQtOTcwMTIxMDI3NjM0LTNkMWM2MzI5NjIyZWU5ZWQ5M2EwMTQ5MWNiYzMxOGM4OWFhZjI4M2E5OGI2YTg3ODU1ODE2Njg1MThiNWI3YmQ) - Ask questions and find answers. | |||
| - [MindSpore Slack](https://join.slack.com/t/mindspore/shared_invite/enQtOTcwMTIxMDI3NjM0LTNkMWM2MzI5NjIyZWU5ZWQ5M2EwMTQ5MWNiYzMxOGM4OWFhZjI4M2E5OGI2YTg3ODU1ODE2Njg1MThiNWI3YmQ) - Ask questions and find answers. | |||
| ## Contributing | |||
+ 0
- 130
README_CN.md
View File
| @@ -1,130 +0,0 @@ | |||
| # MindArmour | |||
| <!-- TOC --> | |||
| - [MindArmour](#mindarmour) | |||
| - [简介](#简介) | |||
| - [对抗样本鲁棒性模块](#对抗样本鲁棒性模块) | |||
| - [Fuzz Testing模块](#fuzz-testing模块) | |||
| - [隐私保护模块](#隐私保护模块) | |||
| - [差分隐私训练模块](#差分隐私训练模块) | |||
| - [隐私泄露评估模块](#隐私泄露评估模块) | |||
| - [开始](#开始) | |||
| - [确认系统环境信息](#确认系统环境信息) | |||
| - [安装](#安装) | |||
| - [源码安装](#源码安装) | |||
| - [pip安装](#pip安装) | |||
| - [验证是否成功安装](#验证是否成功安装) | |||
| - [文档](#文档) | |||
| - [社区](#社区) | |||
| - [贡献](#贡献) | |||
| - [版本](#版本) | |||
| - [版权](#版权) | |||
| <!-- /TOC --> | |||
| [View English](./README.md) | |||
| ## 简介 | |||
| MindArmour关注AI的安全和隐私问题。致力于增强模型的安全可信、保护用户的数据隐私。主要包含3个模块:对抗样本鲁棒性模块、Fuzz Testing模块、隐私保护与评估模块。 | |||
| ### 对抗样本鲁棒性模块 | |||
| 对抗样本鲁棒性模块用于评估模型对于对抗样本的鲁棒性,并提供模型增强方法用于增强模型抗对抗样本攻击的能力,提升模型鲁棒性。对抗样本鲁棒性模块包含了4个子模块:对抗样本的生成、对抗样本的检测、模型防御、攻防评估。 | |||
| 对抗样本鲁棒性模块的架构图如下: | |||
|  | |||
| ### Fuzz Testing模块 | |||
| Fuzz Testing模块是针对AI模型的安全测试,根据神经网络的特点,引入神经元覆盖率,作为Fuzz测试的指导,引导Fuzzer朝着神经元覆盖率增加的方向生成样本,让输入能够激活更多的神经元,神经元值的分布范围更广,以充分测试神经网络,探索不同类型的模型输出结果和错误行为。 | |||
| Fuzz Testing模块的架构图如下: | |||
|  | |||
| ### 隐私保护模块 | |||
| 隐私保护模块包含差分隐私训练与隐私泄露评估。 | |||
| #### 差分隐私训练模块 | |||
| 差分隐私训练包括动态或者非动态的差分隐私`SGD`、`Momentum`、`Adam`优化器,噪声机制支持高斯分布噪声、拉普拉斯分布噪声,差分隐私预算监测包含ZCDP、RDP。 | |||
| 差分隐私的架构图如下: | |||
|  | |||
| #### 隐私泄露评估模块 | |||
| 隐私泄露评估模块用于评估模型泄露用户隐私的风险。利用成员推理方法来推测样本是否属于用户训练数据集,从而评估深度学习模型的隐私数据安全。 | |||
| 隐私泄露评估模块框架图如下: | |||
|  | |||
| ## 开始 | |||
| ### 确认系统环境信息 | |||
| - 硬件平台为Ascend、GPU或CPU。 | |||
| - 参考[MindSpore安装指南](https://www.mindspore.cn/install),完成MindSpore的安装。 | |||
| MindArmour与MindSpore的版本需保持一致。 | |||
| - 其余依赖请参见[setup.py](https://gitee.com/mindspore/mindarmour/blob/master/setup.py)。 | |||
| ### 安装 | |||
| #### 源码安装 | |||
| 1. 从Gitee下载源码。 | |||
| ```bash | |||
| git clone https://gitee.com/mindspore/mindarmour.git | |||
| ``` | |||
| 2. 在源码根目录下,执行如下命令编译并安装MindArmour。 | |||
| ```bash | |||
| cd mindarmour | |||
| python setup.py install | |||
| ``` | |||
| #### pip安装 | |||
| ```bash | |||
| pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/{version}/MindArmour/{arch}/mindarmour-{version}-cp37-cp37m-linux_{arch}.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple | |||
| ``` | |||
| > - 在联网状态下,安装whl包时会自动下载MindArmour安装包的依赖项(依赖项详情参见[setup.py](https://gitee.com/mindspore/mindarmour/blob/master/setup.py)),其余情况需自行安装。 | |||
| > - `{version}`表示MindArmour版本号,例如下载1.0.1版本MindArmour时,`{version}`应写为1.0.1。 | |||
| > - `{arch}`表示系统架构,例如使用的Linux系统是x86架构64位时,`{arch}`应写为`x86_64`。如果系统是ARM架构64位,则写为`aarch64`。 | |||
| ### 验证是否成功安装 | |||
| 执行如下命令,如果没有报错`No module named 'mindarmour'`,则说明安装成功。 | |||
| ```bash | |||
| python -c 'import mindarmour' | |||
| ``` | |||
| ## 文档 | |||
| 安装指导、使用教程、API,请参考[用户文档](https://gitee.com/mindspore/docs)。 | |||
| ## 社区 | |||
| 社区问答:[MindSpore Slack](https://join.slack.com/t/mindspore/shared_invite/enQtOTcwMTIxMDI3NjM0LTNkMWM2MzI5NjIyZWU5ZWQ5M2EwMTQ5MWNiYzMxOGM4OWFhZjI4M2E5OGI2YTg3ODU1ODE2Njg1MThiNWI3YmQ)。 | |||
| ## 贡献 | |||
| 欢迎参与社区贡献,详情参考[Contributor Wiki](https://gitee.com/mindspore/mindspore/blob/master/CONTRIBUTING.md)。 | |||
| ## 版本 | |||
| 版本信息参考:[RELEASE](RELEASE.md)。 | |||
| ## 版权 | |||
| [Apache License 2.0](LICENSE) | |||
+ 5
- 248
RELEASE.md
View File
| @@ -1,254 +1,11 @@ | |||
| # MindArmour 1.2.0 | |||
| ## MindArmour 1.2.0 Release Notes | |||
| ### Major Features and Improvements | |||
| #### Privacy | |||
| * [STABLE]Tailored-based privacy protection technology (Pynative) | |||
| * [STABLE]Model Inversion. Reverse analysis technology of privacy information | |||
| ### API Change | |||
| #### Backwards Incompatible Change | |||
| ##### C++ API | |||
| [Modify] ... | |||
| [Add] ... | |||
| [Delete] ... | |||
| ##### Java API | |||
| [Add] ... | |||
| #### Deprecations | |||
| ##### C++ API | |||
| ##### Java API | |||
| ### Bug fixes | |||
| [BUGFIX] ... | |||
| ### Contributors | |||
| Thanks goes to these wonderful people: | |||
| han.yin | |||
| # MindArmour 1.1.0 Release Notes | |||
| ## MindArmour | |||
| ### Major Features and Improvements | |||
| * [STABLE] Attack capability of the Object Detection models. | |||
| * Some white-box adversarial attacks, such as [iterative] gradient method and DeepFool now can be applied to Object Detection models. | |||
| * Some black-box adversarial attacks, such as PSO and Genetic Attack now can be applied to Object Detection models. | |||
| ### Backwards Incompatible Change | |||
| #### Python API | |||
| #### C++ API | |||
| ### Deprecations | |||
| #### Python API | |||
| #### C++ API | |||
| ### New Features | |||
| #### Python API | |||
| #### C++ API | |||
| ### Improvements | |||
| #### Python API | |||
| #### C++ API | |||
| ### Bug fixes | |||
| #### Python API | |||
| #### C++ API | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Xiulang Jin, Zhidan Liu, Luobin Liu and Liu Liu. | |||
| Contributions of any kind are welcome! | |||
| # Release 1.0.0 | |||
| ## Major Features and Improvements | |||
| ### Differential privacy model training | |||
| * Privacy leakage evaluation. | |||
| * Parameter verification enhancement. | |||
| * Support parallel computing. | |||
| ### Model robustness evaluation | |||
| * Fuzzing based Adversarial Robustness testing. | |||
| * Parameter verification enhancement. | |||
| ### Other | |||
| * Api & Directory Structure | |||
| * Adjusted the directory structure based on different features. | |||
| * Optimize the structure of examples. | |||
| ## Bugfixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Xiulang Jin, Zhidan Liu and Luobin Liu. | |||
| Contributions of any kind are welcome! | |||
| # Release 0.7.0-beta | |||
| ## Major Features and Improvements | |||
| ### Differential privacy model training | |||
| * Privacy leakage evaluation. | |||
| * Using Membership inference to evaluate the effectiveness of privacy-preserving techniques for AI. | |||
| ### Model robustness evaluation | |||
| * Fuzzing based Adversarial Robustness testing. | |||
| * Coverage-guided test set generation. | |||
| ## Bugfixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Xiulang Jin, Zhidan Liu, Luobin Liu and Huanhuan Zheng. | |||
| Contributions of any kind are welcome! | |||
| # Release 0.6.0-beta | |||
| ## Major Features and Improvements | |||
| ### Differential privacy model training | |||
| * Optimizers with differential privacy | |||
| * Differential privacy model training now supports some new policies. | |||
| * Adaptive Norm policy is supported. | |||
| * Adaptive Noise policy with exponential decrease is supported. | |||
| * Differential Privacy Training Monitor | |||
| * A new monitor is supported using zCDP as its asymptotic budget estimator. | |||
| ## Bugfixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Huanhuan Zheng, XiuLang jin, Zhidan liu. | |||
| Contributions of any kind are welcome. | |||
| # Release 0.5.0-beta | |||
| ## Major Features and Improvements | |||
| ### Differential privacy model training | |||
| * Optimizers with differential privacy | |||
| * Differential privacy model training now supports both Pynative mode and graph mode. | |||
| * Graph mode is recommended for its performance. | |||
| ## Bugfixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Huanhuan Zheng, Xiulang Jin, Zhidan Liu. | |||
| Contributions of any kind are welcome! | |||
| # Release 0.3.0-alpha | |||
| ## Major Features and Improvements | |||
| ### Differential Privacy Model Training | |||
| Differential Privacy is coming! By using Differential-Privacy-Optimizers, one can still train a model as usual, while the trained model preserved the privacy of training dataset, satisfying the definition of | |||
| differential privacy with proper budget. | |||
| * Optimizers with Differential Privacy([PR23](https://gitee.com/mindspore/mindarmour/pulls/23), [PR24](https://gitee.com/mindspore/mindarmour/pulls/24)) | |||
| * Some common optimizers now have a differential privacy version (SGD/Adam). We are adding more. | |||
| * Automatically and adaptively add Gaussian Noise during training to achieve Differential Privacy. | |||
| * Automatically stop training when Differential Privacy Budget exceeds. | |||
| * Differential Privacy Monitor([PR22](https://gitee.com/mindspore/mindarmour/pulls/22)) | |||
| * Calculate overall budget consumed during training, indicating the ultimate protect effect. | |||
| ## Bug fixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Huanhuan Zheng, Zhidan Liu, Xiulang Jin | |||
| Contributions of any kind are welcome! | |||
| # Release 0.2.0-alpha | |||
| ## Major Features and Improvements | |||
| * Add a white-box attack method: M-DI2-FGSM([PR14](https://gitee.com/mindspore/mindarmour/pulls/14)). | |||
| * Add three neuron coverage metrics: KMNCov, NBCov, SNACov([PR12](https://gitee.com/mindspore/mindarmour/pulls/12)). | |||
| * Add a coverage-guided fuzzing test framework for deep neural networks([PR13](https://gitee.com/mindspore/mindarmour/pulls/13)). | |||
| * Update the MNIST Lenet5 examples. | |||
| * Remove some duplicate code. | |||
| ## Bug fixes | |||
| ## Contributors | |||
| Thanks goes to these wonderful people: | |||
| Liu Liu, Huanhuan Zheng, Zhidan Liu, Xiulang Jin | |||
| Contributions of any kind are welcome! | |||
| # Release 0.1.0-alpha | |||
| Initial release of MindArmour. | |||
| ## Major Features | |||
| * Support adversarial attack and defense on the platform of MindSpore. | |||
| * Include 13 white-box and 7 black-box attack methods. | |||
| * Provide 5 detection algorithms to detect attacking in multiple way. | |||
| * Provide adversarial training to enhance model security. | |||
| * Provide 6 evaluation metrics for attack methods and 9 evaluation metrics for defense methods. | |||
| - Support adversarial attack and defense on the platform of MindSpore. | |||
| - Include 13 white-box and 7 black-box attack methods. | |||
| - Provide 5 detection algorithms to detect attacking in multiple way. | |||
| - Provide adversarial training to enhance model security. | |||
| - Provide 6 evaluation metrics for attack methods and 9 evaluation metrics for defense methods. | |||
BIN
docs/adversarial_robustness_cn.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 4705 | Height: 2601 | Size: 238 kB |
BIN
docs/adversarial_robustness_en.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 4737 | Height: 2705 | Size: 297 kB |
BIN
docs/differential_privacy_architecture_cn.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 3892 | Height: 2072 | Size: 236 kB |
BIN
docs/differential_privacy_architecture_en.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 4077 | Height: 2065 | Size: 218 kB |
BIN
docs/fuzzer_architecture_cn.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 6041 | Height: 3201 | Size: 394 kB |
BIN
docs/fuzzer_architecture_en.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 6097 | Height: 3233 | Size: 394 kB |
BIN
docs/mindarmour_architecture.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 699 | Height: 546 | Size: 28 kB |
BIN
docs/privacy_leakage_cn.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 4721 | Height: 3209 | Size: 334 kB |
BIN
docs/privacy_leakage_en.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 4729 | Height: 3233 | Size: 371 kB |
+ 62
- 0
example/data_processing.py
View File
| @@ -0,0 +1,62 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import mindspore.dataset as ds | |||
| import mindspore.dataset.transforms.vision.c_transforms as CV | |||
| import mindspore.dataset.transforms.c_transforms as C | |||
| from mindspore.dataset.transforms.vision import Inter | |||
| import mindspore.common.dtype as mstype | |||
| def generate_mnist_dataset(data_path, batch_size=32, repeat_size=1, | |||
| num_parallel_workers=1, sparse=True): | |||
| """ | |||
| create dataset for training or testing | |||
| """ | |||
| # define dataset | |||
| ds1 = ds.MnistDataset(data_path) | |||
| # define operation parameters | |||
| resize_height, resize_width = 32, 32 | |||
| rescale = 1.0 / 255.0 | |||
| shift = 0.0 | |||
| # define map operations | |||
| resize_op = CV.Resize((resize_height, resize_width), | |||
| interpolation=Inter.LINEAR) | |||
| rescale_op = CV.Rescale(rescale, shift) | |||
| hwc2chw_op = CV.HWC2CHW() | |||
| type_cast_op = C.TypeCast(mstype.int32) | |||
| one_hot_enco = C.OneHot(10) | |||
| # apply map operations on images | |||
| if not sparse: | |||
| ds1 = ds1.map(input_columns="label", operations=one_hot_enco, | |||
| num_parallel_workers=num_parallel_workers) | |||
| type_cast_op = C.TypeCast(mstype.float32) | |||
| ds1 = ds1.map(input_columns="label", operations=type_cast_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=resize_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=rescale_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=hwc2chw_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| # apply DatasetOps | |||
| buffer_size = 10000 | |||
| ds1 = ds1.shuffle(buffer_size=buffer_size) | |||
| ds1 = ds1.batch(batch_size, drop_remainder=True) | |||
| ds1 = ds1.repeat(repeat_size) | |||
| return ds1 | |||
+ 46
- 0
example/mnist_demo/README.md
View File
| @@ -0,0 +1,46 @@ | |||
| # mnist demo | |||
| ## Introduction | |||
| The MNIST database of handwritten digits, available from this page, has a training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger set available from MNIST. The digits have been size-normalized and centered in a fixed-size image. | |||
| ## run demo | |||
| ### 1. download dataset | |||
| ```sh | |||
| $ cd example/mnist_demo | |||
| $ mkdir MNIST_unzip | |||
| $ cd MNIST_unzip | |||
| $ mkdir train | |||
| $ mkdir test | |||
| $ cd train | |||
| $ wget "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz" | |||
| $ wget "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz" | |||
| $ gzip train-images-idx3-ubyte.gz -d | |||
| $ gzip train-labels-idx1-ubyte.gz -d | |||
| $ cd ../test | |||
| $ wget "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz" | |||
| $ wget "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz" | |||
| $ gzip t10k-images-idx3-ubyte.gz -d | |||
| $ gzip t10k-images-idx3-ubyte.gz -d | |||
| $ cd ../../ | |||
| ``` | |||
| ### 1. trian model | |||
| ```sh | |||
| $ python mnist_train.py | |||
| ``` | |||
| ### 2. run attack test | |||
| ```sh | |||
| $ mkdir out.data | |||
| $ python mnist_attack_jsma.py | |||
| ``` | |||
| ### 3. run defense/detector test | |||
| ```sh | |||
| $ python mnist_defense_nad.py | |||
| $ python mnist_similarity_detector.py | |||
| ``` | |||
examples/common/networks/lenet5/lenet5_net.py → example/mnist_demo/lenet5_net.py
View File
| @@ -11,7 +11,8 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| from mindspore import nn | |||
| import mindspore.nn as nn | |||
| import mindspore.ops.operations as P | |||
| from mindspore.common.initializer import TruncatedNormal | |||
| @@ -29,7 +30,7 @@ def fc_with_initialize(input_channels, out_channels): | |||
| def weight_variable(): | |||
| return TruncatedNormal(0.05) | |||
| return TruncatedNormal(0.2) | |||
| class LeNet5(nn.Cell): | |||
| @@ -45,7 +46,7 @@ class LeNet5(nn.Cell): | |||
| self.fc3 = fc_with_initialize(84, 10) | |||
| self.relu = nn.ReLU() | |||
| self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) | |||
| self.flatten = nn.Flatten() | |||
| self.reshape = P.Reshape() | |||
| def construct(self, x): | |||
| x = self.conv1(x) | |||
| @@ -54,7 +55,7 @@ class LeNet5(nn.Cell): | |||
| x = self.conv2(x) | |||
| x = self.relu(x) | |||
| x = self.max_pool2d(x) | |||
| x = self.flatten(x) | |||
| x = self.reshape(x, (-1, 16*5*5)) | |||
| x = self.fc1(x) | |||
| x = self.relu(x) | |||
| x = self.fc2(x) | |||
examples/model_security/model_attacks/white_box/mnist_attack_cw.py → example/mnist_demo/mnist_attack_cw.py
View File
| @@ -11,8 +11,10 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| @@ -20,30 +22,38 @@ from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.adv_robustness.attacks import CarliniWagnerL2Attack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.carlini_wagner import CarliniWagnerL2Attack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'CW_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_carlini_wagner_attack(): | |||
| """ | |||
| CW-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -54,7 +64,7 @@ def test_carlini_wagner_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -105,6 +115,4 @@ def test_carlini_wagner_attack(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_carlini_wagner_attack() | |||
examples/model_security/model_attacks/white_box/mnist_attack_deepfool.py → example/mnist_demo/mnist_attack_deepfool.py
View File
| @@ -11,8 +11,10 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| @@ -20,30 +22,39 @@ from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.adv_robustness.attacks.deep_fool import DeepFool | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.deep_fool import DeepFool | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'DeepFool_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_deepfool_attack(): | |||
| """ | |||
| DeepFool-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -54,7 +65,7 @@ def test_deepfool_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -106,6 +117,4 @@ def test_deepfool_attack(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_deepfool_attack() | |||
examples/model_security/model_attacks/white_box/mnist_attack_fgsm.py → example/mnist_demo/mnist_attack_fgsm.py
View File
| @@ -11,42 +11,53 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindarmour.adv_robustness.attacks import FastGradientSignMethod | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.gradient_method import FastGradientSignMethod | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'FGSM_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_fast_gradient_sign_method(): | |||
| """ | |||
| FGSM-Attack test for CPU device. | |||
| FGSM-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size) | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| @@ -55,7 +66,7 @@ def test_fast_gradient_sign_method(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -67,16 +78,15 @@ def test_fast_gradient_sign_method(): | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| true_labels = np.argmax(np.concatenate(test_labels), axis=1) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| # attacking | |||
| loss = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| attack = FastGradientSignMethod(net, eps=0.3, loss_fn=loss) | |||
| attack = FastGradientSignMethod(net, eps=0.3) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| true_labels, batch_size=32) | |||
| np.concatenate(test_labels), batch_size=32) | |||
| stop_time = time.clock() | |||
| np.save('./adv_data', adv_data) | |||
| pred_logits_adv = model.predict(Tensor(adv_data)).asnumpy() | |||
| @@ -86,7 +96,7 @@ def test_fast_gradient_sign_method(): | |||
| accuracy_adv = np.mean(np.equal(pred_labels_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", accuracy_adv) | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| np.eye(10)[true_labels], | |||
| np.concatenate(test_labels), | |||
| adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| @@ -106,6 +116,4 @@ def test_fast_gradient_sign_method(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_fast_gradient_sign_method() | |||
examples/model_security/model_attacks/black_box/mnist_attack_genetic.py → example/mnist_demo/mnist_attack_genetic.py
View File
| @@ -11,24 +11,29 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| from scipy.special import softmax | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.adv_robustness.attacks.black.black_model import BlackModel | |||
| from mindarmour.adv_robustness.attacks.black.genetic_attack import GeneticAttack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.black.genetic_attack import GeneticAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'Genetic_Attack' | |||
| @@ -41,25 +46,27 @@ class ModelToBeAttacked(BlackModel): | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| # Adapt to the input shape requirements of the target network if inputs is only one image. | |||
| if len(inputs.shape) == 3: | |||
| inputs = np.expand_dims(inputs, axis=0) | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_genetic_attack_on_mnist(): | |||
| """ | |||
| Genetic-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -70,7 +77,7 @@ def test_genetic_attack_on_mnist(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -87,11 +94,11 @@ def test_genetic_attack_on_mnist(): | |||
| # attacking | |||
| attack = GeneticAttack(model=model, pop_size=6, mutation_rate=0.05, | |||
| per_bounds=0.4, step_size=0.25, temp=0.1, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| sparse=True) | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i, true_l in enumerate(true_labels): | |||
| if targeted_labels[i] == true_l: | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| start_time = time.clock() | |||
| success_list, adv_data, query_list = attack.generate( | |||
| @@ -128,6 +135,4 @@ def test_genetic_attack_on_mnist(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_genetic_attack_on_mnist() | |||
examples/model_security/model_attacks/black_box/mnist_attack_hsja.py → example/mnist_demo/mnist_attack_hsja.py
View File
| @@ -11,21 +11,27 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks import HopSkipJumpAttack | |||
| from mindarmour.attacks.black.hop_skip_jump_attack import HopSkipJumpAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'HopSkipJumpAttack' | |||
| @@ -58,26 +64,31 @@ def random_target_labels(true_labels): | |||
| def create_target_images(dataset, data_labels, target_labels): | |||
| res = [] | |||
| for label in target_labels: | |||
| for data_label, data in zip(data_labels, dataset): | |||
| if data_label == label: | |||
| res.append(data) | |||
| for i in range(len(data_labels)): | |||
| if data_labels[i] == label: | |||
| res.append(dataset[i]) | |||
| break | |||
| return np.array(res) | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_hsja_mnist_attack(): | |||
| """ | |||
| hsja-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| net.set_train(False) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -88,7 +99,7 @@ def test_hsja_mnist_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -115,9 +126,9 @@ def test_hsja_mnist_attack(): | |||
| target_images = create_target_images(test_images, predict_labels, | |||
| target_labels) | |||
| attack.set_target_images(target_images) | |||
| success_list, adv_data, _ = attack.generate(test_images, target_labels) | |||
| success_list, adv_data, query_list = attack.generate(test_images, target_labels) | |||
| else: | |||
| success_list, adv_data, _ = attack.generate(test_images, None) | |||
| success_list, adv_data, query_list = attack.generate(test_images, None) | |||
| adv_datas = [] | |||
| gts = [] | |||
| @@ -125,18 +136,15 @@ def test_hsja_mnist_attack(): | |||
| if success: | |||
| adv_datas.append(adv) | |||
| gts.append(gt) | |||
| if gts: | |||
| if len(gts) > 0: | |||
| adv_datas = np.concatenate(np.asarray(adv_datas), axis=0) | |||
| gts = np.asarray(gts) | |||
| pred_logits_adv = model.predict(adv_datas) | |||
| pred_lables_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_lables_adv, gts)) | |||
| mis_rate = (1 - accuracy_adv)*(len(adv_datas) / len(success_list)) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| mis_rate) | |||
| accuracy_adv) | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_hsja_mnist_attack() | |||
examples/model_security/model_attacks/white_box/mnist_attack_jsma.py → example/mnist_demo/mnist_attack_jsma.py
View File
| @@ -11,8 +11,10 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| @@ -20,30 +22,39 @@ from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.adv_robustness.attacks import JSMAAttack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.jsma import JSMAAttack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'JSMA_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_jsma_attack(): | |||
| """ | |||
| JSMA-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -54,7 +65,7 @@ def test_jsma_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -68,8 +79,8 @@ def test_jsma_attack(): | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i, true_l in enumerate(true_labels): | |||
| if targeted_labels[i] == true_l: | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %g", accuracy) | |||
| @@ -110,6 +121,4 @@ def test_jsma_attack(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_jsma_attack() | |||
examples/model_security/model_attacks/white_box/mnist_attack_lbfgs.py → example/mnist_demo/mnist_attack_lbfgs.py
View File
| @@ -11,42 +11,52 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindarmour.adv_robustness.attacks import LBFGS | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.lbfgs import LBFGS | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'LBFGS_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_lbfgs_attack(): | |||
| """ | |||
| LBFGS-Attack test for CPU device. | |||
| LBFGS-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size, sparse=False) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| @@ -55,7 +65,7 @@ def test_lbfgs_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -67,7 +77,7 @@ def test_lbfgs_attack(): | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| true_labels = np.argmax(np.concatenate(test_labels), axis=1) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| @@ -75,13 +85,13 @@ def test_lbfgs_attack(): | |||
| is_targeted = True | |||
| if is_targeted: | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)).astype(np.int32) | |||
| for i, true_l in enumerate(true_labels): | |||
| if targeted_labels[i] == true_l: | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| else: | |||
| targeted_labels = true_labels.astype(np.int32) | |||
| loss = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| attack = LBFGS(net, is_targeted=is_targeted, loss_fn=loss) | |||
| targeted_labels = np.eye(10)[targeted_labels].astype(np.float32) | |||
| attack = LBFGS(net, is_targeted=is_targeted) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| targeted_labels, | |||
| @@ -96,11 +106,12 @@ def test_lbfgs_attack(): | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", | |||
| accuracy_adv) | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| np.eye(10)[true_labels], | |||
| np.concatenate(test_labels), | |||
| adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv, | |||
| targeted=is_targeted, | |||
| target_label=targeted_labels) | |||
| target_label=np.argmax(targeted_labels, | |||
| axis=1)) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| @@ -118,6 +129,4 @@ def test_lbfgs_attack(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_lbfgs_attack() | |||
examples/model_security/model_attacks/black_box/mnist_attack_nes.py → example/mnist_demo/mnist_attack_nes.py
View File
| @@ -11,21 +11,27 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks import NES | |||
| from mindarmour.attacks.black.natural_evolutionary_strategy import NES | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE) | |||
| context.set_context(device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'HopSkipJumpAttack' | |||
| @@ -67,26 +73,31 @@ def _pseudorandom_target(index, total_indices, true_class): | |||
| def create_target_images(dataset, data_labels, target_labels): | |||
| res = [] | |||
| for label in target_labels: | |||
| for data_label, data in zip(data_labels, dataset): | |||
| if data_label == label: | |||
| res.append(data) | |||
| for i in range(len(data_labels)): | |||
| if data_labels[i] == label: | |||
| res.append(dataset[i]) | |||
| break | |||
| return np.array(res) | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_nes_mnist_attack(): | |||
| """ | |||
| hsja-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| net.set_train(False) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -98,7 +109,7 @@ def test_nes_mnist_attack(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -140,7 +151,7 @@ def test_nes_mnist_attack(): | |||
| target_image = create_target_images(test_images, true_labels, | |||
| target_class) | |||
| nes_instance.set_target_images(target_image) | |||
| tag, adv, queries = nes_instance.generate(np.array(initial_img), np.array(target_class)) | |||
| tag, adv, queries = nes_instance.generate(initial_img, target_class) | |||
| if tag[0]: | |||
| success += 1 | |||
| queries_num += queries[0] | |||
| @@ -154,6 +165,4 @@ def test_nes_mnist_attack(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_nes_mnist_attack() | |||
examples/model_security/model_attacks/white_box/mnist_attack_pgd.py → example/mnist_demo/mnist_attack_pgd.py
View File
| @@ -11,42 +11,53 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindarmour.adv_robustness.attacks import ProjectedGradientDescent | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.iterative_gradient_method import ProjectedGradientDescent | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'PGD_Test' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_projected_gradient_descent_method(): | |||
| """ | |||
| PGD-Attack test for CPU device. | |||
| PGD-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size) | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| @@ -55,7 +66,7 @@ def test_projected_gradient_descent_method(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -67,17 +78,16 @@ def test_projected_gradient_descent_method(): | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| true_labels = np.argmax(np.concatenate(test_labels), axis=1) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| # attacking | |||
| loss = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| attack = ProjectedGradientDescent(net, eps=0.3, loss_fn=loss) | |||
| start_time = time.process_time() | |||
| attack = ProjectedGradientDescent(net, eps=0.3) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| true_labels, batch_size=32) | |||
| stop_time = time.process_time() | |||
| np.concatenate(test_labels), batch_size=32) | |||
| stop_time = time.clock() | |||
| np.save('./adv_data', adv_data) | |||
| pred_logits_adv = model.predict(Tensor(adv_data)).asnumpy() | |||
| # rescale predict confidences into (0, 1). | |||
| @@ -86,7 +96,7 @@ def test_projected_gradient_descent_method(): | |||
| accuracy_adv = np.mean(np.equal(pred_labels_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", accuracy_adv) | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| np.eye(10)[true_labels], | |||
| np.concatenate(test_labels), | |||
| adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| @@ -106,6 +116,4 @@ def test_projected_gradient_descent_method(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_projected_gradient_descent_method() | |||
examples/model_security/model_attacks/black_box/mnist_attack_pointwise.py → example/mnist_demo/mnist_attack_pointwise.py
View File
| @@ -11,20 +11,26 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks import PointWiseAttack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.black.pointwise_attack import PointWiseAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Pointwise_Attack' | |||
| @@ -46,18 +52,23 @@ class ModelToBeAttacked(BlackModel): | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pointwise_attack_on_mnist(): | |||
| """ | |||
| Salt-and-Pepper-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -68,7 +79,7 @@ def test_pointwise_attack_on_mnist(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -88,8 +99,8 @@ def test_pointwise_attack_on_mnist(): | |||
| attack = PointWiseAttack(model=model, is_targeted=is_target) | |||
| if is_target: | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i, true_l in enumerate(true_labels): | |||
| if targeted_labels[i] == true_l: | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| else: | |||
| targeted_labels = true_labels | |||
| @@ -110,7 +121,7 @@ def test_pointwise_attack_on_mnist(): | |||
| test_labels_onehot = np.eye(10)[true_labels] | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images), | |||
| test_labels_onehot, adv_data, | |||
| np.array(adv_preds), targeted=is_target, | |||
| adv_preds, targeted=is_target, | |||
| target_label=targeted_labels) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| @@ -124,6 +135,4 @@ def test_pointwise_attack_on_mnist(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_pointwise_attack_on_mnist() | |||
examples/model_security/model_attacks/black_box/mnist_attack_pso.py → example/mnist_demo/mnist_attack_pso.py
View File
| @@ -11,24 +11,29 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import time | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'PSO_Attack' | |||
| @@ -41,25 +46,27 @@ class ModelToBeAttacked(BlackModel): | |||
| def predict(self, inputs): | |||
| """predict""" | |||
| # Adapt to the input shape requirements of the target network if inputs is only one image. | |||
| if len(inputs.shape) == 3: | |||
| inputs = np.expand_dims(inputs, axis=0) | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_pso_attack_on_mnist(): | |||
| """ | |||
| PSO-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -70,7 +77,7 @@ def test_pso_attack_on_mnist(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -121,6 +128,4 @@ def test_pso_attack_on_mnist(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_pso_attack_on_mnist() | |||
examples/model_security/model_attacks/black_box/mnist_attack_salt_and_pepper.py → example/mnist_demo/mnist_attack_salt_and_pepper.py
View File
| @@ -11,20 +11,26 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks import SaltAndPepperNoiseAttack | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.attacks.black.salt_and_pepper_attack import SaltAndPepperNoiseAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.evaluations.attack_evaluation import AttackEvaluate | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Salt_and_Pepper_Attack' | |||
| @@ -46,18 +52,23 @@ class ModelToBeAttacked(BlackModel): | |||
| return result.asnumpy() | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_salt_and_pepper_attack_on_mnist(): | |||
| """ | |||
| Salt-and-Pepper-Attack test | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| @@ -68,7 +79,7 @@ def test_salt_and_pepper_attack_on_mnist(): | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -91,8 +102,8 @@ def test_salt_and_pepper_attack_on_mnist(): | |||
| sparse=True) | |||
| if is_target: | |||
| targeted_labels = np.random.randint(0, 10, size=len(true_labels)) | |||
| for i, true_l in enumerate(true_labels): | |||
| if targeted_labels[i] == true_l: | |||
| for i in range(len(true_labels)): | |||
| if targeted_labels[i] == true_labels[i]: | |||
| targeted_labels[i] = (targeted_labels[i] + 1) % 10 | |||
| else: | |||
| targeted_labels = true_labels | |||
| @@ -108,7 +119,6 @@ def test_salt_and_pepper_attack_on_mnist(): | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| adv_preds.extend(pred_logits_adv) | |||
| adv_preds = np.array(adv_preds) | |||
| accuracy_adv = np.mean(np.equal(np.max(adv_preds, axis=1), true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %g", | |||
| accuracy_adv) | |||
| @@ -129,6 +139,4 @@ def test_salt_and_pepper_attack_on_mnist(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_salt_and_pepper_attack_on_mnist() | |||
+ 144
- 0
example/mnist_demo/mnist_defense_nad.py
View File
| @@ -0,0 +1,144 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """defense example using nad""" | |||
| import sys | |||
| import logging | |||
| import numpy as np | |||
| import pytest | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore import nn | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.attacks import FastGradientSignMethod | |||
| from mindarmour.defenses import NaturalAdversarialDefense | |||
| from mindarmour.utils.logger import LogUtil | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Nad_Example' | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_nad_method(): | |||
| """ | |||
| NAD-Defense test. | |||
| """ | |||
| # 1. load trained network | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| loss = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=False) | |||
| opt = nn.Momentum(net.trainable_params(), 0.01, 0.09) | |||
| nad = NaturalAdversarialDefense(net, loss_fn=loss, optimizer=opt, | |||
| bounds=(0.0, 1.0), eps=0.3) | |||
| # 2. get test data | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds_test = generate_mnist_dataset(data_list, batch_size=batch_size, | |||
| sparse=False) | |||
| inputs = [] | |||
| labels = [] | |||
| for data in ds_test.create_tuple_iterator(): | |||
| inputs.append(data[0].astype(np.float32)) | |||
| labels.append(data[1]) | |||
| inputs = np.concatenate(inputs) | |||
| labels = np.concatenate(labels) | |||
| # 3. get accuracy of test data on original model | |||
| net.set_train(False) | |||
| acc_list = [] | |||
| batchs = inputs.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = inputs[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of TEST data on original model is : %s', | |||
| np.mean(acc_list)) | |||
| # 4. get adv of test data | |||
| attack = FastGradientSignMethod(net, eps=0.3) | |||
| adv_data = attack.batch_generate(inputs, labels) | |||
| LOGGER.debug(TAG, 'adv_data.shape is : %s', adv_data.shape) | |||
| # 5. get accuracy of adv data on original model | |||
| net.set_train(False) | |||
| acc_list = [] | |||
| batchs = adv_data.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = adv_data[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of adv data on original model is : %s', | |||
| np.mean(acc_list)) | |||
| # 6. defense | |||
| net.set_train() | |||
| nad.batch_defense(inputs, labels, batch_size=32, epochs=10) | |||
| # 7. get accuracy of test data on defensed model | |||
| net.set_train(False) | |||
| acc_list = [] | |||
| batchs = inputs.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = inputs[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of TEST data on defensed model is : %s', | |||
| np.mean(acc_list)) | |||
| # 8. get accuracy of adv data on defensed model | |||
| acc_list = [] | |||
| batchs = adv_data.shape[0] // batch_size | |||
| for i in range(batchs): | |||
| batch_inputs = adv_data[i*batch_size : (i + 1)*batch_size] | |||
| batch_labels = np.argmax(labels[i*batch_size : (i + 1)*batch_size], axis=1) | |||
| logits = net(Tensor(batch_inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc_list.append(np.mean(batch_labels == label_pred)) | |||
| LOGGER.debug(TAG, 'accuracy of adv data on defensed model is : %s', | |||
| np.mean(acc_list)) | |||
| if __name__ == '__main__': | |||
| LOGGER.set_level(logging.DEBUG) | |||
| test_nad_method() | |||
examples/model_security/model_defenses/mnist_evaluation.py → example/mnist_demo/mnist_evaluation.py
View File
| @@ -12,34 +12,37 @@ | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """evaluate example""" | |||
| import sys | |||
| import os | |||
| import time | |||
| import numpy as np | |||
| from scipy.special import softmax | |||
| from lenet5_net import LeNet5 | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore import nn | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops.operations import TensorAdd | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore.ops.operations import Add | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from scipy.special import softmax | |||
| from mindarmour.adv_robustness.attacks import FastGradientSignMethod | |||
| from mindarmour.adv_robustness.attacks import GeneticAttack | |||
| from mindarmour.adv_robustness.attacks.black.black_model import BlackModel | |||
| from mindarmour.adv_robustness.defenses import NaturalAdversarialDefense | |||
| from mindarmour.adv_robustness.detectors import SimilarityDetector | |||
| from mindarmour.adv_robustness.evaluations import BlackDefenseEvaluate | |||
| from mindarmour.adv_robustness.evaluations import DefenseEvaluate | |||
| from mindarmour.attacks import FastGradientSignMethod | |||
| from mindarmour.attacks import GeneticAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.defenses import NaturalAdversarialDefense | |||
| from mindarmour.evaluations import BlackDefenseEvaluate | |||
| from mindarmour.evaluations import DefenseEvaluate | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.detectors.black.similarity_detector import SimilarityDetector | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'Defense_Evaluate_Example' | |||
| @@ -58,7 +61,7 @@ class EncoderNet(Cell): | |||
| def __init__(self, encode_dim): | |||
| super(EncoderNet, self).__init__() | |||
| self._encode_dim = encode_dim | |||
| self.add = Add() | |||
| self.add = TensorAdd() | |||
| def construct(self, inputs): | |||
| """ | |||
| @@ -99,8 +102,6 @@ class ModelToBeAttacked(BlackModel): | |||
| """ | |||
| predict function | |||
| """ | |||
| if len(inputs.shape) == 3: | |||
| inputs = np.expand_dims(inputs, axis=0) | |||
| query_num = inputs.shape[0] | |||
| results = [] | |||
| if self._detector: | |||
| @@ -108,7 +109,7 @@ class ModelToBeAttacked(BlackModel): | |||
| query = np.expand_dims(inputs[i].astype(np.float32), axis=0) | |||
| result = self._network(Tensor(query)).asnumpy() | |||
| det_num = len(self._detector.get_detected_queries()) | |||
| self._detector.detect(np.array([query])) | |||
| self._detector.detect([query]) | |||
| new_det_num = len(self._detector.get_detected_queries()) | |||
| # If attack query detected, return random predict result | |||
| if new_det_num > det_num: | |||
| @@ -119,8 +120,6 @@ class ModelToBeAttacked(BlackModel): | |||
| self._detected_res.append(False) | |||
| results = np.concatenate(results) | |||
| else: | |||
| if len(inputs.shape) == 3: | |||
| inputs = np.expand_dims(inputs, axis=0) | |||
| results = self._network(Tensor(inputs.astype(np.float32))).asnumpy() | |||
| return results | |||
| @@ -128,30 +127,33 @@ class ModelToBeAttacked(BlackModel): | |||
| return self._detected_res | |||
| def test_defense_evaluation(): | |||
| def test_black_defense(): | |||
| # load trained network | |||
| current_dir = os.path.dirname(os.path.abspath(__file__)) | |||
| ckpt_path = os.path.abspath(os.path.join( | |||
| current_dir, '../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt')) | |||
| ckpt_name = os.path.abspath(os.path.join( | |||
| current_dir, './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt')) | |||
| # ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| wb_net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(wb_net, load_dict) | |||
| # get test data | |||
| data_list = "../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 32 | |||
| ds_test = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| ds_test = generate_mnist_dataset(data_list, batch_size=batch_size, | |||
| sparse=False) | |||
| inputs = [] | |||
| labels = [] | |||
| for data in ds_test.create_tuple_iterator(output_numpy=True): | |||
| for data in ds_test.create_tuple_iterator(): | |||
| inputs.append(data[0].astype(np.float32)) | |||
| labels.append(data[1]) | |||
| inputs = np.concatenate(inputs).astype(np.float32) | |||
| labels = np.concatenate(labels).astype(np.int32) | |||
| labels = np.concatenate(labels).astype(np.float32) | |||
| labels_sparse = np.argmax(labels, axis=1) | |||
| target_label = np.random.randint(0, 10, size=labels.shape[0]) | |||
| for idx in range(labels.shape[0]): | |||
| while target_label[idx] == labels[idx]: | |||
| target_label = np.random.randint(0, 10, size=labels_sparse.shape[0]) | |||
| for idx in range(labels_sparse.shape[0]): | |||
| while target_label[idx] == labels_sparse[idx]: | |||
| target_label[idx] = np.random.randint(0, 10) | |||
| target_label = np.eye(10)[target_label].astype(np.float32) | |||
| @@ -165,23 +167,23 @@ def test_defense_evaluation(): | |||
| wb_model = ModelToBeAttacked(wb_net) | |||
| # gen white-box adversarial examples of test data | |||
| loss = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| wb_attack = FastGradientSignMethod(wb_net, eps=0.3, loss_fn=loss) | |||
| wb_attack = FastGradientSignMethod(wb_net, eps=0.3) | |||
| wb_adv_sample = wb_attack.generate(attacked_sample, | |||
| attacked_true_label) | |||
| wb_raw_preds = softmax(wb_model.predict(wb_adv_sample), axis=1) | |||
| accuracy_test = np.mean( | |||
| np.equal(np.argmax(wb_model.predict(attacked_sample), axis=1), | |||
| attacked_true_label)) | |||
| np.argmax(attacked_true_label, axis=1))) | |||
| LOGGER.info(TAG, "prediction accuracy before white-box attack is : %s", | |||
| accuracy_test) | |||
| accuracy_adv = np.mean(np.equal(np.argmax(wb_raw_preds, axis=1), | |||
| attacked_true_label)) | |||
| np.argmax(attacked_true_label, axis=1))) | |||
| LOGGER.info(TAG, "prediction accuracy after white-box attack is : %s", | |||
| accuracy_adv) | |||
| # improve the robustness of model with white-box adversarial examples | |||
| loss = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=False) | |||
| opt = nn.Momentum(wb_net.trainable_params(), 0.01, 0.09) | |||
| nad = NaturalAdversarialDefense(wb_net, loss_fn=loss, optimizer=opt, | |||
| @@ -192,12 +194,12 @@ def test_defense_evaluation(): | |||
| wb_def_preds = wb_net(Tensor(wb_adv_sample)).asnumpy() | |||
| wb_def_preds = softmax(wb_def_preds, axis=1) | |||
| accuracy_def = np.mean(np.equal(np.argmax(wb_def_preds, axis=1), | |||
| attacked_true_label)) | |||
| np.argmax(attacked_true_label, axis=1))) | |||
| LOGGER.info(TAG, "prediction accuracy after defense is : %s", accuracy_def) | |||
| # calculate defense evaluation metrics for defense against white-box attack | |||
| wb_def_evaluate = DefenseEvaluate(wb_raw_preds, wb_def_preds, | |||
| attacked_true_label) | |||
| np.argmax(attacked_true_label, axis=1)) | |||
| LOGGER.info(TAG, 'defense evaluation for white-box adversarial attack') | |||
| LOGGER.info(TAG, | |||
| 'classification accuracy variance (CAV) is : {:.2f}'.format( | |||
| @@ -227,15 +229,15 @@ def test_defense_evaluation(): | |||
| load_param_into_net(bb_net, load_dict) | |||
| bb_model = ModelToBeAttacked(bb_net, defense=False) | |||
| attack_rm = GeneticAttack(model=bb_model, pop_size=6, mutation_rate=0.05, | |||
| per_bounds=0.5, step_size=0.25, temp=0.1, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| sparse=False) | |||
| attack_target_label = target_label[:attacked_size] | |||
| true_label = labels[:attacked_size + benign_size] | |||
| true_label = labels_sparse[:attacked_size + benign_size] | |||
| # evaluate robustness of original model | |||
| # gen black-box adversarial examples of test data | |||
| for idx in range(attacked_size): | |||
| raw_st = time.time() | |||
| _, raw_a, raw_qc = attack_rm.generate( | |||
| raw_sl, raw_a, raw_qc = attack_rm.generate( | |||
| np.expand_dims(attacked_sample[idx], axis=0), | |||
| np.expand_dims(attack_target_label[idx], axis=0)) | |||
| raw_t = time.time() - raw_st | |||
| @@ -265,11 +267,11 @@ def test_defense_evaluation(): | |||
| # attack defensed model | |||
| attack_dm = GeneticAttack(model=bb_def_model, pop_size=6, | |||
| mutation_rate=0.05, | |||
| per_bounds=0.5, step_size=0.25, temp=0.1, | |||
| per_bounds=0.1, step_size=0.25, temp=0.1, | |||
| sparse=False) | |||
| for idx in range(attacked_size): | |||
| def_st = time.time() | |||
| _, def_a, def_qc = attack_dm.generate( | |||
| def_sl, def_a, def_qc = attack_dm.generate( | |||
| np.expand_dims(attacked_sample[idx], axis=0), | |||
| np.expand_dims(attack_target_label[idx], axis=0)) | |||
| def_t = time.time() - def_st | |||
| @@ -321,8 +323,4 @@ def test_defense_evaluation(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="GPU") | |||
| DEVICE = context.get_context("device_target") | |||
| if DEVICE in ("Ascend", "GPU"): | |||
| test_defense_evaluation() | |||
| test_black_defense() | |||
examples/model_security/model_defenses/mnist_similarity_detector.py → example/mnist_demo/mnist_similarity_detector.py
View File
| @@ -11,26 +11,31 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import sys | |||
| import numpy as np | |||
| import pytest | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops.operations import Add | |||
| from mindspore.ops.operations import TensorAdd | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.adv_robustness.detectors import SimilarityDetector | |||
| from mindarmour.utils.logger import LogUtil | |||
| from mindarmour.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.attacks.black.black_model import BlackModel | |||
| from mindarmour.detectors.black.similarity_detector import SimilarityDetector | |||
| from lenet5_net import LeNet5 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'Similarity Detector test' | |||
| @@ -50,13 +55,7 @@ class ModelToBeAttacked(BlackModel): | |||
| """ | |||
| query_num = inputs.shape[0] | |||
| for i in range(query_num): | |||
| if len(inputs[i].shape) == 2: | |||
| temp = np.expand_dims(inputs[i], axis=0) | |||
| else: | |||
| temp = inputs[i] | |||
| self._queries.append(temp.astype(np.float32)) | |||
| if len(inputs.shape) == 3: | |||
| inputs = np.expand_dims(inputs, axis=0) | |||
| self._queries.append(inputs[i].astype(np.float32)) | |||
| result = self._network(Tensor(inputs.astype(np.float32))) | |||
| return result.asnumpy() | |||
| @@ -72,7 +71,7 @@ class EncoderNet(Cell): | |||
| def __init__(self, encode_dim): | |||
| super(EncoderNet, self).__init__() | |||
| self._encode_dim = encode_dim | |||
| self.add = Add() | |||
| self.add = TensorAdd() | |||
| def construct(self, inputs): | |||
| """ | |||
| @@ -94,18 +93,23 @@ class EncoderNet(Cell): | |||
| return self._encode_dim | |||
| @pytest.mark.level1 | |||
| @pytest.mark.platform_arm_ascend_training | |||
| @pytest.mark.platform_x86_ascend_training | |||
| @pytest.mark.env_card | |||
| @pytest.mark.component_mindarmour | |||
| def test_similarity_detector(): | |||
| """ | |||
| Similarity Detector test. | |||
| """ | |||
| # load trained network | |||
| ckpt_path = '../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| ckpt_name = './trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_dict = load_checkpoint(ckpt_name) | |||
| load_param_into_net(net, load_dict) | |||
| # get mnist data | |||
| data_list = "../../common/dataset/MNIST/test" | |||
| data_list = "./MNIST_unzip/test" | |||
| batch_size = 1000 | |||
| ds = generate_mnist_dataset(data_list, batch_size=batch_size) | |||
| model = ModelToBeAttacked(net) | |||
| @@ -115,7 +119,7 @@ def test_similarity_detector(): | |||
| true_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| for data in ds.create_tuple_iterator(): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| @@ -167,7 +171,7 @@ def test_similarity_detector(): | |||
| # test attack queries | |||
| detector.clear_buffer() | |||
| detector.detect(np.array(suspicious_queries)) | |||
| detector.detect(suspicious_queries) | |||
| LOGGER.info(TAG, 'Number of detected attack queries is : %s', | |||
| len(detector.get_detected_queries())) | |||
| LOGGER.info(TAG, 'The detected attack query indexes are : %s', | |||
| @@ -175,8 +179,4 @@ def test_similarity_detector(): | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="GPU") | |||
| DEVICE = context.get_context("device_target") | |||
| if DEVICE in ("Ascend", "GPU"): | |||
| test_similarity_detector() | |||
| test_similarity_detector() | |||
examples/common/networks/lenet5/mnist_train.py → example/mnist_demo/mnist_train.py
View File
| @@ -11,55 +11,78 @@ | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| import os | |||
| import sys | |||
| import mindspore.nn as nn | |||
| from mindspore import context | |||
| from mindspore.nn.metrics import Accuracy | |||
| from mindspore.train import Model | |||
| from mindspore import context, Tensor | |||
| from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.train import Model | |||
| import mindspore.ops.operations as P | |||
| from mindspore.nn.metrics import Accuracy | |||
| from mindspore.ops import functional as F | |||
| from mindspore.common import dtype as mstype | |||
| from mindarmour.utils.logger import LogUtil | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from lenet5_net import LeNet5 | |||
| sys.path.append("..") | |||
| from data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| TAG = 'Lenet5_train' | |||
| TAG = "Lenet5_train" | |||
| class CrossEntropyLoss(nn.Cell): | |||
| """ | |||
| Define loss for network | |||
| """ | |||
| def __init__(self): | |||
| super(CrossEntropyLoss, self).__init__() | |||
| self.cross_entropy = P.SoftmaxCrossEntropyWithLogits() | |||
| self.mean = P.ReduceMean() | |||
| self.one_hot = P.OneHot() | |||
| self.on_value = Tensor(1.0, mstype.float32) | |||
| self.off_value = Tensor(0.0, mstype.float32) | |||
| def construct(self, logits, label): | |||
| label = self.one_hot(label, F.shape(logits)[1], self.on_value, self.off_value) | |||
| loss = self.cross_entropy(logits, label)[0] | |||
| loss = self.mean(loss, (-1,)) | |||
| return loss | |||
| def mnist_train(epoch_size, batch_size, lr, momentum): | |||
| mnist_path = "../../dataset/MNIST" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", | |||
| enable_mem_reuse=False) | |||
| lr = lr | |||
| momentum = momentum | |||
| epoch_size = epoch_size | |||
| mnist_path = "./MNIST_unzip/" | |||
| ds = generate_mnist_dataset(os.path.join(mnist_path, "train"), | |||
| batch_size=batch_size, repeat_size=1) | |||
| network = LeNet5() | |||
| net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean") | |||
| network.set_train() | |||
| net_loss = CrossEntropyLoss() | |||
| net_opt = nn.Momentum(network.trainable_params(), lr, momentum) | |||
| config_ck = CheckpointConfig(save_checkpoint_steps=1875, | |||
| keep_checkpoint_max=10) | |||
| ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", | |||
| directory="./trained_ckpt_file/", | |||
| config=config_ck) | |||
| config_ck = CheckpointConfig(save_checkpoint_steps=1875, keep_checkpoint_max=10) | |||
| ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", directory='./trained_ckpt_file/', config=config_ck) | |||
| model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()}) | |||
| LOGGER.info(TAG, "============== Starting Training ==============") | |||
| model.train(epoch_size, ds, callbacks=[ckpoint_cb, LossMonitor()], | |||
| dataset_sink_mode=False) | |||
| model.train(epoch_size, ds, callbacks=[ckpoint_cb, LossMonitor()], dataset_sink_mode=False) # train | |||
| LOGGER.info(TAG, "============== Starting Testing ==============") | |||
| ckpt_file_name = "trained_ckpt_file/checkpoint_lenet-10_1875.ckpt" | |||
| param_dict = load_checkpoint(ckpt_file_name) | |||
| param_dict = load_checkpoint("trained_ckpt_file/checkpoint_lenet-10_1875.ckpt") | |||
| load_param_into_net(network, param_dict) | |||
| ds_eval = generate_mnist_dataset(os.path.join(mnist_path, "test"), | |||
| batch_size=batch_size) | |||
| acc = model.eval(ds_eval, dataset_sink_mode=False) | |||
| ds_eval = generate_mnist_dataset(os.path.join(mnist_path, "test"), batch_size=batch_size) | |||
| acc = model.eval(ds_eval) | |||
| LOGGER.info(TAG, "============== Accuracy: %s ==============", acc) | |||
| if __name__ == '__main__': | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| mnist_train(10, 32, 0.01, 0.9) | |||
| mnist_train(10, 32, 0.001, 0.9) | |||
+ 0
- 38
examples/README.md
View File
| @@ -1,38 +0,0 @@ | |||
| # Examples | |||
| ## Introduction | |||
| This package includes application demos for all developed tools of MindArmour. Through these demos, you will soon | |||
| master those tools of MindArmour. Let's Start! | |||
| ## Preparation | |||
| Most of those demos are implemented based on LeNet5 and MNIST dataset. As a preparation, we should download MNIST and | |||
| train a LeNet5 model first. | |||
| ### 1. download dataset | |||
| The MNIST database of handwritten digits has a training set of 60,000 examples, and a test set of 10,000 examples | |||
| . It is a subset of a larger set available from MNIST. The digits have been size-normalized and centered in a fixed-size image. | |||
| ```sh | |||
| $ cd examples/common/dataset | |||
| $ mkdir MNIST | |||
| $ cd MNIST | |||
| $ mkdir train | |||
| $ mkdir test | |||
| $ cd train | |||
| $ wget "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz" | |||
| $ wget "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz" | |||
| $ gzip train-images-idx3-ubyte.gz -d | |||
| $ gzip train-labels-idx1-ubyte.gz -d | |||
| $ cd ../test | |||
| $ wget "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz" | |||
| $ wget "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz" | |||
| $ gzip t10k-images-idx3-ubyte.gz -d | |||
| $ gzip t10k-images-idx3-ubyte.gz -d | |||
| ``` | |||
| ### 2. trian LeNet5 model | |||
| After training the network, you will obtain a group of ckpt files. Those ckpt files save the trained model parameters | |||
| of LeNet5, which can be used in 'examples/ai_fuzzer' and 'examples/model_security'. | |||
| ```sh | |||
| $ cd examples/common/networks/lenet5 | |||
| $ python mnist_train.py | |||
| ``` | |||
+ 0
- 16
examples/__init__.py
View File
| @@ -1,16 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| This package includes real application examples for developed features of MindArmour. | |||
| """ | |||
+ 0
- 24
examples/ai_fuzzer/README.md
View File
| @@ -1,24 +0,0 @@ | |||
| # Application demos of model fuzzing | |||
| ## Introduction | |||
| The same as the traditional software fuzz testing, we can also design fuzz test for AI models. Compared to | |||
| branch coverage or line coverage of traditional software, some people propose the | |||
| concept of 'neuron coverage' based on the unique structure of deep neural network. We can use the neuron coverage | |||
| as a guide to search more metamorphic inputs to test our models. | |||
| ## 1. calculation of neuron coverage | |||
| There are three metrics proposed for evaluating the neuron coverage of a test:KMNC, NBC and SNAC. Usually we need to | |||
| feed all the training dataset into the model first, and record the output range of all neurons (however, only the last | |||
| layer of neurons are recorded in our method). In the testing phase, we feed test samples into the model, and | |||
| calculate those three metrics mentioned above according to those neurons' output distribution. | |||
| ```sh | |||
| $ cd examples/ai_fuzzer/ | |||
| $ python lenet5_mnist_coverage.py | |||
| ``` | |||
| ## 2. fuzz test for AI model | |||
| We have provided several types of methods for manipulating metamorphic inputs: affine transformation, pixel | |||
| transformation and adversarial attacks. Usually we feed the original samples into the fuzz function as seeds, and | |||
| then metamorphic samples are generated through iterative manipulations. | |||
| ```sh | |||
| $ cd examples/ai_fuzzer/ | |||
| $ python lenet5_mnist_fuzzing.py | |||
| ``` | |||
+ 0
- 169
examples/ai_fuzzer/fuzz_testing_and_model_enhense.py
View File
| @@ -1,169 +0,0 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """ | |||
| An example of fuzz testing and then enhance non-robustness model. | |||
| """ | |||
| import random | |||
| import numpy as np | |||
| import mindspore | |||
| from mindspore import Model | |||
| from mindspore import context | |||
| from mindspore import Tensor | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore.nn.optim.momentum import Momentum | |||
| from mindarmour.adv_robustness.defenses import AdversarialDefense | |||
| from mindarmour.fuzz_testing import Fuzzer | |||
| from mindarmour.fuzz_testing import ModelCoverageMetrics | |||
| from mindarmour.utils.logger import LogUtil | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Fuzz_testing and enhance model' | |||
| LOGGER.set_level('INFO') | |||
| def example_lenet_mnist_fuzzing(): | |||
| """ | |||
| An example of fuzz testing and then enhance the non-robustness model. | |||
| """ | |||
| # upload trained network | |||
| ckpt_path = '../common/networks/lenet5/trained_ckpt_file/lenet_m1-10_1250.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_param_into_net(net, load_dict) | |||
| model = Model(net) | |||
| mutate_config = [{'method': 'Blur', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'Contrast', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'Translate', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'Brightness', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'Noise', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'Scale', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'Shear', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'FGSM', | |||
| 'params': {'eps': [0.3, 0.2, 0.4], 'alpha': [0.1]}} | |||
| ] | |||
| # get training data | |||
| data_list = "../common/dataset/MNIST/train" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| train_images = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| images = data[0].astype(np.float32) | |||
| train_images.append(images) | |||
| train_images = np.concatenate(train_images, axis=0) | |||
| # initialize fuzz test with training dataset | |||
| model_coverage_test = ModelCoverageMetrics(model, 10, 1000, train_images) | |||
| # fuzz test with original test data | |||
| # get test data | |||
| data_list = "../common/dataset/MNIST/test" | |||
| batch_size = 32 | |||
| init_samples = 5000 | |||
| max_iters = 50000 | |||
| mutate_num_per_seed = 10 | |||
| ds = generate_mnist_dataset(data_list, batch_size, num_samples=init_samples, | |||
| sparse=False) | |||
| test_images = [] | |||
| test_labels = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| test_images = np.concatenate(test_images, axis=0) | |||
| test_labels = np.concatenate(test_labels, axis=0) | |||
| initial_seeds = [] | |||
| # make initial seeds | |||
| for img, label in zip(test_images, test_labels): | |||
| initial_seeds.append([img, label]) | |||
| model_coverage_test.calculate_coverage( | |||
| np.array(test_images[:100]).astype(np.float32)) | |||
| LOGGER.info(TAG, 'KMNC of test dataset before fuzzing is : %s', | |||
| model_coverage_test.get_kmnc()) | |||
| LOGGER.info(TAG, 'NBC of test dataset before fuzzing is : %s', | |||
| model_coverage_test.get_nbc()) | |||
| LOGGER.info(TAG, 'SNAC of test dataset before fuzzing is : %s', | |||
| model_coverage_test.get_snac()) | |||
| model_fuzz_test = Fuzzer(model, train_images, 10, 1000) | |||
| gen_samples, gt, _, _, metrics = model_fuzz_test.fuzzing(mutate_config, | |||
| initial_seeds, | |||
| eval_metrics='auto', | |||
| max_iters=max_iters, | |||
| mutate_num_per_seed=mutate_num_per_seed) | |||
| if metrics: | |||
| for key in metrics: | |||
| LOGGER.info(TAG, key + ': %s', metrics[key]) | |||
| def split_dataset(image, label, proportion): | |||
| """ | |||
| Split the generated fuzz data into train and test set. | |||
| """ | |||
| indices = np.arange(len(image)) | |||
| random.shuffle(indices) | |||
| train_length = int(len(image) * proportion) | |||
| train_image = [image[i] for i in indices[:train_length]] | |||
| train_label = [label[i] for i in indices[:train_length]] | |||
| test_image = [image[i] for i in indices[:train_length]] | |||
| test_label = [label[i] for i in indices[:train_length]] | |||
| return train_image, train_label, test_image, test_label | |||
| train_image, train_label, test_image, test_label = split_dataset( | |||
| gen_samples, gt, 0.7) | |||
| # load model B and test it on the test set | |||
| ckpt_path = '../common/networks/lenet5/trained_ckpt_file/lenet_m2-10_1250.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_param_into_net(net, load_dict) | |||
| model_b = Model(net) | |||
| pred_b = model_b.predict(Tensor(test_image, dtype=mindspore.float32)).asnumpy() | |||
| acc_b = np.sum(np.argmax(pred_b, axis=1) == np.argmax(test_label, axis=1)) / len(test_label) | |||
| print('Accuracy of model B on test set is ', acc_b) | |||
| # enhense model robustness | |||
| lr = 0.001 | |||
| momentum = 0.9 | |||
| loss_fn = SoftmaxCrossEntropyWithLogits(Sparse=True) | |||
| optimizer = Momentum(net.trainable_params(), lr, momentum) | |||
| adv_defense = AdversarialDefense(net, loss_fn, optimizer) | |||
| adv_defense.batch_defense(np.array(train_image).astype(np.float32), | |||
| np.argmax(train_label, axis=1).astype(np.int32)) | |||
| preds_en = net(Tensor(test_image, dtype=mindspore.float32)).asnumpy() | |||
| acc_en = np.sum(np.argmax(preds_en, axis=1) == np.argmax(test_label, axis=1)) / len(test_label) | |||
| print('Accuracy of enhensed model on test set is ', acc_en) | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| example_lenet_mnist_fuzzing() | |||
+ 0
- 85
examples/ai_fuzzer/lenet5_mnist_coverage.py
View File
| @@ -1,85 +0,0 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import numpy as np | |||
| from mindspore import Model | |||
| from mindspore import context | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.adv_robustness.attacks import FastGradientSignMethod | |||
| from mindarmour.fuzz_testing import ModelCoverageMetrics | |||
| from mindarmour.utils.logger import LogUtil | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Neuron coverage test' | |||
| LOGGER.set_level('INFO') | |||
| def test_lenet_mnist_coverage(): | |||
| # upload trained network | |||
| ckpt_path = '../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_param_into_net(net, load_dict) | |||
| model = Model(net) | |||
| # get training data | |||
| data_list = "../common/dataset/MNIST/train" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=True) | |||
| train_images = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| images = data[0].astype(np.float32) | |||
| train_images.append(images) | |||
| train_images = np.concatenate(train_images, axis=0) | |||
| # initialize fuzz test with training dataset | |||
| model_fuzz_test = ModelCoverageMetrics(model, 10, 1000, train_images) | |||
| # fuzz test with original test data | |||
| # get test data | |||
| data_list = "../common/dataset/MNIST/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=True) | |||
| test_images = [] | |||
| test_labels = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| test_images = np.concatenate(test_images, axis=0) | |||
| test_labels = np.concatenate(test_labels, axis=0) | |||
| model_fuzz_test.calculate_coverage(test_images) | |||
| LOGGER.info(TAG, 'KMNC of this test is : %s', model_fuzz_test.get_kmnc()) | |||
| LOGGER.info(TAG, 'NBC of this test is : %s', model_fuzz_test.get_nbc()) | |||
| LOGGER.info(TAG, 'SNAC of this test is : %s', model_fuzz_test.get_snac()) | |||
| # generate adv_data | |||
| loss = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| attack = FastGradientSignMethod(net, eps=0.3, loss_fn=loss) | |||
| adv_data = attack.batch_generate(test_images, test_labels, batch_size=32) | |||
| model_fuzz_test.calculate_coverage(adv_data, bias_coefficient=0.5) | |||
| LOGGER.info(TAG, 'KMNC of this adv data is : %s', model_fuzz_test.get_kmnc()) | |||
| LOGGER.info(TAG, 'NBC of this adv data is : %s', model_fuzz_test.get_nbc()) | |||
| LOGGER.info(TAG, 'SNAC of this adv data is : %s', model_fuzz_test.get_snac()) | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| test_lenet_mnist_coverage() | |||
+ 0
- 107
examples/ai_fuzzer/lenet5_mnist_fuzzing.py
View File
| @@ -1,107 +0,0 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import numpy as np | |||
| from mindspore import Model | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindarmour.fuzz_testing import Fuzzer | |||
| from mindarmour.fuzz_testing import ModelCoverageMetrics | |||
| from mindarmour.utils.logger import LogUtil | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'Fuzz_test' | |||
| LOGGER.set_level('INFO') | |||
| def test_lenet_mnist_fuzzing(): | |||
| # upload trained network | |||
| ckpt_path = '../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_param_into_net(net, load_dict) | |||
| model = Model(net) | |||
| mutate_config = [{'method': 'Blur', | |||
| 'params': {'radius': [0.1, 0.2, 0.3], | |||
| 'auto_param': [True, False]}}, | |||
| {'method': 'Contrast', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'Translate', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'Brightness', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'Noise', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'Scale', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'Shear', | |||
| 'params': {'auto_param': [True]}}, | |||
| {'method': 'FGSM', | |||
| 'params': {'eps': [0.3, 0.2, 0.4], 'alpha': [0.1]}} | |||
| ] | |||
| # get training data | |||
| data_list = "../common/dataset/MNIST/train" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| train_images = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| images = data[0].astype(np.float32) | |||
| train_images.append(images) | |||
| train_images = np.concatenate(train_images, axis=0) | |||
| # initialize fuzz test with training dataset | |||
| model_coverage_test = ModelCoverageMetrics(model, 10, 1000, train_images) | |||
| # fuzz test with original test data | |||
| # get test data | |||
| data_list = "../common/dataset/MNIST/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size, sparse=False) | |||
| test_images = [] | |||
| test_labels = [] | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| test_images = np.concatenate(test_images, axis=0) | |||
| test_labels = np.concatenate(test_labels, axis=0) | |||
| initial_seeds = [] | |||
| # make initial seeds | |||
| for img, label in zip(test_images, test_labels): | |||
| initial_seeds.append([img, label]) | |||
| initial_seeds = initial_seeds[:100] | |||
| model_coverage_test.calculate_coverage( | |||
| np.array(test_images[:100]).astype(np.float32)) | |||
| LOGGER.info(TAG, 'KMNC of this test is : %s', | |||
| model_coverage_test.get_kmnc()) | |||
| model_fuzz_test = Fuzzer(model, train_images, 10, 1000) | |||
| _, _, _, _, metrics = model_fuzz_test.fuzzing(mutate_config, initial_seeds, | |||
| eval_metrics='auto') | |||
| if metrics: | |||
| for key in metrics: | |||
| LOGGER.info(TAG, key + ': %s', metrics[key]) | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| test_lenet_mnist_fuzzing() | |||
+ 0
- 116
examples/common/dataset/data_processing.py
View File
| @@ -1,116 +0,0 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import os | |||
| import mindspore.dataset as ds | |||
| import mindspore.dataset.vision.c_transforms as CV | |||
| import mindspore.dataset.transforms.c_transforms as C | |||
| from mindspore.dataset.vision import Inter | |||
| import mindspore.common.dtype as mstype | |||
| def generate_mnist_dataset(data_path, batch_size=32, repeat_size=1, | |||
| num_samples=None, num_parallel_workers=1, sparse=True): | |||
| """ | |||
| create dataset for training or testing | |||
| """ | |||
| # define dataset | |||
| ds1 = ds.MnistDataset(data_path, num_samples=num_samples) | |||
| # define operation parameters | |||
| resize_height, resize_width = 32, 32 | |||
| rescale = 1.0 / 255.0 | |||
| shift = 0.0 | |||
| # define map operations | |||
| resize_op = CV.Resize((resize_height, resize_width), | |||
| interpolation=Inter.LINEAR) | |||
| rescale_op = CV.Rescale(rescale, shift) | |||
| hwc2chw_op = CV.HWC2CHW() | |||
| type_cast_op = C.TypeCast(mstype.int32) | |||
| # apply map operations on images | |||
| if not sparse: | |||
| one_hot_enco = C.OneHot(10) | |||
| ds1 = ds1.map(input_columns="label", operations=one_hot_enco, | |||
| num_parallel_workers=num_parallel_workers) | |||
| type_cast_op = C.TypeCast(mstype.float32) | |||
| ds1 = ds1.map(input_columns="label", operations=type_cast_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=resize_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=rescale_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds1 = ds1.map(input_columns="image", operations=hwc2chw_op, | |||
| num_parallel_workers=num_parallel_workers) | |||
| # apply DatasetOps | |||
| buffer_size = 10000 | |||
| ds1 = ds1.shuffle(buffer_size=buffer_size) | |||
| ds1 = ds1.batch(batch_size, drop_remainder=True) | |||
| ds1 = ds1.repeat(repeat_size) | |||
| return ds1 | |||
| def vgg_create_dataset100(data_home, image_size, batch_size, rank_id=0, rank_size=1, repeat_num=1, | |||
| training=True, num_samples=None, shuffle=True): | |||
| """Data operations.""" | |||
| ds.config.set_seed(1) | |||
| data_dir = os.path.join(data_home, "train") | |||
| if not training: | |||
| data_dir = os.path.join(data_home, "test") | |||
| if num_samples is not None: | |||
| data_set = ds.Cifar100Dataset(data_dir, num_shards=rank_size, shard_id=rank_id, | |||
| num_samples=num_samples, shuffle=shuffle) | |||
| else: | |||
| data_set = ds.Cifar100Dataset(data_dir, num_shards=rank_size, shard_id=rank_id) | |||
| input_columns = ["fine_label"] | |||
| output_columns = ["label"] | |||
| data_set = data_set.rename(input_columns=input_columns, output_columns=output_columns) | |||
| data_set = data_set.project(["image", "label"]) | |||
| rescale = 1.0 / 255.0 | |||
| shift = 0.0 | |||
| # define map operations | |||
| random_crop_op = CV.RandomCrop((32, 32), (4, 4, 4, 4)) # padding_mode default CONSTANT | |||
| random_horizontal_op = CV.RandomHorizontalFlip() | |||
| resize_op = CV.Resize(image_size) # interpolation default BILINEAR | |||
| rescale_op = CV.Rescale(rescale, shift) | |||
| normalize_op = CV.Normalize((0.4465, 0.4822, 0.4914), (0.2010, 0.1994, 0.2023)) | |||
| changeswap_op = CV.HWC2CHW() | |||
| type_cast_op = C.TypeCast(mstype.int32) | |||
| c_trans = [] | |||
| if training: | |||
| c_trans = [random_crop_op, random_horizontal_op] | |||
| c_trans += [resize_op, rescale_op, normalize_op, | |||
| changeswap_op] | |||
| # apply map operations on images | |||
| data_set = data_set.map(input_columns="label", operations=type_cast_op) | |||
| data_set = data_set.map(input_columns="image", operations=c_trans) | |||
| # apply shuffle operations | |||
| data_set = data_set.shuffle(buffer_size=1000) | |||
| # apply batch operations | |||
| data_set = data_set.batch(batch_size=batch_size, drop_remainder=True) | |||
| # apply repeat operations | |||
| data_set = data_set.repeat(repeat_num) | |||
| return data_set | |||
+ 0
- 0
examples/common/networks/__init__.py
View File
+ 0
- 0
examples/common/networks/lenet5/__init__.py
View File
+ 0
- 14
examples/common/networks/vgg/__init__.py
View File
| @@ -1,14 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the License); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # httpwww.apache.orglicensesLICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an AS IS BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
+ 0
- 45
examples/common/networks/vgg/config.py
View File
| @@ -1,45 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| network config setting, will be used in train.py and eval.py | |||
| """ | |||
| from easydict import EasyDict as edict | |||
| # config for vgg16, cifar100 | |||
| cifar_cfg = edict({ | |||
| "num_classes": 100, | |||
| "lr": 0.01, | |||
| "lr_init": 0.01, | |||
| "lr_max": 0.1, | |||
| "lr_epochs": '30,60,90,120', | |||
| "lr_scheduler": "step", | |||
| "warmup_epochs": 5, | |||
| "batch_size": 64, | |||
| "max_epoch": 100, | |||
| "momentum": 0.9, | |||
| "weight_decay": 5e-4, | |||
| "loss_scale": 1.0, | |||
| "label_smooth": 0, | |||
| "label_smooth_factor": 0, | |||
| "buffer_size": 10, | |||
| "image_size": '224,224', | |||
| "pad_mode": 'same', | |||
| "padding": 0, | |||
| "has_bias": False, | |||
| "batch_norm": True, | |||
| "keep_checkpoint_max": 10, | |||
| "initialize_mode": "XavierUniform", | |||
| "has_dropout": False | |||
| }) | |||
+ 0
- 39
examples/common/networks/vgg/crossentropy.py
View File
| @@ -1,39 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """define loss function for network""" | |||
| from mindspore.nn.loss.loss import _Loss | |||
| from mindspore.ops import operations as P | |||
| from mindspore.ops import functional as F | |||
| from mindspore import Tensor | |||
| from mindspore.common import dtype as mstype | |||
| import mindspore.nn as nn | |||
| class CrossEntropy(_Loss): | |||
| """the redefined loss function with SoftmaxCrossEntropyWithLogits""" | |||
| def __init__(self, smooth_factor=0., num_classes=1001): | |||
| super(CrossEntropy, self).__init__() | |||
| self.onehot = P.OneHot() | |||
| self.on_value = Tensor(1.0 - smooth_factor, mstype.float32) | |||
| self.off_value = Tensor(1.0 * smooth_factor / (num_classes - 1), mstype.float32) | |||
| self.ce = nn.SoftmaxCrossEntropyWithLogits() | |||
| self.mean = P.ReduceMean(False) | |||
| def construct(self, logit, label): | |||
| one_hot_label = self.onehot(label, F.shape(logit)[1], self.on_value, self.off_value) | |||
| loss = self.ce(logit, one_hot_label) | |||
| loss = self.mean(loss, 0) | |||
| return loss | |||
+ 0
- 23
examples/common/networks/vgg/linear_warmup.py
View File
| @@ -1,23 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| linear warm up learning rate. | |||
| """ | |||
| def linear_warmup_lr(current_step, warmup_steps, base_lr, init_lr): | |||
| lr_inc = (float(base_lr) - float(init_lr)) / float(warmup_steps) | |||
| lr = float(init_lr) + lr_inc*current_step | |||
| return lr | |||
+ 0
- 0
examples/common/networks/vgg/utils/__init__.py
View File
+ 0
- 36
examples/common/networks/vgg/utils/util.py
View File
| @@ -1,36 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Util class or function.""" | |||
| def get_param_groups(network): | |||
| """Param groups for optimizer.""" | |||
| decay_params = [] | |||
| no_decay_params = [] | |||
| for x in network.trainable_params(): | |||
| parameter_name = x.name | |||
| if parameter_name.endswith('.bias'): | |||
| # all bias not using weight decay | |||
| no_decay_params.append(x) | |||
| elif parameter_name.endswith('.gamma'): | |||
| # bn weight bias not using weight decay, be carefully for now x not include BN | |||
| no_decay_params.append(x) | |||
| elif parameter_name.endswith('.beta'): | |||
| # bn weight bias not using weight decay, be carefully for now x not include BN | |||
| no_decay_params.append(x) | |||
| else: | |||
| decay_params.append(x) | |||
| return [{'params': no_decay_params, 'weight_decay': 0.0}, {'params': decay_params}] | |||
+ 0
- 219
examples/common/networks/vgg/utils/var_init.py
View File
| @@ -1,219 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| Initialize. | |||
| """ | |||
| import math | |||
| from functools import reduce | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| from mindspore.common import initializer as init | |||
| def _calculate_gain(nonlinearity, param=None): | |||
| r""" | |||
| Return the recommended gain value for the given nonlinearity function. | |||
| The values are as follows: | |||
| ================= ==================================================== | |||
| nonlinearity gain | |||
| ================= ==================================================== | |||
| Linear / Identity :math:`1` | |||
| Conv{1,2,3}D :math:`1` | |||
| Sigmoid :math:`1` | |||
| Tanh :math:`\frac{5}{3}` | |||
| ReLU :math:`\sqrt{2}` | |||
| Leaky Relu :math:`\sqrt{\frac{2}{1 + \text{negative\_slope}^2}}` | |||
| ================= ==================================================== | |||
| Args: | |||
| nonlinearity: the non-linear function | |||
| param: optional parameter for the non-linear function | |||
| Examples: | |||
| >>> gain = calculate_gain('leaky_relu', 0.2) # leaky_relu with negative_slope=0.2 | |||
| """ | |||
| linear_fns = ['linear', 'conv1d', 'conv2d', 'conv3d', 'conv_transpose1d', 'conv_transpose2d', 'conv_transpose3d'] | |||
| if nonlinearity in linear_fns or nonlinearity == 'sigmoid': | |||
| return 1 | |||
| if nonlinearity == 'tanh': | |||
| return 5.0 / 3 | |||
| if nonlinearity == 'relu': | |||
| return math.sqrt(2.0) | |||
| if nonlinearity == 'leaky_relu': | |||
| if param is None: | |||
| negative_slope = 0.01 | |||
| elif not isinstance(param, bool) and isinstance(param, int) or isinstance(param, float): | |||
| negative_slope = param | |||
| else: | |||
| raise ValueError("negative_slope {} not a valid number".format(param)) | |||
| return math.sqrt(2.0 / (1 + negative_slope**2)) | |||
| raise ValueError("Unsupported nonlinearity {}".format(nonlinearity)) | |||
| def _assignment(arr, num): | |||
| """Assign the value of `num` to `arr`.""" | |||
| if arr.shape == (): | |||
| arr = arr.reshape((1)) | |||
| arr[:] = num | |||
| arr = arr.reshape(()) | |||
| else: | |||
| if isinstance(num, np.ndarray): | |||
| arr[:] = num[:] | |||
| else: | |||
| arr[:] = num | |||
| return arr | |||
| def _calculate_in_and_out(arr): | |||
| """ | |||
| Calculate n_in and n_out. | |||
| Args: | |||
| arr (Array): Input array. | |||
| Returns: | |||
| Tuple, a tuple with two elements, the first element is `n_in` and the second element is `n_out`. | |||
| """ | |||
| dim = len(arr.shape) | |||
| if dim < 2: | |||
| raise ValueError("If initialize data with xavier uniform, the dimension of data must greater than 1.") | |||
| n_in = arr.shape[1] | |||
| n_out = arr.shape[0] | |||
| if dim > 2: | |||
| counter = reduce(lambda x, y: x*y, arr.shape[2:]) | |||
| n_in *= counter | |||
| n_out *= counter | |||
| return n_in, n_out | |||
| def _select_fan(array, mode): | |||
| mode = mode.lower() | |||
| valid_modes = ['fan_in', 'fan_out'] | |||
| if mode not in valid_modes: | |||
| raise ValueError("Mode {} not supported, please use one of {}".format(mode, valid_modes)) | |||
| fan_in, fan_out = _calculate_in_and_out(array) | |||
| return fan_in if mode == 'fan_in' else fan_out | |||
| class KaimingInit(init.Initializer): | |||
| r""" | |||
| Base Class. Initialize the array with He kaiming algorithm. | |||
| Args: | |||
| a: the negative slope of the rectifier used after this layer (only | |||
| used with ``'leaky_relu'``) | |||
| mode: either ``'fan_in'`` (default) or ``'fan_out'``. Choosing ``'fan_in'`` | |||
| preserves the magnitude of the variance of the weights in the | |||
| forward pass. Choosing ``'fan_out'`` preserves the magnitudes in the | |||
| backwards pass. | |||
| nonlinearity: the non-linear function, recommended to use only with | |||
| ``'relu'`` or ``'leaky_relu'`` (default). | |||
| """ | |||
| def __init__(self, a=0, mode='fan_in', nonlinearity='leaky_relu'): | |||
| super(KaimingInit, self).__init__() | |||
| self.mode = mode | |||
| self.gain = _calculate_gain(nonlinearity, a) | |||
| def _initialize(self, arr): | |||
| pass | |||
| class KaimingUniform(KaimingInit): | |||
| r""" | |||
| Initialize the array with He kaiming uniform algorithm. The resulting tensor will | |||
| have values sampled from :math:`\mathcal{U}(-\text{bound}, \text{bound})` where | |||
| .. math:: | |||
| \text{bound} = \text{gain} \times \sqrt{\frac{3}{\text{fan\_mode}}} | |||
| Input: | |||
| arr (Array): The array to be assigned. | |||
| Returns: | |||
| Array, assigned array. | |||
| Examples: | |||
| >>> w = np.empty(3, 5) | |||
| >>> KaimingUniform(w, mode='fan_in', nonlinearity='relu') | |||
| """ | |||
| def _initialize(self, arr): | |||
| fan = _select_fan(arr, self.mode) | |||
| bound = math.sqrt(3.0)*self.gain / math.sqrt(fan) | |||
| np.random.seed(0) | |||
| data = np.random.uniform(-bound, bound, arr.shape) | |||
| _assignment(arr, data) | |||
| class KaimingNormal(KaimingInit): | |||
| r""" | |||
| Initialize the array with He kaiming normal algorithm. The resulting tensor will | |||
| have values sampled from :math:`\mathcal{N}(0, \text{std}^2)` where | |||
| .. math:: | |||
| \text{std} = \frac{\text{gain}}{\sqrt{\text{fan\_mode}}} | |||
| Input: | |||
| arr (Array): The array to be assigned. | |||
| Returns: | |||
| Array, assigned array. | |||
| Examples: | |||
| >>> w = np.empty(3, 5) | |||
| >>> KaimingNormal(w, mode='fan_out', nonlinearity='relu') | |||
| """ | |||
| def _initialize(self, arr): | |||
| fan = _select_fan(arr, self.mode) | |||
| std = self.gain / math.sqrt(fan) | |||
| np.random.seed(0) | |||
| data = np.random.normal(0, std, arr.shape) | |||
| _assignment(arr, data) | |||
| def default_recurisive_init(custom_cell): | |||
| """default_recurisive_init""" | |||
| for _, cell in custom_cell.cells_and_names(): | |||
| if isinstance(cell, nn.Conv2d): | |||
| cell.weight.default_input = init.initializer(KaimingUniform(a=math.sqrt(5)), | |||
| cell.weight.shape, | |||
| cell.weight.dtype) | |||
| if cell.bias is not None: | |||
| fan_in, _ = _calculate_in_and_out(cell.weight) | |||
| bound = 1 / math.sqrt(fan_in) | |||
| np.random.seed(0) | |||
| cell.bias.default_input = init.initializer(init.Uniform(bound), | |||
| cell.bias.shape, | |||
| cell.bias.dtype) | |||
| elif isinstance(cell, nn.Dense): | |||
| cell.weight.default_input = init.initializer(KaimingUniform(a=math.sqrt(5)), | |||
| cell.weight.shape, | |||
| cell.weight.dtype) | |||
| if cell.bias is not None: | |||
| fan_in, _ = _calculate_in_and_out(cell.weight) | |||
| bound = 1 / math.sqrt(fan_in) | |||
| np.random.seed(0) | |||
| cell.bias.default_input = init.initializer(init.Uniform(bound), | |||
| cell.bias.shape, | |||
| cell.bias.dtype) | |||
| elif isinstance(cell, (nn.BatchNorm2d, nn.BatchNorm1d)): | |||
| pass | |||
+ 0
- 142
examples/common/networks/vgg/vgg.py
View File
| @@ -1,142 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| Image classifiation. | |||
| """ | |||
| import math | |||
| import mindspore.nn as nn | |||
| import mindspore.common.dtype as mstype | |||
| from mindspore.common import initializer as init | |||
| from mindspore.common.initializer import initializer | |||
| from .utils.var_init import default_recurisive_init, KaimingNormal | |||
| def _make_layer(base, args, batch_norm): | |||
| """Make stage network of VGG.""" | |||
| layers = [] | |||
| in_channels = 3 | |||
| for v in base: | |||
| if v == 'M': | |||
| layers += [nn.MaxPool2d(kernel_size=2, stride=2)] | |||
| else: | |||
| weight_shape = (v, in_channels, 3, 3) | |||
| weight = initializer('XavierUniform', shape=weight_shape, dtype=mstype.float32).to_tensor() | |||
| if args.initialize_mode == "KaimingNormal": | |||
| weight = 'normal' | |||
| conv2d = nn.Conv2d(in_channels=in_channels, | |||
| out_channels=v, | |||
| kernel_size=3, | |||
| padding=args.padding, | |||
| pad_mode=args.pad_mode, | |||
| has_bias=args.has_bias, | |||
| weight_init=weight) | |||
| if batch_norm: | |||
| layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU()] | |||
| else: | |||
| layers += [conv2d, nn.ReLU()] | |||
| in_channels = v | |||
| return nn.SequentialCell(layers) | |||
| class Vgg(nn.Cell): | |||
| """ | |||
| VGG network definition. | |||
| Args: | |||
| base (list): Configuration for different layers, mainly the channel number of Conv layer. | |||
| num_classes (int): Class numbers. Default: 1000. | |||
| batch_norm (bool): Whether to do the batchnorm. Default: False. | |||
| batch_size (int): Batch size. Default: 1. | |||
| Returns: | |||
| Tensor, infer output tensor. | |||
| Examples: | |||
| >>> Vgg([64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'], | |||
| >>> num_classes=1000, batch_norm=False, batch_size=1) | |||
| """ | |||
| def __init__(self, base, num_classes=1000, batch_norm=False, batch_size=1, args=None, phase="train"): | |||
| super(Vgg, self).__init__() | |||
| _ = batch_size | |||
| self.layers = _make_layer(base, args, batch_norm=batch_norm) | |||
| self.flatten = nn.Flatten() | |||
| dropout_ratio = 0.5 | |||
| if not args.has_dropout or phase == "test": | |||
| dropout_ratio = 1.0 | |||
| self.classifier = nn.SequentialCell([ | |||
| nn.Dense(512*7*7, 4096), | |||
| nn.ReLU(), | |||
| nn.Dropout(dropout_ratio), | |||
| nn.Dense(4096, 4096), | |||
| nn.ReLU(), | |||
| nn.Dropout(dropout_ratio), | |||
| nn.Dense(4096, num_classes)]) | |||
| if args.initialize_mode == "KaimingNormal": | |||
| default_recurisive_init(self) | |||
| self.custom_init_weight() | |||
| def construct(self, x): | |||
| x = self.layers(x) | |||
| x = self.flatten(x) | |||
| x = self.classifier(x) | |||
| return x | |||
| def custom_init_weight(self): | |||
| """ | |||
| Init the weight of Conv2d and Dense in the net. | |||
| """ | |||
| for _, cell in self.cells_and_names(): | |||
| if isinstance(cell, nn.Conv2d): | |||
| cell.weight.default_input = init.initializer( | |||
| KaimingNormal(a=math.sqrt(5), mode='fan_out', nonlinearity='relu'), | |||
| cell.weight.shape, cell.weight.dtype) | |||
| if cell.bias is not None: | |||
| cell.bias.default_input = init.initializer( | |||
| 'zeros', cell.bias.shape, cell.bias.dtype) | |||
| elif isinstance(cell, nn.Dense): | |||
| cell.weight.default_input = init.initializer( | |||
| init.Normal(0.01), cell.weight.shape, cell.weight.dtype) | |||
| if cell.bias is not None: | |||
| cell.bias.default_input = init.initializer( | |||
| 'zeros', cell.bias.shape, cell.bias.dtype) | |||
| cfg = { | |||
| '11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], | |||
| '13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], | |||
| '16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'], | |||
| '19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'], | |||
| } | |||
| def vgg16(num_classes=1000, args=None, phase="train"): | |||
| """ | |||
| Get Vgg16 neural network with batch normalization. | |||
| Args: | |||
| num_classes (int): Class numbers. Default: 1000. | |||
| args(namespace): param for net init. | |||
| phase(str): train or test mode. | |||
| Returns: | |||
| Cell, cell instance of Vgg16 neural network with batch normalization. | |||
| Examples: | |||
| >>> vgg16(num_classes=1000, args=args) | |||
| """ | |||
| net = Vgg(cfg['16'], num_classes=num_classes, args=args, batch_norm=args.batch_norm, phase=phase) | |||
| return net | |||
+ 0
- 40
examples/common/networks/vgg/warmup_cosine_annealing_lr.py
View File
| @@ -1,40 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| warm up cosine annealing learning rate. | |||
| """ | |||
| import math | |||
| import numpy as np | |||
| from .linear_warmup import linear_warmup_lr | |||
| def warmup_cosine_annealing_lr(lr, steps_per_epoch, warmup_epochs, max_epoch, t_max, eta_min=0): | |||
| """warm up cosine annealing learning rate.""" | |||
| base_lr = lr | |||
| warmup_init_lr = 0 | |||
| total_steps = int(max_epoch*steps_per_epoch) | |||
| warmup_steps = int(warmup_epochs*steps_per_epoch) | |||
| lr_each_step = [] | |||
| for i in range(total_steps): | |||
| last_epoch = i // steps_per_epoch | |||
| if i < warmup_steps: | |||
| lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr) | |||
| else: | |||
| lr = eta_min + (base_lr - eta_min)*(1. + math.cos(math.pi*last_epoch / t_max)) / 2 | |||
| lr_each_step.append(lr) | |||
| return np.array(lr_each_step).astype(np.float32) | |||
+ 0
- 84
examples/common/networks/vgg/warmup_step_lr.py
View File
| @@ -1,84 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """ | |||
| warm up step learning rate. | |||
| """ | |||
| from collections import Counter | |||
| import numpy as np | |||
| from .linear_warmup import linear_warmup_lr | |||
| def lr_steps(global_step, lr_init, lr_max, warmup_epochs, total_epochs, steps_per_epoch): | |||
| """Set learning rate.""" | |||
| lr_each_step = [] | |||
| total_steps = steps_per_epoch*total_epochs | |||
| warmup_steps = steps_per_epoch*warmup_epochs | |||
| if warmup_steps != 0: | |||
| inc_each_step = (float(lr_max) - float(lr_init)) / float(warmup_steps) | |||
| else: | |||
| inc_each_step = 0 | |||
| for i in range(total_steps): | |||
| if i < warmup_steps: | |||
| lr_value = float(lr_init) + inc_each_step*float(i) | |||
| else: | |||
| base = (1.0 - (float(i) - float(warmup_steps)) / (float(total_steps) - float(warmup_steps))) | |||
| lr_value = float(lr_max)*base*base | |||
| if lr_value < 0.0: | |||
| lr_value = 0.0 | |||
| lr_each_step.append(lr_value) | |||
| current_step = global_step | |||
| lr_each_step = np.array(lr_each_step).astype(np.float32) | |||
| learning_rate = lr_each_step[current_step:] | |||
| return learning_rate | |||
| def warmup_step_lr(lr, lr_epochs, steps_per_epoch, warmup_epochs, max_epoch, gamma=0.1): | |||
| """warmup_step_lr""" | |||
| base_lr = lr | |||
| warmup_init_lr = 0 | |||
| total_steps = int(max_epoch*steps_per_epoch) | |||
| warmup_steps = int(warmup_epochs*steps_per_epoch) | |||
| milestones = lr_epochs | |||
| milestones_steps = [] | |||
| for milestone in milestones: | |||
| milestones_step = milestone*steps_per_epoch | |||
| milestones_steps.append(milestones_step) | |||
| lr_each_step = [] | |||
| lr = base_lr | |||
| milestones_steps_counter = Counter(milestones_steps) | |||
| for i in range(total_steps): | |||
| if i < warmup_steps: | |||
| lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr) | |||
| else: | |||
| lr = lr*gamma**milestones_steps_counter[i] | |||
| lr_each_step.append(lr) | |||
| return np.array(lr_each_step).astype(np.float32) | |||
| def multi_step_lr(lr, milestones, steps_per_epoch, max_epoch, gamma=0.1): | |||
| return warmup_step_lr(lr, milestones, steps_per_epoch, 0, max_epoch, gamma=gamma) | |||
| def step_lr(lr, epoch_size, steps_per_epoch, max_epoch, gamma=0.1): | |||
| lr_epochs = [] | |||
| for i in range(1, max_epoch): | |||
| if i % epoch_size == 0: | |||
| lr_epochs.append(i) | |||
| return multi_step_lr(lr, lr_epochs, steps_per_epoch, max_epoch, gamma=gamma) | |||
+ 0
- 0
examples/community/__init__.py
View File
+ 0
- 40
examples/model_security/README.md
View File
| @@ -1,40 +0,0 @@ | |||
| # Application demos of model security | |||
| ## Introduction | |||
| It has been proved that AI models are vulnerable to adversarial noise that invisible to human eye. Through those | |||
| demos in this package, you will learn to use the tools provided by MindArmour to generate adversarial samples and | |||
| also improve the robustness of your model. | |||
| ## 1. Generate adversarial samples (Attack method) | |||
| Attack methods can be classified into white box attack and black box attack. White-box attack means that the attacker | |||
| is accessible to the model structure and its parameters. Black-box means that the attacker can only obtain the predict | |||
| results of the | |||
| target model. | |||
| ### white-box attack | |||
| Running the classical attack method: FGSM-Attack. | |||
| ```sh | |||
| $ cd examples/model_security/model_attacks/white-box | |||
| $ python mnist_attack_fgsm.py | |||
| ``` | |||
| ### black-box attack | |||
| Running the classical black method: PSO-Attack. | |||
| ```sh | |||
| $ cd examples/model_security/model_attacks/black-box | |||
| $ python mnist_attack_pso.py | |||
| ``` | |||
| ## 2. Improve the robustness of models | |||
| ### adversarial training | |||
| Adversarial training is an effective method to enhance the model's robustness to attacks, in which generated | |||
| adversarial samples are fed into the model for retraining. | |||
| ```sh | |||
| $ cd examples/model_security/model_defenses | |||
| $ python mnist_defense_nad.py | |||
| ``` | |||
| ### adversarial detection | |||
| Besides adversarial training, there is another type of defense method: adversarial detection. This method is mainly | |||
| for black-box attack. The reason is that black-box attacks usually require frequent queries to the model, and the | |||
| difference between adjacent queries input is small. The detection algorithm could analyze the similarity of a series | |||
| of queries and recognize the attack. | |||
| ```sh | |||
| $ cd examples/model_security/model_defenses | |||
| $ python mnist_similarity_detector.py | |||
| ``` | |||
+ 0
- 0
examples/model_security/__init__.py
View File
+ 0
- 0
examples/model_security/model_attacks/__init__.py
View File
+ 0
- 0
examples/model_security/model_attacks/black_box/__init__.py
View File
+ 0
- 47
examples/model_security/model_attacks/cv/faster_rcnn/README.md
View File
| @@ -1,47 +0,0 @@ | |||
| # Dataset | |||
| Dataset used: [COCO2017](<https://cocodataset.org/>) | |||
| - Dataset size:19G | |||
| - Train:18G,118000 images | |||
| - Val:1G,5000 images | |||
| - Annotations:241M,instances,captions,person_keypoints etc | |||
| - Data format:image and json files | |||
| - Note:Data will be processed in dataset.py | |||
| # Environment Requirements | |||
| - Install [MindSpore](https://www.mindspore.cn/install/en). | |||
| - Download the dataset COCO2017. | |||
| - We use COCO2017 as dataset in this example. | |||
| Install Cython and pycocotool, and you can also install mmcv to process data. | |||
| ``` | |||
| pip install Cython | |||
| pip install pycocotools | |||
| pip install mmcv==0.2.14 | |||
| ``` | |||
| And change the COCO_ROOT and other settings you need in `config.py`. The directory structure is as follows: | |||
| ``` | |||
| . | |||
| └─cocodataset | |||
| ├─annotations | |||
| ├─instance_train2017.json | |||
| └─instance_val2017.json | |||
| ├─val2017 | |||
| └─train2017 | |||
| ``` | |||
| # Quick start | |||
| You can download the pre-trained model checkpoint file [here](<https://www.mindspore.cn/resources/hub/details?2505/MindSpore/ascend/0.7/fasterrcnn_v1.0_coco2017>). | |||
| ``` | |||
| python coco_attack_pgd.py --pre_trained [PRETRAINED_CHECKPOINT_FILE] | |||
| ``` | |||
| > Adversarial samples will be generated and saved as pickle file. | |||
+ 0
- 150
examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_genetic.py
View File
| @@ -1,150 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """PSO attack for Faster R-CNN""" | |||
| import os | |||
| import numpy as np | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.common import set_seed | |||
| from mindspore import Tensor | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks.black.genetic_attack import GeneticAttack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from src.FasterRcnn.faster_rcnn_r50 import Faster_Rcnn_Resnet50 | |||
| from src.config import config | |||
| from src.dataset import data_to_mindrecord_byte_image, create_fasterrcnn_dataset | |||
| # pylint: disable=locally-disabled, unused-argument, redefined-outer-name | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| set_seed(1) | |||
| context.set_context(mode=context.GRAPH_MODE, device_target='Ascend', device_id=1) | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, images, img_metas, gt_boxes, gt_labels, gt_num): | |||
| """predict""" | |||
| # Adapt to the input shape requirements of the target network if inputs is only one image. | |||
| if len(images.shape) == 3: | |||
| inputs_num = 1 | |||
| images = np.expand_dims(images, axis=0) | |||
| else: | |||
| inputs_num = images.shape[0] | |||
| box_and_confi = [] | |||
| pred_labels = [] | |||
| gt_number = np.sum(gt_num) | |||
| for i in range(inputs_num): | |||
| inputs_i = np.expand_dims(images[i], axis=0) | |||
| output = self._network(Tensor(inputs_i.astype(np.float16)), Tensor(img_metas), | |||
| Tensor(gt_boxes), Tensor(gt_labels), Tensor(gt_num)) | |||
| all_bbox = output[0] | |||
| all_labels = output[1] | |||
| all_mask = output[2] | |||
| all_bbox_squee = np.squeeze(all_bbox.asnumpy()) | |||
| all_labels_squee = np.squeeze(all_labels.asnumpy()) | |||
| all_mask_squee = np.squeeze(all_mask.asnumpy()) | |||
| all_bboxes_tmp_mask = all_bbox_squee[all_mask_squee, :] | |||
| all_labels_tmp_mask = all_labels_squee[all_mask_squee] | |||
| if all_bboxes_tmp_mask.shape[0] > gt_number + 1: | |||
| inds = np.argsort(-all_bboxes_tmp_mask[:, -1]) | |||
| inds = inds[:gt_number+1] | |||
| all_bboxes_tmp_mask = all_bboxes_tmp_mask[inds] | |||
| all_labels_tmp_mask = all_labels_tmp_mask[inds] | |||
| box_and_confi.append(all_bboxes_tmp_mask) | |||
| pred_labels.append(all_labels_tmp_mask) | |||
| return np.array(box_and_confi), np.array(pred_labels) | |||
| if __name__ == '__main__': | |||
| prefix = 'FasterRcnn_eval.mindrecord' | |||
| mindrecord_dir = config.mindrecord_dir | |||
| mindrecord_file = os.path.join(mindrecord_dir, prefix) | |||
| pre_trained = '/ckpt_path' | |||
| print("CHECKING MINDRECORD FILES ...") | |||
| if not os.path.exists(mindrecord_file): | |||
| if not os.path.isdir(mindrecord_dir): | |||
| os.makedirs(mindrecord_dir) | |||
| if os.path.isdir(config.coco_root): | |||
| print("Create Mindrecord. It may take some time.") | |||
| data_to_mindrecord_byte_image("coco", False, prefix, file_num=1) | |||
| print("Create Mindrecord Done, at {}".format(mindrecord_dir)) | |||
| else: | |||
| print("coco_root not exits.") | |||
| print('Start generate adversarial samples.') | |||
| # build network and dataset | |||
| ds = create_fasterrcnn_dataset(mindrecord_file, batch_size=config.test_batch_size, \ | |||
| repeat_num=1, is_training=False) | |||
| net = Faster_Rcnn_Resnet50(config) | |||
| param_dict = load_checkpoint(pre_trained) | |||
| load_param_into_net(net, param_dict) | |||
| net = net.set_train(False) | |||
| # build attacker | |||
| model = ModelToBeAttacked(net) | |||
| attack = GeneticAttack(model, model_type='detection', max_steps=50, reserve_ratio=0.3, mutation_rate=0.05, | |||
| per_bounds=0.5, step_size=0.25, temp=0.1) | |||
| # generate adversarial samples | |||
| sample_num = 5 | |||
| ori_imagess = [] | |||
| adv_imgs = [] | |||
| ori_meta = [] | |||
| ori_box = [] | |||
| ori_labels = [] | |||
| ori_gt_num = [] | |||
| idx = 0 | |||
| for data in ds.create_dict_iterator(): | |||
| if idx > sample_num: | |||
| break | |||
| img_data = data['image'] | |||
| img_metas = data['image_shape'] | |||
| gt_bboxes = data['box'] | |||
| gt_labels = data['label'] | |||
| gt_num = data['valid_num'] | |||
| ori_imagess.append(img_data.asnumpy()) | |||
| ori_meta.append(img_metas.asnumpy()) | |||
| ori_box.append(gt_bboxes.asnumpy()) | |||
| ori_labels.append(gt_labels.asnumpy()) | |||
| ori_gt_num.append(gt_num.asnumpy()) | |||
| all_inputs = (img_data.asnumpy(), img_metas.asnumpy(), gt_bboxes.asnumpy(), | |||
| gt_labels.asnumpy(), gt_num.asnumpy()) | |||
| pre_gt_boxes, pre_gt_label = model.predict(*all_inputs) | |||
| success_flags, adv_img, query_times = attack.generate(all_inputs, (pre_gt_boxes, pre_gt_label)) | |||
| adv_imgs.append(adv_img) | |||
| idx += 1 | |||
| np.save('ori_imagess.npy', ori_imagess) | |||
| np.save('ori_meta.npy', ori_meta) | |||
| np.save('ori_box.npy', ori_box) | |||
| np.save('ori_labels.npy', ori_labels) | |||
| np.save('ori_gt_num.npy', ori_gt_num) | |||
| np.save('adv_imgs.npy', adv_imgs) | |||
| print('Generate adversarial samples complete.') | |||
+ 0
- 135
examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_pgd.py
View File
| @@ -1,135 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """PGD attack for faster rcnn""" | |||
| import os | |||
| import argparse | |||
| import pickle | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.common import set_seed | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops.composite import GradOperation | |||
| from mindarmour.adv_robustness.attacks import ProjectedGradientDescent | |||
| from src.FasterRcnn.faster_rcnn_r50 import Faster_Rcnn_Resnet50 | |||
| from src.config import config | |||
| from src.dataset import data_to_mindrecord_byte_image, create_fasterrcnn_dataset | |||
| # pylint: disable=locally-disabled, unused-argument, redefined-outer-name | |||
| set_seed(1) | |||
| parser = argparse.ArgumentParser(description='FasterRCNN attack') | |||
| parser.add_argument('--pre_trained', type=str, required=True, help='pre-trained ckpt file path for target model.') | |||
| parser.add_argument('--device_id', type=int, default=0, help='Device id, default is 0.') | |||
| parser.add_argument('--num', type=int, default=5, help='Number of adversarial examples.') | |||
| args = parser.parse_args() | |||
| context.set_context(mode=context.GRAPH_MODE, device_target='Ascend', device_id=args.device_id) | |||
| class LossNet(Cell): | |||
| """loss function.""" | |||
| def construct(self, x1, x2, x3, x4, x5, x6): | |||
| return x4 + x6 | |||
| class WithLossCell(Cell): | |||
| """Wrap the network with loss function.""" | |||
| def __init__(self, backbone, loss_fn): | |||
| super(WithLossCell, self).__init__(auto_prefix=False) | |||
| self._backbone = backbone | |||
| self._loss_fn = loss_fn | |||
| def construct(self, img_data, img_metas, gt_bboxes, gt_labels, gt_num, *labels): | |||
| loss1, loss2, loss3, loss4, loss5, loss6 = self._backbone(img_data, img_metas, gt_bboxes, gt_labels, gt_num) | |||
| return self._loss_fn(loss1, loss2, loss3, loss4, loss5, loss6) | |||
| @property | |||
| def backbone_network(self): | |||
| return self._backbone | |||
| class GradWrapWithLoss(Cell): | |||
| """ | |||
| Construct a network to compute the gradient of loss function in \ | |||
| input space and weighted by `weight`. | |||
| """ | |||
| def __init__(self, network): | |||
| super(GradWrapWithLoss, self).__init__() | |||
| self._grad_all = GradOperation(get_all=True, sens_param=False) | |||
| self._network = network | |||
| def construct(self, *inputs): | |||
| gout = self._grad_all(self._network)(*inputs) | |||
| return gout[0] | |||
| if __name__ == '__main__': | |||
| prefix = 'FasterRcnn_eval.mindrecord' | |||
| mindrecord_dir = config.mindrecord_dir | |||
| mindrecord_file = os.path.join(mindrecord_dir, prefix) | |||
| pre_trained = args.pre_trained | |||
| print("CHECKING MINDRECORD FILES ...") | |||
| if not os.path.exists(mindrecord_file): | |||
| if not os.path.isdir(mindrecord_dir): | |||
| os.makedirs(mindrecord_dir) | |||
| if os.path.isdir(config.coco_root): | |||
| print("Create Mindrecord. It may take some time.") | |||
| data_to_mindrecord_byte_image("coco", False, prefix, file_num=1) | |||
| print("Create Mindrecord Done, at {}".format(mindrecord_dir)) | |||
| else: | |||
| print("coco_root not exits.") | |||
| print('Start generate adversarial samples.') | |||
| # build network and dataset | |||
| ds = create_fasterrcnn_dataset(mindrecord_file, batch_size=config.test_batch_size, \ | |||
| repeat_num=1, is_training=True) | |||
| net = Faster_Rcnn_Resnet50(config) | |||
| param_dict = load_checkpoint(pre_trained) | |||
| load_param_into_net(net, param_dict) | |||
| net = net.set_train() | |||
| # build attacker | |||
| with_loss_cell = WithLossCell(net, LossNet()) | |||
| grad_with_loss_net = GradWrapWithLoss(with_loss_cell) | |||
| attack = ProjectedGradientDescent(grad_with_loss_net, bounds=None, eps=0.1) | |||
| # generate adversarial samples | |||
| num = args.num | |||
| num_batches = num // config.test_batch_size | |||
| channel = 3 | |||
| adv_samples = [0]*(num_batches*config.test_batch_size) | |||
| adv_id = 0 | |||
| for data in ds.create_dict_iterator(num_epochs=num_batches): | |||
| img_data = data['image'] | |||
| img_metas = data['image_shape'] | |||
| gt_bboxes = data['box'] | |||
| gt_labels = data['label'] | |||
| gt_num = data['valid_num'] | |||
| adv_img = attack.generate((img_data.asnumpy(), \ | |||
| img_metas.asnumpy(), gt_bboxes.asnumpy(), gt_labels.asnumpy(), gt_num.asnumpy()), gt_labels.asnumpy()) | |||
| for item in adv_img: | |||
| adv_samples[adv_id] = item | |||
| adv_id += 1 | |||
| if adv_id >= num_batches*config.test_batch_size: | |||
| break | |||
| pickle.dump(adv_samples, open('adv_samples.pkl', 'wb')) | |||
| print('Generate adversarial samples complete.') | |||
+ 0
- 149
examples/model_security/model_attacks/cv/faster_rcnn/coco_attack_pso.py
View File
| @@ -1,149 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """PSO attack for Faster R-CNN""" | |||
| import os | |||
| import numpy as np | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.common import set_seed | |||
| from mindspore import Tensor | |||
| from mindarmour import BlackModel | |||
| from mindarmour.adv_robustness.attacks.black.pso_attack import PSOAttack | |||
| from mindarmour.utils.logger import LogUtil | |||
| from src.FasterRcnn.faster_rcnn_r50 import Faster_Rcnn_Resnet50 | |||
| from src.config import config | |||
| from src.dataset import data_to_mindrecord_byte_image, create_fasterrcnn_dataset | |||
| # pylint: disable=locally-disabled, unused-argument, redefined-outer-name | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level('INFO') | |||
| set_seed(1) | |||
| context.set_context(mode=context.GRAPH_MODE, device_target='Ascend', device_id=1) | |||
| class ModelToBeAttacked(BlackModel): | |||
| """model to be attack""" | |||
| def __init__(self, network): | |||
| super(ModelToBeAttacked, self).__init__() | |||
| self._network = network | |||
| def predict(self, images, img_metas, gt_boxes, gt_labels, gt_num): | |||
| """predict""" | |||
| # Adapt to the input shape requirements of the target network if inputs is only one image. | |||
| if len(images.shape) == 3: | |||
| inputs_num = 1 | |||
| images = np.expand_dims(images, axis=0) | |||
| else: | |||
| inputs_num = images.shape[0] | |||
| box_and_confi = [] | |||
| pred_labels = [] | |||
| gt_number = np.sum(gt_num) | |||
| for i in range(inputs_num): | |||
| inputs_i = np.expand_dims(images[i], axis=0) | |||
| output = self._network(Tensor(inputs_i.astype(np.float16)), Tensor(img_metas), | |||
| Tensor(gt_boxes), Tensor(gt_labels), Tensor(gt_num)) | |||
| all_bbox = output[0] | |||
| all_labels = output[1] | |||
| all_mask = output[2] | |||
| all_bbox_squee = np.squeeze(all_bbox.asnumpy()) | |||
| all_labels_squee = np.squeeze(all_labels.asnumpy()) | |||
| all_mask_squee = np.squeeze(all_mask.asnumpy()) | |||
| all_bboxes_tmp_mask = all_bbox_squee[all_mask_squee, :] | |||
| all_labels_tmp_mask = all_labels_squee[all_mask_squee] | |||
| if all_bboxes_tmp_mask.shape[0] > gt_number + 1: | |||
| inds = np.argsort(-all_bboxes_tmp_mask[:, -1]) | |||
| inds = inds[:gt_number+1] | |||
| all_bboxes_tmp_mask = all_bboxes_tmp_mask[inds] | |||
| all_labels_tmp_mask = all_labels_tmp_mask[inds] | |||
| box_and_confi.append(all_bboxes_tmp_mask) | |||
| pred_labels.append(all_labels_tmp_mask) | |||
| return np.array(box_and_confi), np.array(pred_labels) | |||
| if __name__ == '__main__': | |||
| prefix = 'FasterRcnn_eval.mindrecord' | |||
| mindrecord_dir = config.mindrecord_dir | |||
| mindrecord_file = os.path.join(mindrecord_dir, prefix) | |||
| pre_trained = '/ckpt_path' | |||
| print("CHECKING MINDRECORD FILES ...") | |||
| if not os.path.exists(mindrecord_file): | |||
| if not os.path.isdir(mindrecord_dir): | |||
| os.makedirs(mindrecord_dir) | |||
| if os.path.isdir(config.coco_root): | |||
| print("Create Mindrecord. It may take some time.") | |||
| data_to_mindrecord_byte_image("coco", False, prefix, file_num=1) | |||
| print("Create Mindrecord Done, at {}".format(mindrecord_dir)) | |||
| else: | |||
| print("coco_root not exits.") | |||
| print('Start generate adversarial samples.') | |||
| # build network and dataset | |||
| ds = create_fasterrcnn_dataset(mindrecord_file, batch_size=config.test_batch_size, \ | |||
| repeat_num=1, is_training=False) | |||
| net = Faster_Rcnn_Resnet50(config) | |||
| param_dict = load_checkpoint(pre_trained) | |||
| load_param_into_net(net, param_dict) | |||
| net = net.set_train(False) | |||
| # build attacker | |||
| model = ModelToBeAttacked(net) | |||
| attack = PSOAttack(model, c=0.2, t_max=50, pm=0.5, model_type='detection', reserve_ratio=0.3) | |||
| # generate adversarial samples | |||
| sample_num = 5 | |||
| ori_imagess = [] | |||
| adv_imgs = [] | |||
| ori_meta = [] | |||
| ori_box = [] | |||
| ori_labels = [] | |||
| ori_gt_num = [] | |||
| idx = 0 | |||
| for data in ds.create_dict_iterator(): | |||
| if idx > sample_num: | |||
| break | |||
| img_data = data['image'] | |||
| img_metas = data['image_shape'] | |||
| gt_bboxes = data['box'] | |||
| gt_labels = data['label'] | |||
| gt_num = data['valid_num'] | |||
| ori_imagess.append(img_data.asnumpy()) | |||
| ori_meta.append(img_metas.asnumpy()) | |||
| ori_box.append(gt_bboxes.asnumpy()) | |||
| ori_labels.append(gt_labels.asnumpy()) | |||
| ori_gt_num.append(gt_num.asnumpy()) | |||
| all_inputs = (img_data.asnumpy(), img_metas.asnumpy(), gt_bboxes.asnumpy(), | |||
| gt_labels.asnumpy(), gt_num.asnumpy()) | |||
| pre_gt_boxes, pre_gt_label = model.predict(*all_inputs) | |||
| success_flags, adv_img, query_times = attack.generate(all_inputs, (pre_gt_boxes, pre_gt_label)) | |||
| adv_imgs.append(adv_img) | |||
| idx += 1 | |||
| np.save('ori_imagess.npy', ori_imagess) | |||
| np.save('ori_meta.npy', ori_meta) | |||
| np.save('ori_box.npy', ori_box) | |||
| np.save('ori_labels.npy', ori_labels) | |||
| np.save('ori_gt_num.npy', ori_gt_num) | |||
| np.save('adv_imgs.npy', adv_imgs) | |||
| print('Generate adversarial samples complete.') | |||
+ 0
- 31
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/__init__.py
View File
| @@ -1,31 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn Init.""" | |||
| from .resnet50 import ResNetFea, ResidualBlockUsing | |||
| from .bbox_assign_sample import BboxAssignSample | |||
| from .bbox_assign_sample_stage2 import BboxAssignSampleForRcnn | |||
| from .fpn_neck import FeatPyramidNeck | |||
| from .proposal_generator import Proposal | |||
| from .rcnn import Rcnn | |||
| from .rpn import RPN | |||
| from .roi_align import SingleRoIExtractor | |||
| from .anchor_generator import AnchorGenerator | |||
| __all__ = [ | |||
| "ResNetFea", "BboxAssignSample", "BboxAssignSampleForRcnn", | |||
| "FeatPyramidNeck", "Proposal", "Rcnn", | |||
| "RPN", "SingleRoIExtractor", "AnchorGenerator", "ResidualBlockUsing" | |||
| ] | |||
+ 0
- 84
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/anchor_generator.py
View File
| @@ -1,84 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn anchor generator.""" | |||
| import numpy as np | |||
| class AnchorGenerator(): | |||
| """Anchor generator for FasterRcnn.""" | |||
| def __init__(self, base_size, scales, ratios, scale_major=True, ctr=None): | |||
| """Anchor generator init method.""" | |||
| self.base_size = base_size | |||
| self.scales = np.array(scales) | |||
| self.ratios = np.array(ratios) | |||
| self.scale_major = scale_major | |||
| self.ctr = ctr | |||
| self.base_anchors = self.gen_base_anchors() | |||
| def gen_base_anchors(self): | |||
| """Generate a single anchor.""" | |||
| w = self.base_size | |||
| h = self.base_size | |||
| if self.ctr is None: | |||
| x_ctr = 0.5 * (w - 1) | |||
| y_ctr = 0.5 * (h - 1) | |||
| else: | |||
| x_ctr, y_ctr = self.ctr | |||
| h_ratios = np.sqrt(self.ratios) | |||
| w_ratios = 1 / h_ratios | |||
| if self.scale_major: | |||
| ws = (w * w_ratios[:, None] * self.scales[None, :]).reshape(-1) | |||
| hs = (h * h_ratios[:, None] * self.scales[None, :]).reshape(-1) | |||
| else: | |||
| ws = (w * self.scales[:, None] * w_ratios[None, :]).reshape(-1) | |||
| hs = (h * self.scales[:, None] * h_ratios[None, :]).reshape(-1) | |||
| base_anchors = np.stack( | |||
| [ | |||
| x_ctr - 0.5 * (ws - 1), y_ctr - 0.5 * (hs - 1), | |||
| x_ctr + 0.5 * (ws - 1), y_ctr + 0.5 * (hs - 1) | |||
| ], | |||
| axis=-1).round() | |||
| return base_anchors | |||
| def _meshgrid(self, x, y, row_major=True): | |||
| """Generate grid.""" | |||
| xx = np.repeat(x.reshape(1, len(x)), len(y), axis=0).reshape(-1) | |||
| yy = np.repeat(y, len(x)) | |||
| if row_major: | |||
| return xx, yy | |||
| return yy, xx | |||
| def grid_anchors(self, featmap_size, stride=16): | |||
| """Generate anchor list.""" | |||
| base_anchors = self.base_anchors | |||
| feat_h, feat_w = featmap_size | |||
| shift_x = np.arange(0, feat_w) * stride | |||
| shift_y = np.arange(0, feat_h) * stride | |||
| shift_xx, shift_yy = self._meshgrid(shift_x, shift_y) | |||
| shifts = np.stack([shift_xx, shift_yy, shift_xx, shift_yy], axis=-1) | |||
| shifts = shifts.astype(base_anchors.dtype) | |||
| # first feat_w elements correspond to the first row of shifts | |||
| # add A anchors (1, A, 4) to K shifts (K, 1, 4) to get | |||
| # shifted anchors (K, A, 4), reshape to (K*A, 4) | |||
| all_anchors = base_anchors[None, :, :] + shifts[:, None, :] | |||
| all_anchors = all_anchors.reshape(-1, 4) | |||
| return all_anchors | |||
+ 0
- 166
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/bbox_assign_sample.py
View File
| @@ -1,166 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn positive and negative sample screening for RPN.""" | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| from mindspore.ops import operations as P | |||
| from mindspore.common.tensor import Tensor | |||
| import mindspore.common.dtype as mstype | |||
| # pylint: disable=locally-disabled, invalid-name, missing-docstring | |||
| class BboxAssignSample(nn.Cell): | |||
| """ | |||
| Bbox assigner and sampler defination. | |||
| Args: | |||
| config (dict): Config. | |||
| batch_size (int): Batchsize. | |||
| num_bboxes (int): The anchor nums. | |||
| add_gt_as_proposals (bool): add gt bboxes as proposals flag. | |||
| Returns: | |||
| Tensor, output tensor. | |||
| bbox_targets: bbox location, (batch_size, num_bboxes, 4) | |||
| bbox_weights: bbox weights, (batch_size, num_bboxes, 1) | |||
| labels: label for every bboxes, (batch_size, num_bboxes, 1) | |||
| label_weights: label weight for every bboxes, (batch_size, num_bboxes, 1) | |||
| Examples: | |||
| BboxAssignSample(config, 2, 1024, True) | |||
| """ | |||
| def __init__(self, config, batch_size, num_bboxes, add_gt_as_proposals): | |||
| super(BboxAssignSample, self).__init__() | |||
| cfg = config | |||
| self.batch_size = batch_size | |||
| self.neg_iou_thr = Tensor(cfg.neg_iou_thr, mstype.float16) | |||
| self.pos_iou_thr = Tensor(cfg.pos_iou_thr, mstype.float16) | |||
| self.min_pos_iou = Tensor(cfg.min_pos_iou, mstype.float16) | |||
| self.zero_thr = Tensor(0.0, mstype.float16) | |||
| self.num_bboxes = num_bboxes | |||
| self.num_gts = cfg.num_gts | |||
| self.num_expected_pos = cfg.num_expected_pos | |||
| self.num_expected_neg = cfg.num_expected_neg | |||
| self.add_gt_as_proposals = add_gt_as_proposals | |||
| if self.add_gt_as_proposals: | |||
| self.label_inds = Tensor(np.arange(1, self.num_gts + 1)) | |||
| self.concat = P.Concat(axis=0) | |||
| self.max_gt = P.ArgMaxWithValue(axis=0) | |||
| self.max_anchor = P.ArgMaxWithValue(axis=1) | |||
| self.sum_inds = P.ReduceSum() | |||
| self.iou = P.IOU() | |||
| self.greaterequal = P.GreaterEqual() | |||
| self.greater = P.Greater() | |||
| self.select = P.Select() | |||
| self.gatherND = P.GatherNd() | |||
| self.squeeze = P.Squeeze() | |||
| self.cast = P.Cast() | |||
| self.logicaland = P.LogicalAnd() | |||
| self.less = P.Less() | |||
| self.random_choice_with_mask_pos = P.RandomChoiceWithMask(self.num_expected_pos) | |||
| self.random_choice_with_mask_neg = P.RandomChoiceWithMask(self.num_expected_neg) | |||
| self.reshape = P.Reshape() | |||
| self.equal = P.Equal() | |||
| self.bounding_box_encode = P.BoundingBoxEncode(means=(0.0, 0.0, 0.0, 0.0), stds=(1.0, 1.0, 1.0, 1.0)) | |||
| self.scatterNdUpdate = P.ScatterNdUpdate() | |||
| self.scatterNd = P.ScatterNd() | |||
| self.logicalnot = P.LogicalNot() | |||
| self.tile = P.Tile() | |||
| self.zeros_like = P.ZerosLike() | |||
| self.assigned_gt_inds = Tensor(np.array(-1 * np.ones(num_bboxes), dtype=np.int32)) | |||
| self.assigned_gt_zeros = Tensor(np.array(np.zeros(num_bboxes), dtype=np.int32)) | |||
| self.assigned_gt_ones = Tensor(np.array(np.ones(num_bboxes), dtype=np.int32)) | |||
| self.assigned_gt_ignores = Tensor(np.array(-1 * np.ones(num_bboxes), dtype=np.int32)) | |||
| self.assigned_pos_ones = Tensor(np.array(np.ones(self.num_expected_pos), dtype=np.int32)) | |||
| self.check_neg_mask = Tensor(np.array(np.ones(self.num_expected_neg - self.num_expected_pos), dtype=np.bool)) | |||
| self.range_pos_size = Tensor(np.arange(self.num_expected_pos).astype(np.float16)) | |||
| self.check_gt_one = Tensor(np.array(-1 * np.ones((self.num_gts, 4)), dtype=np.float16)) | |||
| self.check_anchor_two = Tensor(np.array(-2 * np.ones((self.num_bboxes, 4)), dtype=np.float16)) | |||
| def construct(self, gt_bboxes_i, gt_labels_i, valid_mask, bboxes, gt_valids): | |||
| gt_bboxes_i = self.select(self.cast(self.tile(self.reshape(self.cast(gt_valids, mstype.int32), \ | |||
| (self.num_gts, 1)), (1, 4)), mstype.bool_), gt_bboxes_i, self.check_gt_one) | |||
| bboxes = self.select(self.cast(self.tile(self.reshape(self.cast(valid_mask, mstype.int32), \ | |||
| (self.num_bboxes, 1)), (1, 4)), mstype.bool_), bboxes, self.check_anchor_two) | |||
| overlaps = self.iou(bboxes, gt_bboxes_i) | |||
| max_overlaps_w_gt_index, max_overlaps_w_gt = self.max_gt(overlaps) | |||
| _, max_overlaps_w_ac = self.max_anchor(overlaps) | |||
| neg_sample_iou_mask = self.logicaland(self.greaterequal(max_overlaps_w_gt, self.zero_thr), \ | |||
| self.less(max_overlaps_w_gt, self.neg_iou_thr)) | |||
| assigned_gt_inds2 = self.select(neg_sample_iou_mask, self.assigned_gt_zeros, self.assigned_gt_inds) | |||
| pos_sample_iou_mask = self.greaterequal(max_overlaps_w_gt, self.pos_iou_thr) | |||
| assigned_gt_inds3 = self.select(pos_sample_iou_mask, \ | |||
| max_overlaps_w_gt_index + self.assigned_gt_ones, assigned_gt_inds2) | |||
| assigned_gt_inds4 = assigned_gt_inds3 | |||
| for j in range(self.num_gts): | |||
| max_overlaps_w_ac_j = max_overlaps_w_ac[j:j+1:1] | |||
| overlaps_w_gt_j = self.squeeze(overlaps[j:j+1:1, ::]) | |||
| pos_mask_j = self.logicaland(self.greaterequal(max_overlaps_w_ac_j, self.min_pos_iou), \ | |||
| self.equal(overlaps_w_gt_j, max_overlaps_w_ac_j)) | |||
| assigned_gt_inds4 = self.select(pos_mask_j, self.assigned_gt_ones + j, assigned_gt_inds4) | |||
| assigned_gt_inds5 = self.select(valid_mask, assigned_gt_inds4, self.assigned_gt_ignores) | |||
| pos_index, valid_pos_index = self.random_choice_with_mask_pos(self.greater(assigned_gt_inds5, 0)) | |||
| pos_check_valid = self.cast(self.greater(assigned_gt_inds5, 0), mstype.float16) | |||
| pos_check_valid = self.sum_inds(pos_check_valid, -1) | |||
| valid_pos_index = self.less(self.range_pos_size, pos_check_valid) | |||
| pos_index = pos_index * self.reshape(self.cast(valid_pos_index, mstype.int32), (self.num_expected_pos, 1)) | |||
| pos_assigned_gt_index = self.gatherND(assigned_gt_inds5, pos_index) - self.assigned_pos_ones | |||
| pos_assigned_gt_index = pos_assigned_gt_index * self.cast(valid_pos_index, mstype.int32) | |||
| pos_assigned_gt_index = self.reshape(pos_assigned_gt_index, (self.num_expected_pos, 1)) | |||
| neg_index, valid_neg_index = self.random_choice_with_mask_neg(self.equal(assigned_gt_inds5, 0)) | |||
| num_pos = self.cast(self.logicalnot(valid_pos_index), mstype.float16) | |||
| num_pos = self.sum_inds(num_pos, -1) | |||
| unvalid_pos_index = self.less(self.range_pos_size, num_pos) | |||
| valid_neg_index = self.logicaland(self.concat((self.check_neg_mask, unvalid_pos_index)), valid_neg_index) | |||
| pos_bboxes_ = self.gatherND(bboxes, pos_index) | |||
| pos_gt_bboxes_ = self.gatherND(gt_bboxes_i, pos_assigned_gt_index) | |||
| pos_gt_labels = self.gatherND(gt_labels_i, pos_assigned_gt_index) | |||
| pos_bbox_targets_ = self.bounding_box_encode(pos_bboxes_, pos_gt_bboxes_) | |||
| valid_pos_index = self.cast(valid_pos_index, mstype.int32) | |||
| valid_neg_index = self.cast(valid_neg_index, mstype.int32) | |||
| bbox_targets_total = self.scatterNd(pos_index, pos_bbox_targets_, (self.num_bboxes, 4)) | |||
| bbox_weights_total = self.scatterNd(pos_index, valid_pos_index, (self.num_bboxes,)) | |||
| labels_total = self.scatterNd(pos_index, pos_gt_labels, (self.num_bboxes,)) | |||
| total_index = self.concat((pos_index, neg_index)) | |||
| total_valid_index = self.concat((valid_pos_index, valid_neg_index)) | |||
| label_weights_total = self.scatterNd(total_index, total_valid_index, (self.num_bboxes,)) | |||
| return bbox_targets_total, self.cast(bbox_weights_total, mstype.bool_), \ | |||
| labels_total, self.cast(label_weights_total, mstype.bool_) | |||
+ 0
- 197
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/bbox_assign_sample_stage2.py
View File
| @@ -1,197 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn tpositive and negative sample screening for Rcnn.""" | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| import mindspore.common.dtype as mstype | |||
| from mindspore.ops import operations as P | |||
| from mindspore.common.tensor import Tensor | |||
| # pylint: disable=locally-disabled, invalid-name, missing-docstring | |||
| class BboxAssignSampleForRcnn(nn.Cell): | |||
| """ | |||
| Bbox assigner and sampler defination. | |||
| Args: | |||
| config (dict): Config. | |||
| batch_size (int): Batchsize. | |||
| num_bboxes (int): The anchor nums. | |||
| add_gt_as_proposals (bool): add gt bboxes as proposals flag. | |||
| Returns: | |||
| Tensor, output tensor. | |||
| bbox_targets: bbox location, (batch_size, num_bboxes, 4) | |||
| bbox_weights: bbox weights, (batch_size, num_bboxes, 1) | |||
| labels: label for every bboxes, (batch_size, num_bboxes, 1) | |||
| label_weights: label weight for every bboxes, (batch_size, num_bboxes, 1) | |||
| Examples: | |||
| BboxAssignSampleForRcnn(config, 2, 1024, True) | |||
| """ | |||
| def __init__(self, config, batch_size, num_bboxes, add_gt_as_proposals): | |||
| super(BboxAssignSampleForRcnn, self).__init__() | |||
| cfg = config | |||
| self.batch_size = batch_size | |||
| self.neg_iou_thr = cfg.neg_iou_thr_stage2 | |||
| self.pos_iou_thr = cfg.pos_iou_thr_stage2 | |||
| self.min_pos_iou = cfg.min_pos_iou_stage2 | |||
| self.num_gts = cfg.num_gts | |||
| self.num_bboxes = num_bboxes | |||
| self.num_expected_pos = cfg.num_expected_pos_stage2 | |||
| self.num_expected_neg = cfg.num_expected_neg_stage2 | |||
| self.num_expected_total = cfg.num_expected_total_stage2 | |||
| self.add_gt_as_proposals = add_gt_as_proposals | |||
| self.label_inds = Tensor(np.arange(1, self.num_gts + 1).astype(np.int32)) | |||
| self.add_gt_as_proposals_valid = Tensor(np.array(self.add_gt_as_proposals * np.ones(self.num_gts), | |||
| dtype=np.int32)) | |||
| self.concat = P.Concat(axis=0) | |||
| self.max_gt = P.ArgMaxWithValue(axis=0) | |||
| self.max_anchor = P.ArgMaxWithValue(axis=1) | |||
| self.sum_inds = P.ReduceSum() | |||
| self.iou = P.IOU() | |||
| self.greaterequal = P.GreaterEqual() | |||
| self.greater = P.Greater() | |||
| self.select = P.Select() | |||
| self.gatherND = P.GatherNd() | |||
| self.squeeze = P.Squeeze() | |||
| self.cast = P.Cast() | |||
| self.logicaland = P.LogicalAnd() | |||
| self.less = P.Less() | |||
| self.random_choice_with_mask_pos = P.RandomChoiceWithMask(self.num_expected_pos) | |||
| self.random_choice_with_mask_neg = P.RandomChoiceWithMask(self.num_expected_neg) | |||
| self.reshape = P.Reshape() | |||
| self.equal = P.Equal() | |||
| self.bounding_box_encode = P.BoundingBoxEncode(means=(0.0, 0.0, 0.0, 0.0), stds=(0.1, 0.1, 0.2, 0.2)) | |||
| self.concat_axis1 = P.Concat(axis=1) | |||
| self.logicalnot = P.LogicalNot() | |||
| self.tile = P.Tile() | |||
| # Check | |||
| self.check_gt_one = Tensor(np.array(-1 * np.ones((self.num_gts, 4)), dtype=np.float16)) | |||
| self.check_anchor_two = Tensor(np.array(-2 * np.ones((self.num_bboxes, 4)), dtype=np.float16)) | |||
| # Init tensor | |||
| self.assigned_gt_inds = Tensor(np.array(-1 * np.ones(num_bboxes), dtype=np.int32)) | |||
| self.assigned_gt_zeros = Tensor(np.array(np.zeros(num_bboxes), dtype=np.int32)) | |||
| self.assigned_gt_ones = Tensor(np.array(np.ones(num_bboxes), dtype=np.int32)) | |||
| self.assigned_gt_ignores = Tensor(np.array(-1 * np.ones(num_bboxes), dtype=np.int32)) | |||
| self.assigned_pos_ones = Tensor(np.array(np.ones(self.num_expected_pos), dtype=np.int32)) | |||
| self.gt_ignores = Tensor(np.array(-1 * np.ones(self.num_gts), dtype=np.int32)) | |||
| self.range_pos_size = Tensor(np.arange(self.num_expected_pos).astype(np.float16)) | |||
| self.check_neg_mask = Tensor(np.array(np.ones(self.num_expected_neg - self.num_expected_pos), dtype=np.bool)) | |||
| self.bboxs_neg_mask = Tensor(np.zeros((self.num_expected_neg, 4), dtype=np.float16)) | |||
| self.labels_neg_mask = Tensor(np.array(np.zeros(self.num_expected_neg), dtype=np.uint8)) | |||
| self.reshape_shape_pos = (self.num_expected_pos, 1) | |||
| self.reshape_shape_neg = (self.num_expected_neg, 1) | |||
| self.scalar_zero = Tensor(0.0, dtype=mstype.float16) | |||
| self.scalar_neg_iou_thr = Tensor(self.neg_iou_thr, dtype=mstype.float16) | |||
| self.scalar_pos_iou_thr = Tensor(self.pos_iou_thr, dtype=mstype.float16) | |||
| self.scalar_min_pos_iou = Tensor(self.min_pos_iou, dtype=mstype.float16) | |||
| def construct(self, gt_bboxes_i, gt_labels_i, valid_mask, bboxes, gt_valids): | |||
| gt_bboxes_i = self.select(self.cast(self.tile(self.reshape(self.cast(gt_valids, mstype.int32), \ | |||
| (self.num_gts, 1)), (1, 4)), mstype.bool_), \ | |||
| gt_bboxes_i, self.check_gt_one) | |||
| bboxes = self.select(self.cast(self.tile(self.reshape(self.cast(valid_mask, mstype.int32), \ | |||
| (self.num_bboxes, 1)), (1, 4)), mstype.bool_), \ | |||
| bboxes, self.check_anchor_two) | |||
| overlaps = self.iou(bboxes, gt_bboxes_i) | |||
| max_overlaps_w_gt_index, max_overlaps_w_gt = self.max_gt(overlaps) | |||
| _, max_overlaps_w_ac = self.max_anchor(overlaps) | |||
| neg_sample_iou_mask = self.logicaland(self.greaterequal(max_overlaps_w_gt, | |||
| self.scalar_zero), | |||
| self.less(max_overlaps_w_gt, | |||
| self.scalar_neg_iou_thr)) | |||
| assigned_gt_inds2 = self.select(neg_sample_iou_mask, self.assigned_gt_zeros, self.assigned_gt_inds) | |||
| pos_sample_iou_mask = self.greaterequal(max_overlaps_w_gt, self.scalar_pos_iou_thr) | |||
| assigned_gt_inds3 = self.select(pos_sample_iou_mask, \ | |||
| max_overlaps_w_gt_index + self.assigned_gt_ones, assigned_gt_inds2) | |||
| for j in range(self.num_gts): | |||
| max_overlaps_w_ac_j = max_overlaps_w_ac[j:j+1:1] | |||
| overlaps_w_ac_j = overlaps[j:j+1:1, ::] | |||
| temp1 = self.greaterequal(max_overlaps_w_ac_j, self.scalar_min_pos_iou) | |||
| temp2 = self.squeeze(self.equal(overlaps_w_ac_j, max_overlaps_w_ac_j)) | |||
| pos_mask_j = self.logicaland(temp1, temp2) | |||
| assigned_gt_inds3 = self.select(pos_mask_j, (j+1)*self.assigned_gt_ones, assigned_gt_inds3) | |||
| assigned_gt_inds5 = self.select(valid_mask, assigned_gt_inds3, self.assigned_gt_ignores) | |||
| bboxes = self.concat((gt_bboxes_i, bboxes)) | |||
| label_inds_valid = self.select(gt_valids, self.label_inds, self.gt_ignores) | |||
| label_inds_valid = label_inds_valid * self.add_gt_as_proposals_valid | |||
| assigned_gt_inds5 = self.concat((label_inds_valid, assigned_gt_inds5)) | |||
| # Get pos index | |||
| pos_index, valid_pos_index = self.random_choice_with_mask_pos(self.greater(assigned_gt_inds5, 0)) | |||
| pos_check_valid = self.cast(self.greater(assigned_gt_inds5, 0), mstype.float16) | |||
| pos_check_valid = self.sum_inds(pos_check_valid, -1) | |||
| valid_pos_index = self.less(self.range_pos_size, pos_check_valid) | |||
| pos_index = pos_index * self.reshape(self.cast(valid_pos_index, mstype.int32), (self.num_expected_pos, 1)) | |||
| num_pos = self.sum_inds(self.cast(self.logicalnot(valid_pos_index), mstype.float16), -1) | |||
| valid_pos_index = self.cast(valid_pos_index, mstype.int32) | |||
| pos_index = self.reshape(pos_index, self.reshape_shape_pos) | |||
| valid_pos_index = self.reshape(valid_pos_index, self.reshape_shape_pos) | |||
| pos_index = pos_index * valid_pos_index | |||
| pos_assigned_gt_index = self.gatherND(assigned_gt_inds5, pos_index) - self.assigned_pos_ones | |||
| pos_assigned_gt_index = self.reshape(pos_assigned_gt_index, self.reshape_shape_pos) | |||
| pos_assigned_gt_index = pos_assigned_gt_index * valid_pos_index | |||
| pos_gt_labels = self.gatherND(gt_labels_i, pos_assigned_gt_index) | |||
| # Get neg index | |||
| neg_index, valid_neg_index = self.random_choice_with_mask_neg(self.equal(assigned_gt_inds5, 0)) | |||
| unvalid_pos_index = self.less(self.range_pos_size, num_pos) | |||
| valid_neg_index = self.logicaland(self.concat((self.check_neg_mask, unvalid_pos_index)), valid_neg_index) | |||
| neg_index = self.reshape(neg_index, self.reshape_shape_neg) | |||
| valid_neg_index = self.cast(valid_neg_index, mstype.int32) | |||
| valid_neg_index = self.reshape(valid_neg_index, self.reshape_shape_neg) | |||
| neg_index = neg_index * valid_neg_index | |||
| pos_bboxes_ = self.gatherND(bboxes, pos_index) | |||
| neg_bboxes_ = self.gatherND(bboxes, neg_index) | |||
| pos_assigned_gt_index = self.reshape(pos_assigned_gt_index, self.reshape_shape_pos) | |||
| pos_gt_bboxes_ = self.gatherND(gt_bboxes_i, pos_assigned_gt_index) | |||
| pos_bbox_targets_ = self.bounding_box_encode(pos_bboxes_, pos_gt_bboxes_) | |||
| total_bboxes = self.concat((pos_bboxes_, neg_bboxes_)) | |||
| total_deltas = self.concat((pos_bbox_targets_, self.bboxs_neg_mask)) | |||
| total_labels = self.concat((pos_gt_labels, self.labels_neg_mask)) | |||
| valid_pos_index = self.reshape(valid_pos_index, self.reshape_shape_pos) | |||
| valid_neg_index = self.reshape(valid_neg_index, self.reshape_shape_neg) | |||
| total_mask = self.concat((valid_pos_index, valid_neg_index)) | |||
| return total_bboxes, total_deltas, total_labels, total_mask | |||
+ 0
- 428
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/faster_rcnn_r50.py
View File
| @@ -1,428 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn based on ResNet50.""" | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| from mindspore.ops import operations as P | |||
| from mindspore.common.tensor import Tensor | |||
| import mindspore.common.dtype as mstype | |||
| from mindspore.ops import functional as F | |||
| from .resnet50 import ResNetFea, ResidualBlockUsing | |||
| from .bbox_assign_sample_stage2 import BboxAssignSampleForRcnn | |||
| from .fpn_neck import FeatPyramidNeck | |||
| from .proposal_generator import Proposal | |||
| from .rcnn import Rcnn | |||
| from .rpn import RPN | |||
| from .roi_align import SingleRoIExtractor | |||
| from .anchor_generator import AnchorGenerator | |||
| # pylint: disable=locally-disabled, invalid-name, missing-docstring | |||
| class Faster_Rcnn_Resnet50(nn.Cell): | |||
| """ | |||
| FasterRcnn Network. | |||
| Note: | |||
| backbone = resnet50 | |||
| Returns: | |||
| Tuple, tuple of output tensor. | |||
| rpn_loss: Scalar, Total loss of RPN subnet. | |||
| rcnn_loss: Scalar, Total loss of RCNN subnet. | |||
| rpn_cls_loss: Scalar, Classification loss of RPN subnet. | |||
| rpn_reg_loss: Scalar, Regression loss of RPN subnet. | |||
| rcnn_cls_loss: Scalar, Classification loss of RCNN subnet. | |||
| rcnn_reg_loss: Scalar, Regression loss of RCNN subnet. | |||
| Examples: | |||
| net = Faster_Rcnn_Resnet50() | |||
| """ | |||
| def __init__(self, config): | |||
| super(Faster_Rcnn_Resnet50, self).__init__() | |||
| self.train_batch_size = config.batch_size | |||
| self.num_classes = config.num_classes | |||
| self.anchor_scales = config.anchor_scales | |||
| self.anchor_ratios = config.anchor_ratios | |||
| self.anchor_strides = config.anchor_strides | |||
| self.target_means = tuple(config.rcnn_target_means) | |||
| self.target_stds = tuple(config.rcnn_target_stds) | |||
| # Anchor generator | |||
| anchor_base_sizes = None | |||
| self.anchor_base_sizes = list( | |||
| self.anchor_strides) if anchor_base_sizes is None else anchor_base_sizes | |||
| self.anchor_generators = [] | |||
| for anchor_base in self.anchor_base_sizes: | |||
| self.anchor_generators.append( | |||
| AnchorGenerator(anchor_base, self.anchor_scales, self.anchor_ratios)) | |||
| self.num_anchors = len(self.anchor_ratios) * len(self.anchor_scales) | |||
| featmap_sizes = config.feature_shapes | |||
| assert len(featmap_sizes) == len(self.anchor_generators) | |||
| self.anchor_list = self.get_anchors(featmap_sizes) | |||
| # Backbone resnet50 | |||
| self.backbone = ResNetFea(ResidualBlockUsing, | |||
| config.resnet_block, | |||
| config.resnet_in_channels, | |||
| config.resnet_out_channels, | |||
| False) | |||
| # Fpn | |||
| self.fpn_ncek = FeatPyramidNeck(config.fpn_in_channels, | |||
| config.fpn_out_channels, | |||
| config.fpn_num_outs) | |||
| # Rpn and rpn loss | |||
| self.gt_labels_stage1 = Tensor(np.ones((self.train_batch_size, config.num_gts)).astype(np.uint8)) | |||
| self.rpn_with_loss = RPN(config, | |||
| self.train_batch_size, | |||
| config.rpn_in_channels, | |||
| config.rpn_feat_channels, | |||
| config.num_anchors, | |||
| config.rpn_cls_out_channels) | |||
| # Proposal | |||
| self.proposal_generator = Proposal(config, | |||
| self.train_batch_size, | |||
| config.activate_num_classes, | |||
| config.use_sigmoid_cls) | |||
| self.proposal_generator.set_train_local(config, True) | |||
| self.proposal_generator_test = Proposal(config, | |||
| config.test_batch_size, | |||
| config.activate_num_classes, | |||
| config.use_sigmoid_cls) | |||
| self.proposal_generator_test.set_train_local(config, False) | |||
| # Assign and sampler stage two | |||
| self.bbox_assigner_sampler_for_rcnn = BboxAssignSampleForRcnn(config, self.train_batch_size, | |||
| config.num_bboxes_stage2, True) | |||
| self.decode = P.BoundingBoxDecode(max_shape=(768, 1280), means=self.target_means, \ | |||
| stds=self.target_stds) | |||
| # Roi | |||
| self.roi_align = SingleRoIExtractor(config, | |||
| config.roi_layer, | |||
| config.roi_align_out_channels, | |||
| config.roi_align_featmap_strides, | |||
| self.train_batch_size, | |||
| config.roi_align_finest_scale) | |||
| self.roi_align.set_train_local(config, True) | |||
| self.roi_align_test = SingleRoIExtractor(config, | |||
| config.roi_layer, | |||
| config.roi_align_out_channels, | |||
| config.roi_align_featmap_strides, | |||
| 1, | |||
| config.roi_align_finest_scale) | |||
| self.roi_align_test.set_train_local(config, False) | |||
| # Rcnn | |||
| self.rcnn = Rcnn(config, config.rcnn_in_channels * config.roi_layer['out_size'] * config.roi_layer['out_size'], | |||
| self.train_batch_size, self.num_classes) | |||
| # Op declare | |||
| self.squeeze = P.Squeeze() | |||
| self.cast = P.Cast() | |||
| self.concat = P.Concat(axis=0) | |||
| self.concat_1 = P.Concat(axis=1) | |||
| self.concat_2 = P.Concat(axis=2) | |||
| self.reshape = P.Reshape() | |||
| self.select = P.Select() | |||
| self.greater = P.Greater() | |||
| self.transpose = P.Transpose() | |||
| # Test mode | |||
| self.test_batch_size = config.test_batch_size | |||
| self.split = P.Split(axis=0, output_num=self.test_batch_size) | |||
| self.split_shape = P.Split(axis=0, output_num=4) | |||
| self.split_scores = P.Split(axis=1, output_num=self.num_classes) | |||
| self.split_cls = P.Split(axis=0, output_num=self.num_classes-1) | |||
| self.tile = P.Tile() | |||
| self.gather = P.GatherNd() | |||
| self.rpn_max_num = config.rpn_max_num | |||
| self.zeros_for_nms = Tensor(np.zeros((self.rpn_max_num, 3)).astype(np.float16)) | |||
| self.ones_mask = np.ones((self.rpn_max_num, 1)).astype(np.bool) | |||
| self.zeros_mask = np.zeros((self.rpn_max_num, 1)).astype(np.bool) | |||
| self.bbox_mask = Tensor(np.concatenate((self.ones_mask, self.zeros_mask, | |||
| self.ones_mask, self.zeros_mask), axis=1)) | |||
| self.nms_pad_mask = Tensor(np.concatenate((self.ones_mask, self.ones_mask, | |||
| self.ones_mask, self.ones_mask, self.zeros_mask), axis=1)) | |||
| self.test_score_thresh = Tensor(np.ones((self.rpn_max_num, 1)).astype(np.float16) * config.test_score_thr) | |||
| self.test_score_zeros = Tensor(np.ones((self.rpn_max_num, 1)).astype(np.float16) * 0) | |||
| self.test_box_zeros = Tensor(np.ones((self.rpn_max_num, 4)).astype(np.float16) * -1) | |||
| self.test_iou_thr = Tensor(np.ones((self.rpn_max_num, 1)).astype(np.float16) * config.test_iou_thr) | |||
| self.test_max_per_img = config.test_max_per_img | |||
| self.nms_test = P.NMSWithMask(config.test_iou_thr) | |||
| self.softmax = P.Softmax(axis=1) | |||
| self.logicand = P.LogicalAnd() | |||
| self.oneslike = P.OnesLike() | |||
| self.test_topk = P.TopK(sorted=True) | |||
| self.test_num_proposal = self.test_batch_size * self.rpn_max_num | |||
| # Improve speed | |||
| self.concat_start = min(self.num_classes - 2, 55) | |||
| self.concat_end = (self.num_classes - 1) | |||
| # Init tensor | |||
| roi_align_index = [np.array(np.ones((config.num_expected_pos_stage2 + config.num_expected_neg_stage2, 1)) * i, | |||
| dtype=np.float16) for i in range(self.train_batch_size)] | |||
| roi_align_index_test = [np.array(np.ones((config.rpn_max_num, 1)) * i, dtype=np.float16) \ | |||
| for i in range(self.test_batch_size)] | |||
| self.roi_align_index_tensor = Tensor(np.concatenate(roi_align_index)) | |||
| self.roi_align_index_test_tensor = Tensor(np.concatenate(roi_align_index_test)) | |||
| def construct(self, img_data, img_metas, gt_bboxes, gt_labels, gt_valids): | |||
| x = self.backbone(img_data) | |||
| x = self.fpn_ncek(x) | |||
| rpn_loss, cls_score, bbox_pred, rpn_cls_loss, rpn_reg_loss, _ = self.rpn_with_loss(x, | |||
| img_metas, | |||
| self.anchor_list, | |||
| gt_bboxes, | |||
| self.gt_labels_stage1, | |||
| gt_valids) | |||
| if self.training: | |||
| proposal, proposal_mask = self.proposal_generator(cls_score, bbox_pred, self.anchor_list) | |||
| else: | |||
| proposal, proposal_mask = self.proposal_generator_test(cls_score, bbox_pred, self.anchor_list) | |||
| gt_labels = self.cast(gt_labels, mstype.int32) | |||
| gt_valids = self.cast(gt_valids, mstype.int32) | |||
| bboxes_tuple = () | |||
| deltas_tuple = () | |||
| labels_tuple = () | |||
| mask_tuple = () | |||
| if self.training: | |||
| for i in range(self.train_batch_size): | |||
| gt_bboxes_i = self.squeeze(gt_bboxes[i:i + 1:1, ::]) | |||
| gt_labels_i = self.squeeze(gt_labels[i:i + 1:1, ::]) | |||
| gt_labels_i = self.cast(gt_labels_i, mstype.uint8) | |||
| gt_valids_i = self.squeeze(gt_valids[i:i + 1:1, ::]) | |||
| gt_valids_i = self.cast(gt_valids_i, mstype.bool_) | |||
| bboxes, deltas, labels, mask = self.bbox_assigner_sampler_for_rcnn(gt_bboxes_i, | |||
| gt_labels_i, | |||
| proposal_mask[i], | |||
| proposal[i][::, 0:4:1], | |||
| gt_valids_i) | |||
| bboxes_tuple += (bboxes,) | |||
| deltas_tuple += (deltas,) | |||
| labels_tuple += (labels,) | |||
| mask_tuple += (mask,) | |||
| bbox_targets = self.concat(deltas_tuple) | |||
| rcnn_labels = self.concat(labels_tuple) | |||
| bbox_targets = F.stop_gradient(bbox_targets) | |||
| rcnn_labels = F.stop_gradient(rcnn_labels) | |||
| rcnn_labels = self.cast(rcnn_labels, mstype.int32) | |||
| else: | |||
| mask_tuple += proposal_mask | |||
| bbox_targets = proposal_mask | |||
| rcnn_labels = proposal_mask | |||
| for p_i in proposal: | |||
| bboxes_tuple += (p_i[::, 0:4:1],) | |||
| if self.training: | |||
| if self.train_batch_size > 1: | |||
| bboxes_all = self.concat(bboxes_tuple) | |||
| else: | |||
| bboxes_all = bboxes_tuple[0] | |||
| rois = self.concat_1((self.roi_align_index_tensor, bboxes_all)) | |||
| else: | |||
| if self.test_batch_size > 1: | |||
| bboxes_all = self.concat(bboxes_tuple) | |||
| else: | |||
| bboxes_all = bboxes_tuple[0] | |||
| rois = self.concat_1((self.roi_align_index_test_tensor, bboxes_all)) | |||
| rois = self.cast(rois, mstype.float32) | |||
| rois = F.stop_gradient(rois) | |||
| if self.training: | |||
| roi_feats = self.roi_align(rois, | |||
| self.cast(x[0], mstype.float32), | |||
| self.cast(x[1], mstype.float32), | |||
| self.cast(x[2], mstype.float32), | |||
| self.cast(x[3], mstype.float32)) | |||
| else: | |||
| roi_feats = self.roi_align_test(rois, | |||
| self.cast(x[0], mstype.float32), | |||
| self.cast(x[1], mstype.float32), | |||
| self.cast(x[2], mstype.float32), | |||
| self.cast(x[3], mstype.float32)) | |||
| roi_feats = self.cast(roi_feats, mstype.float16) | |||
| rcnn_masks = self.concat(mask_tuple) | |||
| rcnn_masks = F.stop_gradient(rcnn_masks) | |||
| rcnn_mask_squeeze = self.squeeze(self.cast(rcnn_masks, mstype.bool_)) | |||
| rcnn_loss, rcnn_cls_loss, rcnn_reg_loss, _ = self.rcnn(roi_feats, | |||
| bbox_targets, | |||
| rcnn_labels, | |||
| rcnn_mask_squeeze) | |||
| output = () | |||
| if self.training: | |||
| output += (rpn_loss, rcnn_loss, rpn_cls_loss, rpn_reg_loss, rcnn_cls_loss, rcnn_reg_loss) | |||
| else: | |||
| output = self.get_det_bboxes(rcnn_cls_loss, rcnn_reg_loss, rcnn_masks, bboxes_all, img_metas) | |||
| return output | |||
| def get_det_bboxes(self, cls_logits, reg_logits, mask_logits, rois, img_metas): | |||
| """Get the actual detection box.""" | |||
| scores = self.softmax(cls_logits) | |||
| boxes_all = () | |||
| for i in range(self.num_classes): | |||
| k = i * 4 | |||
| reg_logits_i = self.squeeze(reg_logits[::, k:k+4:1]) | |||
| out_boxes_i = self.decode(rois, reg_logits_i) | |||
| boxes_all += (out_boxes_i,) | |||
| img_metas_all = self.split(img_metas) | |||
| scores_all = self.split(scores) | |||
| mask_all = self.split(self.cast(mask_logits, mstype.int32)) | |||
| boxes_all_with_batchsize = () | |||
| for i in range(self.test_batch_size): | |||
| scale = self.split_shape(self.squeeze(img_metas_all[i])) | |||
| scale_h = scale[2] | |||
| scale_w = scale[3] | |||
| boxes_tuple = () | |||
| for j in range(self.num_classes): | |||
| boxes_tmp = self.split(boxes_all[j]) | |||
| out_boxes_h = boxes_tmp[i] / scale_h | |||
| out_boxes_w = boxes_tmp[i] / scale_w | |||
| boxes_tuple += (self.select(self.bbox_mask, out_boxes_w, out_boxes_h),) | |||
| boxes_all_with_batchsize += (boxes_tuple,) | |||
| output = self.multiclass_nms(boxes_all_with_batchsize, scores_all, mask_all) | |||
| return output | |||
| def multiclass_nms(self, boxes_all, scores_all, mask_all): | |||
| """Multiscale postprocessing.""" | |||
| all_bboxes = () | |||
| all_labels = () | |||
| all_masks = () | |||
| for i in range(self.test_batch_size): | |||
| bboxes = boxes_all[i] | |||
| scores = scores_all[i] | |||
| masks = self.cast(mask_all[i], mstype.bool_) | |||
| res_boxes_tuple = () | |||
| res_labels_tuple = () | |||
| res_masks_tuple = () | |||
| for j in range(self.num_classes - 1): | |||
| k = j + 1 | |||
| _cls_scores = scores[::, k:k + 1:1] | |||
| _bboxes = self.squeeze(bboxes[k]) | |||
| _mask_o = self.reshape(masks, (self.rpn_max_num, 1)) | |||
| cls_mask = self.greater(_cls_scores, self.test_score_thresh) | |||
| _mask = self.logicand(_mask_o, cls_mask) | |||
| _reg_mask = self.cast(self.tile(self.cast(_mask, mstype.int32), (1, 4)), mstype.bool_) | |||
| _bboxes = self.select(_reg_mask, _bboxes, self.test_box_zeros) | |||
| _cls_scores = self.select(_mask, _cls_scores, self.test_score_zeros) | |||
| __cls_scores = self.squeeze(_cls_scores) | |||
| scores_sorted, topk_inds = self.test_topk(__cls_scores, self.rpn_max_num) | |||
| topk_inds = self.reshape(topk_inds, (self.rpn_max_num, 1)) | |||
| scores_sorted = self.reshape(scores_sorted, (self.rpn_max_num, 1)) | |||
| _bboxes_sorted = self.gather(_bboxes, topk_inds) | |||
| _mask_sorted = self.gather(_mask, topk_inds) | |||
| scores_sorted = self.tile(scores_sorted, (1, 4)) | |||
| cls_dets = self.concat_1((_bboxes_sorted, scores_sorted)) | |||
| cls_dets = P.Slice()(cls_dets, (0, 0), (self.rpn_max_num, 5)) | |||
| cls_dets, _index, _mask_nms = self.nms_test(cls_dets) | |||
| _index = self.reshape(_index, (self.rpn_max_num, 1)) | |||
| _mask_nms = self.reshape(_mask_nms, (self.rpn_max_num, 1)) | |||
| _mask_n = self.gather(_mask_sorted, _index) | |||
| _mask_n = self.logicand(_mask_n, _mask_nms) | |||
| cls_labels = self.oneslike(_index) * j | |||
| res_boxes_tuple += (cls_dets,) | |||
| res_labels_tuple += (cls_labels,) | |||
| res_masks_tuple += (_mask_n,) | |||
| res_boxes_start = self.concat(res_boxes_tuple[:self.concat_start]) | |||
| res_labels_start = self.concat(res_labels_tuple[:self.concat_start]) | |||
| res_masks_start = self.concat(res_masks_tuple[:self.concat_start]) | |||
| res_boxes_end = self.concat(res_boxes_tuple[self.concat_start:self.concat_end]) | |||
| res_labels_end = self.concat(res_labels_tuple[self.concat_start:self.concat_end]) | |||
| res_masks_end = self.concat(res_masks_tuple[self.concat_start:self.concat_end]) | |||
| res_boxes = self.concat((res_boxes_start, res_boxes_end)) | |||
| res_labels = self.concat((res_labels_start, res_labels_end)) | |||
| res_masks = self.concat((res_masks_start, res_masks_end)) | |||
| reshape_size = (self.num_classes - 1) * self.rpn_max_num | |||
| res_boxes = self.reshape(res_boxes, (1, reshape_size, 5)) | |||
| res_labels = self.reshape(res_labels, (1, reshape_size, 1)) | |||
| res_masks = self.reshape(res_masks, (1, reshape_size, 1)) | |||
| all_bboxes += (res_boxes,) | |||
| all_labels += (res_labels,) | |||
| all_masks += (res_masks,) | |||
| all_bboxes = self.concat(all_bboxes) | |||
| all_labels = self.concat(all_labels) | |||
| all_masks = self.concat(all_masks) | |||
| return all_bboxes, all_labels, all_masks | |||
| def get_anchors(self, featmap_sizes): | |||
| """Get anchors according to feature map sizes. | |||
| Args: | |||
| featmap_sizes (list[tuple]): Multi-level feature map sizes. | |||
| img_metas (list[dict]): Image meta info. | |||
| Returns: | |||
| tuple: anchors of each image, valid flags of each image | |||
| """ | |||
| num_levels = len(featmap_sizes) | |||
| # since feature map sizes of all images are the same, we only compute | |||
| # anchors for one time | |||
| multi_level_anchors = () | |||
| for i in range(num_levels): | |||
| anchors = self.anchor_generators[i].grid_anchors( | |||
| featmap_sizes[i], self.anchor_strides[i]) | |||
| multi_level_anchors += (Tensor(anchors.astype(np.float16)),) | |||
| return multi_level_anchors | |||
+ 0
- 114
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/fpn_neck.py
View File
| @@ -1,114 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn feature pyramid network.""" | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| from mindspore import context | |||
| from mindspore.ops import operations as P | |||
| from mindspore.common.tensor import Tensor | |||
| from mindspore.common import dtype as mstype | |||
| from mindspore.common.initializer import initializer | |||
| # pylint: disable=locally-disabled, missing-docstring | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| def bias_init_zeros(shape): | |||
| """Bias init method.""" | |||
| return Tensor(np.array(np.zeros(shape).astype(np.float32)).astype(np.float16)) | |||
| def _conv(in_channels, out_channels, kernel_size=3, stride=1, padding=0, pad_mode='pad'): | |||
| """Conv2D wrapper.""" | |||
| shape = (out_channels, in_channels, kernel_size, kernel_size) | |||
| weights = initializer("XavierUniform", shape=shape, dtype=mstype.float16).to_tensor() | |||
| shape_bias = (out_channels,) | |||
| biass = bias_init_zeros(shape_bias) | |||
| return nn.Conv2d(in_channels, out_channels, | |||
| kernel_size=kernel_size, stride=stride, padding=padding, | |||
| pad_mode=pad_mode, weight_init=weights, has_bias=True, bias_init=biass) | |||
| class FeatPyramidNeck(nn.Cell): | |||
| """ | |||
| Feature pyramid network cell, usually uses as network neck. | |||
| Applies the convolution on multiple, input feature maps | |||
| and output feature map with same channel size. if required num of | |||
| output larger then num of inputs, add extra maxpooling for further | |||
| downsampling; | |||
| Args: | |||
| in_channels (tuple) - Channel size of input feature maps. | |||
| out_channels (int) - Channel size output. | |||
| num_outs (int) - Num of output features. | |||
| Returns: | |||
| Tuple, with tensors of same channel size. | |||
| Examples: | |||
| neck = FeatPyramidNeck([100,200,300], 50, 4) | |||
| input_data = (normal(0,0.1,(1,c,1280//(4*2**i), 768//(4*2**i)), | |||
| dtype=np.float32) \ | |||
| for i, c in enumerate(config.fpn_in_channels)) | |||
| x = neck(input_data) | |||
| """ | |||
| def __init__(self, | |||
| in_channels, | |||
| out_channels, | |||
| num_outs): | |||
| super(FeatPyramidNeck, self).__init__() | |||
| self.num_outs = num_outs | |||
| self.in_channels = in_channels | |||
| self.fpn_layer = len(self.in_channels) | |||
| assert not self.num_outs < len(in_channels) | |||
| self.lateral_convs_list_ = [] | |||
| self.fpn_convs_ = [] | |||
| for _, channel in enumerate(in_channels): | |||
| l_conv = _conv(channel, out_channels, kernel_size=1, stride=1, padding=0, pad_mode='valid') | |||
| fpn_conv = _conv(out_channels, out_channels, kernel_size=3, stride=1, padding=0, pad_mode='same') | |||
| self.lateral_convs_list_.append(l_conv) | |||
| self.fpn_convs_.append(fpn_conv) | |||
| self.lateral_convs_list = nn.layer.CellList(self.lateral_convs_list_) | |||
| self.fpn_convs_list = nn.layer.CellList(self.fpn_convs_) | |||
| self.interpolate1 = P.ResizeNearestNeighbor((48, 80)) | |||
| self.interpolate2 = P.ResizeNearestNeighbor((96, 160)) | |||
| self.interpolate3 = P.ResizeNearestNeighbor((192, 320)) | |||
| self.maxpool = P.MaxPool(kernel_size=1, strides=2, pad_mode="same") | |||
| def construct(self, inputs): | |||
| x = () | |||
| for i in range(self.fpn_layer): | |||
| x += (self.lateral_convs_list[i](inputs[i]),) | |||
| y = (x[3],) | |||
| y = y + (x[2] + self.interpolate1(y[self.fpn_layer - 4]),) | |||
| y = y + (x[1] + self.interpolate2(y[self.fpn_layer - 3]),) | |||
| y = y + (x[0] + self.interpolate3(y[self.fpn_layer - 2]),) | |||
| z = () | |||
| for i in range(self.fpn_layer - 1, -1, -1): | |||
| z = z + (y[i],) | |||
| outs = () | |||
| for i in range(self.fpn_layer): | |||
| outs = outs + (self.fpn_convs_list[i](z[i]),) | |||
| for i in range(self.num_outs - self.fpn_layer): | |||
| outs = outs + (self.maxpool(outs[3]),) | |||
| return outs | |||
+ 0
- 201
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/proposal_generator.py
View File
| @@ -1,201 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn proposal generator.""" | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| import mindspore.common.dtype as mstype | |||
| from mindspore.ops import operations as P | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| # pylint: disable=locally-disabled, invalid-name, missing-docstring | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| class Proposal(nn.Cell): | |||
| """ | |||
| Proposal subnet. | |||
| Args: | |||
| config (dict): Config. | |||
| batch_size (int): Batchsize. | |||
| num_classes (int) - Class number. | |||
| use_sigmoid_cls (bool) - Select sigmoid or softmax function. | |||
| target_means (tuple) - Means for encode function. Default: (.0, .0, .0, .0). | |||
| target_stds (tuple) - Stds for encode function. Default: (1.0, 1.0, 1.0, 1.0). | |||
| Returns: | |||
| Tuple, tuple of output tensor,(proposal, mask). | |||
| Examples: | |||
| Proposal(config = config, batch_size = 1, num_classes = 81, use_sigmoid_cls = True, \ | |||
| target_means=(.0, .0, .0, .0), target_stds=(1.0, 1.0, 1.0, 1.0)) | |||
| """ | |||
| def __init__(self, | |||
| config, | |||
| batch_size, | |||
| num_classes, | |||
| use_sigmoid_cls, | |||
| target_means=(.0, .0, .0, .0), | |||
| target_stds=(1.0, 1.0, 1.0, 1.0) | |||
| ): | |||
| super(Proposal, self).__init__() | |||
| cfg = config | |||
| self.batch_size = batch_size | |||
| self.num_classes = num_classes | |||
| self.target_means = target_means | |||
| self.target_stds = target_stds | |||
| self.use_sigmoid_cls = use_sigmoid_cls | |||
| if self.use_sigmoid_cls: | |||
| self.cls_out_channels = num_classes - 1 | |||
| self.activation = P.Sigmoid() | |||
| self.reshape_shape = (-1, 1) | |||
| else: | |||
| self.cls_out_channels = num_classes | |||
| self.activation = P.Softmax(axis=1) | |||
| self.reshape_shape = (-1, 2) | |||
| if self.cls_out_channels <= 0: | |||
| raise ValueError('num_classes={} is too small'.format(num_classes)) | |||
| self.num_pre = cfg.rpn_proposal_nms_pre | |||
| self.min_box_size = cfg.rpn_proposal_min_bbox_size | |||
| self.nms_thr = cfg.rpn_proposal_nms_thr | |||
| self.nms_post = cfg.rpn_proposal_nms_post | |||
| self.nms_across_levels = cfg.rpn_proposal_nms_across_levels | |||
| self.max_num = cfg.rpn_proposal_max_num | |||
| self.num_levels = cfg.fpn_num_outs | |||
| # Op Define | |||
| self.squeeze = P.Squeeze() | |||
| self.reshape = P.Reshape() | |||
| self.cast = P.Cast() | |||
| self.feature_shapes = cfg.feature_shapes | |||
| self.transpose_shape = (1, 2, 0) | |||
| self.decode = P.BoundingBoxDecode(max_shape=(cfg.img_height, cfg.img_width), \ | |||
| means=self.target_means, \ | |||
| stds=self.target_stds) | |||
| self.nms = P.NMSWithMask(self.nms_thr) | |||
| self.concat_axis0 = P.Concat(axis=0) | |||
| self.concat_axis1 = P.Concat(axis=1) | |||
| self.split = P.Split(axis=1, output_num=5) | |||
| self.min = P.Minimum() | |||
| self.gatherND = P.GatherNd() | |||
| self.slice = P.Slice() | |||
| self.select = P.Select() | |||
| self.greater = P.Greater() | |||
| self.transpose = P.Transpose() | |||
| self.tile = P.Tile() | |||
| self.set_train_local(config, training=True) | |||
| self.multi_10 = Tensor(10.0, mstype.float16) | |||
| def set_train_local(self, config, training=True): | |||
| """Set training flag.""" | |||
| self.training_local = training | |||
| cfg = config | |||
| self.topK_stage1 = () | |||
| self.topK_shape = () | |||
| total_max_topk_input = 0 | |||
| if not self.training_local: | |||
| self.num_pre = cfg.rpn_nms_pre | |||
| self.min_box_size = cfg.rpn_min_bbox_min_size | |||
| self.nms_thr = cfg.rpn_nms_thr | |||
| self.nms_post = cfg.rpn_nms_post | |||
| self.nms_across_levels = cfg.rpn_nms_across_levels | |||
| self.max_num = cfg.rpn_max_num | |||
| for shp in self.feature_shapes: | |||
| k_num = min(self.num_pre, (shp[0] * shp[1] * 3)) | |||
| total_max_topk_input += k_num | |||
| self.topK_stage1 += (k_num,) | |||
| self.topK_shape += ((k_num, 1),) | |||
| self.topKv2 = P.TopK(sorted=True) | |||
| self.topK_shape_stage2 = (self.max_num, 1) | |||
| self.min_float_num = -65536.0 | |||
| self.topK_mask = Tensor(self.min_float_num * np.ones(total_max_topk_input, np.float16)) | |||
| def construct(self, rpn_cls_score_total, rpn_bbox_pred_total, anchor_list): | |||
| proposals_tuple = () | |||
| masks_tuple = () | |||
| for img_id in range(self.batch_size): | |||
| cls_score_list = () | |||
| bbox_pred_list = () | |||
| for i in range(self.num_levels): | |||
| rpn_cls_score_i = self.squeeze(rpn_cls_score_total[i][img_id:img_id+1:1, ::, ::, ::]) | |||
| rpn_bbox_pred_i = self.squeeze(rpn_bbox_pred_total[i][img_id:img_id+1:1, ::, ::, ::]) | |||
| cls_score_list = cls_score_list + (rpn_cls_score_i,) | |||
| bbox_pred_list = bbox_pred_list + (rpn_bbox_pred_i,) | |||
| proposals, masks = self.get_bboxes_single(cls_score_list, bbox_pred_list, anchor_list) | |||
| proposals_tuple += (proposals,) | |||
| masks_tuple += (masks,) | |||
| return proposals_tuple, masks_tuple | |||
| def get_bboxes_single(self, cls_scores, bbox_preds, mlvl_anchors): | |||
| """Get proposal boundingbox.""" | |||
| mlvl_proposals = () | |||
| mlvl_mask = () | |||
| for idx in range(self.num_levels): | |||
| rpn_cls_score = self.transpose(cls_scores[idx], self.transpose_shape) | |||
| rpn_bbox_pred = self.transpose(bbox_preds[idx], self.transpose_shape) | |||
| anchors = mlvl_anchors[idx] | |||
| rpn_cls_score = self.reshape(rpn_cls_score, self.reshape_shape) | |||
| rpn_cls_score = self.activation(rpn_cls_score) | |||
| rpn_cls_score_process = self.cast(self.squeeze(rpn_cls_score[::, 0::]), mstype.float16) | |||
| rpn_bbox_pred_process = self.cast(self.reshape(rpn_bbox_pred, (-1, 4)), mstype.float16) | |||
| scores_sorted, topk_inds = self.topKv2(rpn_cls_score_process, self.topK_stage1[idx]) | |||
| topk_inds = self.reshape(topk_inds, self.topK_shape[idx]) | |||
| bboxes_sorted = self.gatherND(rpn_bbox_pred_process, topk_inds) | |||
| anchors_sorted = self.cast(self.gatherND(anchors, topk_inds), mstype.float16) | |||
| proposals_decode = self.decode(anchors_sorted, bboxes_sorted) | |||
| proposals_decode = self.concat_axis1((proposals_decode, self.reshape(scores_sorted, self.topK_shape[idx]))) | |||
| proposals, _, mask_valid = self.nms(proposals_decode) | |||
| mlvl_proposals = mlvl_proposals + (proposals,) | |||
| mlvl_mask = mlvl_mask + (mask_valid,) | |||
| proposals = self.concat_axis0(mlvl_proposals) | |||
| masks = self.concat_axis0(mlvl_mask) | |||
| _, _, _, _, scores = self.split(proposals) | |||
| scores = self.squeeze(scores) | |||
| topk_mask = self.cast(self.topK_mask, mstype.float16) | |||
| scores_using = self.select(masks, scores, topk_mask) | |||
| _, topk_inds = self.topKv2(scores_using, self.max_num) | |||
| topk_inds = self.reshape(topk_inds, self.topK_shape_stage2) | |||
| proposals = self.gatherND(proposals, topk_inds) | |||
| masks = self.gatherND(masks, topk_inds) | |||
| return proposals, masks | |||
+ 0
- 173
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/rcnn.py
View File
| @@ -1,173 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn Rcnn network.""" | |||
| import numpy as np | |||
| import mindspore.common.dtype as mstype | |||
| import mindspore.nn as nn | |||
| from mindspore.ops import operations as P | |||
| from mindspore.common.tensor import Tensor | |||
| from mindspore.common.initializer import initializer | |||
| from mindspore.common.parameter import Parameter | |||
| # pylint: disable=locally-disabled, missing-docstring | |||
| class DenseNoTranpose(nn.Cell): | |||
| """Dense method""" | |||
| def __init__(self, input_channels, output_channels, weight_init): | |||
| super(DenseNoTranpose, self).__init__() | |||
| self.weight = Parameter(initializer(weight_init, [input_channels, output_channels], mstype.float16), | |||
| name="weight") | |||
| self.bias = Parameter(initializer("zeros", [output_channels], mstype.float16).to_tensor(), name="bias") | |||
| self.matmul = P.MatMul(transpose_b=False) | |||
| self.bias_add = P.BiasAdd() | |||
| def construct(self, x): | |||
| output = self.bias_add(self.matmul(x, self.weight), self.bias) | |||
| return output | |||
| class Rcnn(nn.Cell): | |||
| """ | |||
| Rcnn subnet. | |||
| Args: | |||
| config (dict) - Config. | |||
| representation_size (int) - Channels of shared dense. | |||
| batch_size (int) - Batchsize. | |||
| num_classes (int) - Class number. | |||
| target_means (list) - Means for encode function. Default: (.0, .0, .0, .0]). | |||
| target_stds (list) - Stds for encode function. Default: (0.1, 0.1, 0.2, 0.2). | |||
| Returns: | |||
| Tuple, tuple of output tensor. | |||
| Examples: | |||
| Rcnn(config=config, representation_size = 1024, batch_size=2, num_classes = 81, \ | |||
| target_means=(0., 0., 0., 0.), target_stds=(0.1, 0.1, 0.2, 0.2)) | |||
| """ | |||
| def __init__(self, | |||
| config, | |||
| representation_size, | |||
| batch_size, | |||
| num_classes, | |||
| target_means=(0., 0., 0., 0.), | |||
| target_stds=(0.1, 0.1, 0.2, 0.2) | |||
| ): | |||
| super(Rcnn, self).__init__() | |||
| cfg = config | |||
| self.rcnn_loss_cls_weight = Tensor(np.array(cfg.rcnn_loss_cls_weight).astype(np.float16)) | |||
| self.rcnn_loss_reg_weight = Tensor(np.array(cfg.rcnn_loss_reg_weight).astype(np.float16)) | |||
| self.rcnn_fc_out_channels = cfg.rcnn_fc_out_channels | |||
| self.target_means = target_means | |||
| self.target_stds = target_stds | |||
| self.num_classes = num_classes | |||
| self.in_channels = cfg.rcnn_in_channels | |||
| self.train_batch_size = batch_size | |||
| self.test_batch_size = cfg.test_batch_size | |||
| shape_0 = (self.rcnn_fc_out_channels, representation_size) | |||
| weights_0 = initializer("XavierUniform", shape=shape_0[::-1], dtype=mstype.float16).to_tensor() | |||
| shape_1 = (self.rcnn_fc_out_channels, self.rcnn_fc_out_channels) | |||
| weights_1 = initializer("XavierUniform", shape=shape_1[::-1], dtype=mstype.float16).to_tensor() | |||
| self.shared_fc_0 = DenseNoTranpose(representation_size, self.rcnn_fc_out_channels, weights_0) | |||
| self.shared_fc_1 = DenseNoTranpose(self.rcnn_fc_out_channels, self.rcnn_fc_out_channels, weights_1) | |||
| cls_weight = initializer('Normal', shape=[num_classes, self.rcnn_fc_out_channels][::-1], | |||
| dtype=mstype.float16).to_tensor() | |||
| reg_weight = initializer('Normal', shape=[num_classes * 4, self.rcnn_fc_out_channels][::-1], | |||
| dtype=mstype.float16).to_tensor() | |||
| self.cls_scores = DenseNoTranpose(self.rcnn_fc_out_channels, num_classes, cls_weight) | |||
| self.reg_scores = DenseNoTranpose(self.rcnn_fc_out_channels, num_classes * 4, reg_weight) | |||
| self.flatten = P.Flatten() | |||
| self.relu = P.ReLU() | |||
| self.logicaland = P.LogicalAnd() | |||
| self.loss_cls = P.SoftmaxCrossEntropyWithLogits() | |||
| self.loss_bbox = P.SmoothL1Loss(beta=1.0) | |||
| self.reshape = P.Reshape() | |||
| self.onehot = P.OneHot() | |||
| self.greater = P.Greater() | |||
| self.cast = P.Cast() | |||
| self.sum_loss = P.ReduceSum() | |||
| self.tile = P.Tile() | |||
| self.expandims = P.ExpandDims() | |||
| self.gather = P.GatherNd() | |||
| self.argmax = P.ArgMaxWithValue(axis=1) | |||
| self.on_value = Tensor(1.0, mstype.float32) | |||
| self.off_value = Tensor(0.0, mstype.float32) | |||
| self.value = Tensor(1.0, mstype.float16) | |||
| self.num_bboxes = (cfg.num_expected_pos_stage2 + cfg.num_expected_neg_stage2) * batch_size | |||
| rmv_first = np.ones((self.num_bboxes, self.num_classes)) | |||
| rmv_first[:, 0] = np.zeros((self.num_bboxes,)) | |||
| self.rmv_first_tensor = Tensor(rmv_first.astype(np.float16)) | |||
| self.num_bboxes_test = cfg.rpn_max_num * cfg.test_batch_size | |||
| range_max = np.arange(self.num_bboxes_test).astype(np.int32) | |||
| self.range_max = Tensor(range_max) | |||
| def construct(self, featuremap, bbox_targets, labels, mask): | |||
| x = self.flatten(featuremap) | |||
| x = self.relu(self.shared_fc_0(x)) | |||
| x = self.relu(self.shared_fc_1(x)) | |||
| x_cls = self.cls_scores(x) | |||
| x_reg = self.reg_scores(x) | |||
| if self.training: | |||
| bbox_weights = self.cast(self.logicaland(self.greater(labels, 0), mask), mstype.int32) * labels | |||
| labels = self.cast(self.onehot(labels, self.num_classes, self.on_value, self.off_value), mstype.float16) | |||
| bbox_targets = self.tile(self.expandims(bbox_targets, 1), (1, self.num_classes, 1)) | |||
| loss, loss_cls, loss_reg, loss_print = self.loss(x_cls, x_reg, bbox_targets, bbox_weights, labels, mask) | |||
| out = (loss, loss_cls, loss_reg, loss_print) | |||
| else: | |||
| out = (x_cls, (x_cls / self.value), x_reg, x_cls) | |||
| return out | |||
| def loss(self, cls_score, bbox_pred, bbox_targets, bbox_weights, labels, weights): | |||
| """Loss method.""" | |||
| loss_print = () | |||
| loss_cls, _ = self.loss_cls(cls_score, labels) | |||
| weights = self.cast(weights, mstype.float16) | |||
| loss_cls = loss_cls * weights | |||
| loss_cls = self.sum_loss(loss_cls, (0,)) / self.sum_loss(weights, (0,)) | |||
| bbox_weights = self.cast(self.onehot(bbox_weights, self.num_classes, self.on_value, self.off_value), | |||
| mstype.float16) | |||
| bbox_weights = bbox_weights * self.rmv_first_tensor | |||
| pos_bbox_pred = self.reshape(bbox_pred, (self.num_bboxes, -1, 4)) | |||
| loss_reg = self.loss_bbox(pos_bbox_pred, bbox_targets) | |||
| loss_reg = self.sum_loss(loss_reg, (2,)) | |||
| loss_reg = loss_reg * bbox_weights | |||
| loss_reg = loss_reg / self.sum_loss(weights, (0,)) | |||
| loss_reg = self.sum_loss(loss_reg, (0, 1)) | |||
| loss = self.rcnn_loss_cls_weight * loss_cls + self.rcnn_loss_reg_weight * loss_reg | |||
| loss_print += (loss_cls, loss_reg) | |||
| return loss, loss_cls, loss_reg, loss_print | |||
+ 0
- 250
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/resnet50.py
View File
| @@ -1,250 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Resnet50 backbone.""" | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| from mindspore.ops import operations as P | |||
| from mindspore.common.tensor import Tensor | |||
| from mindspore.ops import functional as F | |||
| from mindspore import context | |||
| # pylint: disable=locally-disabled, invalid-name, missing-docstring | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| def weight_init_ones(shape): | |||
| """Weight init.""" | |||
| return Tensor(np.array(np.ones(shape).astype(np.float32) * 0.01).astype(np.float16)) | |||
| def _conv(in_channels, out_channels, kernel_size=3, stride=1, padding=0, pad_mode='pad'): | |||
| """Conv2D wrapper.""" | |||
| shape = (out_channels, in_channels, kernel_size, kernel_size) | |||
| weights = weight_init_ones(shape) | |||
| return nn.Conv2d(in_channels, out_channels, | |||
| kernel_size=kernel_size, stride=stride, padding=padding, | |||
| pad_mode=pad_mode, weight_init=weights, has_bias=False) | |||
| def _BatchNorm2dInit(out_chls, momentum=0.1, affine=True, use_batch_statistics=True): | |||
| """Batchnorm2D wrapper.""" | |||
| gamma_init = Tensor(np.array(np.ones(out_chls)).astype(np.float16)) | |||
| beta_init = Tensor(np.array(np.ones(out_chls) * 0).astype(np.float16)) | |||
| moving_mean_init = Tensor(np.array(np.ones(out_chls) * 0).astype(np.float16)) | |||
| moving_var_init = Tensor(np.array(np.ones(out_chls)).astype(np.float16)) | |||
| return nn.BatchNorm2d(out_chls, momentum=momentum, affine=affine, gamma_init=gamma_init, | |||
| beta_init=beta_init, moving_mean_init=moving_mean_init, | |||
| moving_var_init=moving_var_init, use_batch_statistics=use_batch_statistics) | |||
| class ResNetFea(nn.Cell): | |||
| """ | |||
| ResNet architecture. | |||
| Args: | |||
| block (Cell): Block for network. | |||
| layer_nums (list): Numbers of block in different layers. | |||
| in_channels (list): Input channel in each layer. | |||
| out_channels (list): Output channel in each layer. | |||
| weights_update (bool): Weight update flag. | |||
| Returns: | |||
| Tensor, output tensor. | |||
| Examples: | |||
| >>> ResNet(ResidualBlock, | |||
| >>> [3, 4, 6, 3], | |||
| >>> [64, 256, 512, 1024], | |||
| >>> [256, 512, 1024, 2048], | |||
| >>> False) | |||
| """ | |||
| def __init__(self, | |||
| block, | |||
| layer_nums, | |||
| in_channels, | |||
| out_channels, | |||
| weights_update=False): | |||
| super(ResNetFea, self).__init__() | |||
| if not len(layer_nums) == len(in_channels) == len(out_channels) == 4: | |||
| raise ValueError("the length of " | |||
| "layer_num, inchannel, outchannel list must be 4!") | |||
| bn_training = False | |||
| self.conv1 = _conv(3, 64, kernel_size=7, stride=2, padding=3, pad_mode='pad') | |||
| self.bn1 = _BatchNorm2dInit(64, affine=bn_training, use_batch_statistics=bn_training) | |||
| self.relu = P.ReLU() | |||
| self.maxpool = P.MaxPool(kernel_size=3, strides=2, pad_mode="SAME") | |||
| self.weights_update = weights_update | |||
| if not self.weights_update: | |||
| self.conv1.weight.requires_grad = False | |||
| self.layer1 = self._make_layer(block, | |||
| layer_nums[0], | |||
| in_channel=in_channels[0], | |||
| out_channel=out_channels[0], | |||
| stride=1, | |||
| training=bn_training, | |||
| weights_update=self.weights_update) | |||
| self.layer2 = self._make_layer(block, | |||
| layer_nums[1], | |||
| in_channel=in_channels[1], | |||
| out_channel=out_channels[1], | |||
| stride=2, | |||
| training=bn_training, | |||
| weights_update=True) | |||
| self.layer3 = self._make_layer(block, | |||
| layer_nums[2], | |||
| in_channel=in_channels[2], | |||
| out_channel=out_channels[2], | |||
| stride=2, | |||
| training=bn_training, | |||
| weights_update=True) | |||
| self.layer4 = self._make_layer(block, | |||
| layer_nums[3], | |||
| in_channel=in_channels[3], | |||
| out_channel=out_channels[3], | |||
| stride=2, | |||
| training=bn_training, | |||
| weights_update=True) | |||
| def _make_layer(self, block, layer_num, in_channel, out_channel, stride, training=False, weights_update=False): | |||
| """Make block layer.""" | |||
| layers = [] | |||
| down_sample = False | |||
| if stride != 1 or in_channel != out_channel: | |||
| down_sample = True | |||
| resblk = block(in_channel, | |||
| out_channel, | |||
| stride=stride, | |||
| down_sample=down_sample, | |||
| training=training, | |||
| weights_update=weights_update) | |||
| layers.append(resblk) | |||
| for _ in range(1, layer_num): | |||
| resblk = block(out_channel, out_channel, stride=1, training=training, weights_update=weights_update) | |||
| layers.append(resblk) | |||
| return nn.SequentialCell(layers) | |||
| def construct(self, x): | |||
| x = self.conv1(x) | |||
| x = self.bn1(x) | |||
| x = self.relu(x) | |||
| c1 = self.maxpool(x) | |||
| c2 = self.layer1(c1) | |||
| identity = c2 | |||
| if not self.weights_update: | |||
| identity = F.stop_gradient(c2) | |||
| c3 = self.layer2(identity) | |||
| c4 = self.layer3(c3) | |||
| c5 = self.layer4(c4) | |||
| return identity, c3, c4, c5 | |||
| class ResidualBlockUsing(nn.Cell): | |||
| """ | |||
| ResNet V1 residual block definition. | |||
| Args: | |||
| in_channels (int) - Input channel. | |||
| out_channels (int) - Output channel. | |||
| stride (int) - Stride size for the initial convolutional layer. Default: 1. | |||
| down_sample (bool) - If to do the downsample in block. Default: False. | |||
| momentum (float) - Momentum for batchnorm layer. Default: 0.1. | |||
| training (bool) - Training flag. Default: False. | |||
| weights_updata (bool) - Weights update flag. Default: False. | |||
| Returns: | |||
| Tensor, output tensor. | |||
| Examples: | |||
| ResidualBlock(3,256,stride=2,down_sample=True) | |||
| """ | |||
| expansion = 4 | |||
| def __init__(self, | |||
| in_channels, | |||
| out_channels, | |||
| stride=1, | |||
| down_sample=False, | |||
| momentum=0.1, | |||
| training=False, | |||
| weights_update=False): | |||
| super(ResidualBlockUsing, self).__init__() | |||
| self.affine = weights_update | |||
| out_chls = out_channels // self.expansion | |||
| self.conv1 = _conv(in_channels, out_chls, kernel_size=1, stride=1, padding=0) | |||
| self.bn1 = _BatchNorm2dInit(out_chls, momentum=momentum, affine=self.affine, use_batch_statistics=training) | |||
| self.conv2 = _conv(out_chls, out_chls, kernel_size=3, stride=stride, padding=1) | |||
| self.bn2 = _BatchNorm2dInit(out_chls, momentum=momentum, affine=self.affine, use_batch_statistics=training) | |||
| self.conv3 = _conv(out_chls, out_channels, kernel_size=1, stride=1, padding=0) | |||
| self.bn3 = _BatchNorm2dInit(out_channels, momentum=momentum, affine=self.affine, use_batch_statistics=training) | |||
| if training: | |||
| self.bn1 = self.bn1.set_train() | |||
| self.bn2 = self.bn2.set_train() | |||
| self.bn3 = self.bn3.set_train() | |||
| if not weights_update: | |||
| self.conv1.weight.requires_grad = False | |||
| self.conv2.weight.requires_grad = False | |||
| self.conv3.weight.requires_grad = False | |||
| self.relu = P.ReLU() | |||
| self.downsample = down_sample | |||
| if self.downsample: | |||
| self.conv_down_sample = _conv(in_channels, out_channels, kernel_size=1, stride=stride, padding=0) | |||
| self.bn_down_sample = _BatchNorm2dInit(out_channels, momentum=momentum, affine=self.affine, | |||
| use_batch_statistics=training) | |||
| if training: | |||
| self.bn_down_sample = self.bn_down_sample.set_train() | |||
| if not weights_update: | |||
| self.conv_down_sample.weight.requires_grad = False | |||
| self.add = P.Add() | |||
| def construct(self, x): | |||
| identity = x | |||
| out = self.conv1(x) | |||
| out = self.bn1(out) | |||
| out = self.relu(out) | |||
| out = self.conv2(out) | |||
| out = self.bn2(out) | |||
| out = self.relu(out) | |||
| out = self.conv3(out) | |||
| out = self.bn3(out) | |||
| if self.downsample: | |||
| identity = self.conv_down_sample(identity) | |||
| identity = self.bn_down_sample(identity) | |||
| out = self.add(out, identity) | |||
| out = self.relu(out) | |||
| return out | |||
+ 0
- 181
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/roi_align.py
View File
| @@ -1,181 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn ROIAlign module.""" | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| import mindspore.common.dtype as mstype | |||
| from mindspore.ops import operations as P | |||
| from mindspore.ops import composite as C | |||
| from mindspore.nn import layer as L | |||
| from mindspore.common.tensor import Tensor | |||
| # pylint: disable=locally-disabled, invalid-name, missing-docstring | |||
| class ROIAlign(nn.Cell): | |||
| """ | |||
| Extract RoI features from mulitple feature map. | |||
| Args: | |||
| out_size_h (int) - RoI height. | |||
| out_size_w (int) - RoI width. | |||
| spatial_scale (int) - RoI spatial scale. | |||
| sample_num (int) - RoI sample number. | |||
| """ | |||
| def __init__(self, | |||
| out_size_h, | |||
| out_size_w, | |||
| spatial_scale, | |||
| sample_num=0): | |||
| super(ROIAlign, self).__init__() | |||
| self.out_size = (out_size_h, out_size_w) | |||
| self.spatial_scale = float(spatial_scale) | |||
| self.sample_num = int(sample_num) | |||
| self.align_op = P.ROIAlign(self.out_size[0], self.out_size[1], | |||
| self.spatial_scale, self.sample_num) | |||
| def construct(self, features, rois): | |||
| return self.align_op(features, rois) | |||
| def __repr__(self): | |||
| format_str = self.__class__.__name__ | |||
| format_str += '(out_size={}, spatial_scale={}, sample_num={}'.format( | |||
| self.out_size, self.spatial_scale, self.sample_num) | |||
| return format_str | |||
| class SingleRoIExtractor(nn.Cell): | |||
| """ | |||
| Extract RoI features from a single level feature map. | |||
| If there are mulitple input feature levels, each RoI is mapped to a level | |||
| according to its scale. | |||
| Args: | |||
| config (dict): Config | |||
| roi_layer (dict): Specify RoI layer type and arguments. | |||
| out_channels (int): Output channels of RoI layers. | |||
| featmap_strides (int): Strides of input feature maps. | |||
| batch_size (int): Batchsize. | |||
| finest_scale (int): Scale threshold of mapping to level 0. | |||
| """ | |||
| def __init__(self, | |||
| config, | |||
| roi_layer, | |||
| out_channels, | |||
| featmap_strides, | |||
| batch_size=1, | |||
| finest_scale=56): | |||
| super(SingleRoIExtractor, self).__init__() | |||
| cfg = config | |||
| self.train_batch_size = batch_size | |||
| self.out_channels = out_channels | |||
| self.featmap_strides = featmap_strides | |||
| self.num_levels = len(self.featmap_strides) | |||
| self.out_size = roi_layer['out_size'] | |||
| self.sample_num = roi_layer['sample_num'] | |||
| self.roi_layers = self.build_roi_layers(self.featmap_strides) | |||
| self.roi_layers = L.CellList(self.roi_layers) | |||
| self.sqrt = P.Sqrt() | |||
| self.log = P.Log() | |||
| self.finest_scale_ = finest_scale | |||
| self.clamp = C.clip_by_value | |||
| self.cast = P.Cast() | |||
| self.equal = P.Equal() | |||
| self.select = P.Select() | |||
| _mode_16 = False | |||
| self.dtype = np.float16 if _mode_16 else np.float32 | |||
| self.ms_dtype = mstype.float16 if _mode_16 else mstype.float32 | |||
| self.set_train_local(cfg, training=True) | |||
| def set_train_local(self, config, training=True): | |||
| """Set training flag.""" | |||
| self.training_local = training | |||
| cfg = config | |||
| # Init tensor | |||
| self.batch_size = cfg.roi_sample_num if self.training_local else cfg.rpn_max_num | |||
| self.batch_size = self.train_batch_size*self.batch_size \ | |||
| if self.training_local else cfg.test_batch_size*self.batch_size | |||
| self.ones = Tensor(np.array(np.ones((self.batch_size, 1)), dtype=self.dtype)) | |||
| finest_scale = np.array(np.ones((self.batch_size, 1)), dtype=self.dtype) * self.finest_scale_ | |||
| self.finest_scale = Tensor(finest_scale) | |||
| self.epslion = Tensor(np.array(np.ones((self.batch_size, 1)), dtype=self.dtype)*self.dtype(1e-6)) | |||
| self.zeros = Tensor(np.array(np.zeros((self.batch_size, 1)), dtype=np.int32)) | |||
| self.max_levels = Tensor(np.array(np.ones((self.batch_size, 1)), dtype=np.int32)*(self.num_levels-1)) | |||
| self.twos = Tensor(np.array(np.ones((self.batch_size, 1)), dtype=self.dtype) * 2) | |||
| self.res_ = Tensor(np.array(np.zeros((self.batch_size, self.out_channels, | |||
| self.out_size, self.out_size)), dtype=self.dtype)) | |||
| def num_inputs(self): | |||
| return len(self.featmap_strides) | |||
| def init_weights(self): | |||
| pass | |||
| def log2(self, value): | |||
| return self.log(value) / self.log(self.twos) | |||
| def build_roi_layers(self, featmap_strides): | |||
| roi_layers = [] | |||
| for s in featmap_strides: | |||
| layer_cls = ROIAlign(self.out_size, self.out_size, | |||
| spatial_scale=1 / s, | |||
| sample_num=self.sample_num) | |||
| roi_layers.append(layer_cls) | |||
| return roi_layers | |||
| def _c_map_roi_levels(self, rois): | |||
| """Map rois to corresponding feature levels by scales. | |||
| - scale < finest_scale * 2: level 0 | |||
| - finest_scale * 2 <= scale < finest_scale * 4: level 1 | |||
| - finest_scale * 4 <= scale < finest_scale * 8: level 2 | |||
| - scale >= finest_scale * 8: level 3 | |||
| Args: | |||
| rois (Tensor): Input RoIs, shape (k, 5). | |||
| num_levels (int): Total level number. | |||
| Returns: | |||
| Tensor: Level index (0-based) of each RoI, shape (k, ) | |||
| """ | |||
| scale = self.sqrt(rois[::, 3:4:1] - rois[::, 1:2:1] + self.ones) * \ | |||
| self.sqrt(rois[::, 4:5:1] - rois[::, 2:3:1] + self.ones) | |||
| target_lvls = self.log2(scale / self.finest_scale + self.epslion) | |||
| target_lvls = P.Floor()(target_lvls) | |||
| target_lvls = self.cast(target_lvls, mstype.int32) | |||
| target_lvls = self.clamp(target_lvls, self.zeros, self.max_levels) | |||
| return target_lvls | |||
| def construct(self, rois, feat1, feat2, feat3, feat4): | |||
| feats = (feat1, feat2, feat3, feat4) | |||
| res = self.res_ | |||
| target_lvls = self._c_map_roi_levels(rois) | |||
| for i in range(self.num_levels): | |||
| mask = self.equal(target_lvls, P.ScalarToArray()(i)) | |||
| mask = P.Reshape()(mask, (-1, 1, 1, 1)) | |||
| roi_feats_t = self.roi_layers[i](feats[i], rois) | |||
| mask = self.cast(P.Tile()(self.cast(mask, mstype.int32), (1, 256, 7, 7)), mstype.bool_) | |||
| res = self.select(mask, roi_feats_t, res) | |||
| return res | |||
+ 0
- 315
examples/model_security/model_attacks/cv/faster_rcnn/src/FasterRcnn/rpn.py
View File
| @@ -1,315 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """RPN for fasterRCNN""" | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| import mindspore.common.dtype as mstype | |||
| from mindspore.ops import operations as P | |||
| from mindspore import Tensor | |||
| from mindspore.ops import functional as F | |||
| from mindspore.common.initializer import initializer | |||
| from .bbox_assign_sample import BboxAssignSample | |||
| # pylint: disable=locally-disabled, invalid-name, missing-docstring | |||
| # pylint: disable=locally-disabled, invalid-name, missing-docstring | |||
| class RpnRegClsBlock(nn.Cell): | |||
| """ | |||
| Rpn reg cls block for rpn layer | |||
| Args: | |||
| in_channels (int) - Input channels of shared convolution. | |||
| feat_channels (int) - Output channels of shared convolution. | |||
| num_anchors (int) - The anchor number. | |||
| cls_out_channels (int) - Output channels of classification convolution. | |||
| weight_conv (Tensor) - weight init for rpn conv. | |||
| bias_conv (Tensor) - bias init for rpn conv. | |||
| weight_cls (Tensor) - weight init for rpn cls conv. | |||
| bias_cls (Tensor) - bias init for rpn cls conv. | |||
| weight_reg (Tensor) - weight init for rpn reg conv. | |||
| bias_reg (Tensor) - bias init for rpn reg conv. | |||
| Returns: | |||
| Tensor, output tensor. | |||
| """ | |||
| def __init__(self, | |||
| in_channels, | |||
| feat_channels, | |||
| num_anchors, | |||
| cls_out_channels, | |||
| weight_conv, | |||
| bias_conv, | |||
| weight_cls, | |||
| bias_cls, | |||
| weight_reg, | |||
| bias_reg): | |||
| super(RpnRegClsBlock, self).__init__() | |||
| self.rpn_conv = nn.Conv2d(in_channels, feat_channels, kernel_size=3, stride=1, pad_mode='same', | |||
| has_bias=True, weight_init=weight_conv, bias_init=bias_conv) | |||
| self.relu = nn.ReLU() | |||
| self.rpn_cls = nn.Conv2d(feat_channels, num_anchors * cls_out_channels, kernel_size=1, pad_mode='valid', | |||
| has_bias=True, weight_init=weight_cls, bias_init=bias_cls) | |||
| self.rpn_reg = nn.Conv2d(feat_channels, num_anchors * 4, kernel_size=1, pad_mode='valid', | |||
| has_bias=True, weight_init=weight_reg, bias_init=bias_reg) | |||
| def construct(self, x): | |||
| x = self.relu(self.rpn_conv(x)) | |||
| x1 = self.rpn_cls(x) | |||
| x2 = self.rpn_reg(x) | |||
| return x1, x2 | |||
| class RPN(nn.Cell): | |||
| """ | |||
| ROI proposal network.. | |||
| Args: | |||
| config (dict) - Config. | |||
| batch_size (int) - Batchsize. | |||
| in_channels (int) - Input channels of shared convolution. | |||
| feat_channels (int) - Output channels of shared convolution. | |||
| num_anchors (int) - The anchor number. | |||
| cls_out_channels (int) - Output channels of classification convolution. | |||
| Returns: | |||
| Tuple, tuple of output tensor. | |||
| Examples: | |||
| RPN(config=config, batch_size=2, in_channels=256, feat_channels=1024, | |||
| num_anchors=3, cls_out_channels=512) | |||
| """ | |||
| def __init__(self, | |||
| config, | |||
| batch_size, | |||
| in_channels, | |||
| feat_channels, | |||
| num_anchors, | |||
| cls_out_channels): | |||
| super(RPN, self).__init__() | |||
| cfg_rpn = config | |||
| self.num_bboxes = cfg_rpn.num_bboxes | |||
| self.slice_index = () | |||
| self.feature_anchor_shape = () | |||
| self.slice_index += (0,) | |||
| index = 0 | |||
| for shape in cfg_rpn.feature_shapes: | |||
| self.slice_index += (self.slice_index[index] + shape[0] * shape[1] * num_anchors,) | |||
| self.feature_anchor_shape += (shape[0] * shape[1] * num_anchors * batch_size,) | |||
| index += 1 | |||
| self.num_anchors = num_anchors | |||
| self.batch_size = batch_size | |||
| self.test_batch_size = cfg_rpn.test_batch_size | |||
| self.num_layers = 5 | |||
| self.real_ratio = Tensor(np.ones((1, 1)).astype(np.float16)) | |||
| self.rpn_convs_list = nn.layer.CellList(self._make_rpn_layer(self.num_layers, in_channels, feat_channels, | |||
| num_anchors, cls_out_channels)) | |||
| self.transpose = P.Transpose() | |||
| self.reshape = P.Reshape() | |||
| self.concat = P.Concat(axis=0) | |||
| self.fill = P.Fill() | |||
| self.placeh1 = Tensor(np.ones((1,)).astype(np.float16)) | |||
| self.trans_shape = (0, 2, 3, 1) | |||
| self.reshape_shape_reg = (-1, 4) | |||
| self.reshape_shape_cls = (-1,) | |||
| self.rpn_loss_reg_weight = Tensor(np.array(cfg_rpn.rpn_loss_reg_weight).astype(np.float16)) | |||
| self.rpn_loss_cls_weight = Tensor(np.array(cfg_rpn.rpn_loss_cls_weight).astype(np.float16)) | |||
| self.num_expected_total = Tensor(np.array(cfg_rpn.num_expected_neg * self.batch_size).astype(np.float16)) | |||
| self.num_bboxes = cfg_rpn.num_bboxes | |||
| self.get_targets = BboxAssignSample(cfg_rpn, self.batch_size, self.num_bboxes, False) | |||
| self.CheckValid = P.CheckValid() | |||
| self.sum_loss = P.ReduceSum() | |||
| self.loss_cls = P.SigmoidCrossEntropyWithLogits() | |||
| self.loss_bbox = P.SmoothL1Loss(beta=1.0/9.0) | |||
| self.squeeze = P.Squeeze() | |||
| self.cast = P.Cast() | |||
| self.tile = P.Tile() | |||
| self.zeros_like = P.ZerosLike() | |||
| self.loss = Tensor(np.zeros((1,)).astype(np.float16)) | |||
| self.clsloss = Tensor(np.zeros((1,)).astype(np.float16)) | |||
| self.regloss = Tensor(np.zeros((1,)).astype(np.float16)) | |||
| def _make_rpn_layer(self, num_layers, in_channels, feat_channels, num_anchors, cls_out_channels): | |||
| """ | |||
| make rpn layer for rpn proposal network | |||
| Args: | |||
| num_layers (int) - layer num. | |||
| in_channels (int) - Input channels of shared convolution. | |||
| feat_channels (int) - Output channels of shared convolution. | |||
| num_anchors (int) - The anchor number. | |||
| cls_out_channels (int) - Output channels of classification convolution. | |||
| Returns: | |||
| List, list of RpnRegClsBlock cells. | |||
| """ | |||
| rpn_layer = [] | |||
| shp_weight_conv = (feat_channels, in_channels, 3, 3) | |||
| shp_bias_conv = (feat_channels,) | |||
| weight_conv = initializer('Normal', shape=shp_weight_conv, dtype=mstype.float16).to_tensor() | |||
| bias_conv = initializer(0, shape=shp_bias_conv, dtype=mstype.float16).to_tensor() | |||
| shp_weight_cls = (num_anchors * cls_out_channels, feat_channels, 1, 1) | |||
| shp_bias_cls = (num_anchors * cls_out_channels,) | |||
| weight_cls = initializer('Normal', shape=shp_weight_cls, dtype=mstype.float16).to_tensor() | |||
| bias_cls = initializer(0, shape=shp_bias_cls, dtype=mstype.float16).to_tensor() | |||
| shp_weight_reg = (num_anchors * 4, feat_channels, 1, 1) | |||
| shp_bias_reg = (num_anchors * 4,) | |||
| weight_reg = initializer('Normal', shape=shp_weight_reg, dtype=mstype.float16).to_tensor() | |||
| bias_reg = initializer(0, shape=shp_bias_reg, dtype=mstype.float16).to_tensor() | |||
| for i in range(num_layers): | |||
| rpn_layer.append(RpnRegClsBlock(in_channels, feat_channels, num_anchors, cls_out_channels, \ | |||
| weight_conv, bias_conv, weight_cls, \ | |||
| bias_cls, weight_reg, bias_reg)) | |||
| for i in range(1, num_layers): | |||
| rpn_layer[i].rpn_conv.weight = rpn_layer[0].rpn_conv.weight | |||
| rpn_layer[i].rpn_cls.weight = rpn_layer[0].rpn_cls.weight | |||
| rpn_layer[i].rpn_reg.weight = rpn_layer[0].rpn_reg.weight | |||
| rpn_layer[i].rpn_conv.bias = rpn_layer[0].rpn_conv.bias | |||
| rpn_layer[i].rpn_cls.bias = rpn_layer[0].rpn_cls.bias | |||
| rpn_layer[i].rpn_reg.bias = rpn_layer[0].rpn_reg.bias | |||
| return rpn_layer | |||
| def construct(self, inputs, img_metas, anchor_list, gt_bboxes, gt_labels, gt_valids): | |||
| loss_print = () | |||
| rpn_cls_score = () | |||
| rpn_bbox_pred = () | |||
| rpn_cls_score_total = () | |||
| rpn_bbox_pred_total = () | |||
| for i in range(self.num_layers): | |||
| x1, x2 = self.rpn_convs_list[i](inputs[i]) | |||
| rpn_cls_score_total = rpn_cls_score_total + (x1,) | |||
| rpn_bbox_pred_total = rpn_bbox_pred_total + (x2,) | |||
| x1 = self.transpose(x1, self.trans_shape) | |||
| x1 = self.reshape(x1, self.reshape_shape_cls) | |||
| x2 = self.transpose(x2, self.trans_shape) | |||
| x2 = self.reshape(x2, self.reshape_shape_reg) | |||
| rpn_cls_score = rpn_cls_score + (x1,) | |||
| rpn_bbox_pred = rpn_bbox_pred + (x2,) | |||
| loss = self.loss | |||
| clsloss = self.clsloss | |||
| regloss = self.regloss | |||
| bbox_targets = () | |||
| bbox_weights = () | |||
| labels = () | |||
| label_weights = () | |||
| output = () | |||
| if self.training: | |||
| for i in range(self.batch_size): | |||
| multi_level_flags = () | |||
| anchor_list_tuple = () | |||
| for j in range(self.num_layers): | |||
| res = self.cast(self.CheckValid(anchor_list[j], self.squeeze(img_metas[i:i + 1:1, ::])), | |||
| mstype.int32) | |||
| multi_level_flags = multi_level_flags + (res,) | |||
| anchor_list_tuple = anchor_list_tuple + (anchor_list[j],) | |||
| valid_flag_list = self.concat(multi_level_flags) | |||
| anchor_using_list = self.concat(anchor_list_tuple) | |||
| gt_bboxes_i = self.squeeze(gt_bboxes[i:i + 1:1, ::]) | |||
| gt_labels_i = self.squeeze(gt_labels[i:i + 1:1, ::]) | |||
| gt_valids_i = self.squeeze(gt_valids[i:i + 1:1, ::]) | |||
| bbox_target, bbox_weight, label, label_weight = self.get_targets(gt_bboxes_i, | |||
| gt_labels_i, | |||
| self.cast(valid_flag_list, | |||
| mstype.bool_), | |||
| anchor_using_list, gt_valids_i) | |||
| bbox_weight = self.cast(bbox_weight, mstype.float16) | |||
| label = self.cast(label, mstype.float16) | |||
| label_weight = self.cast(label_weight, mstype.float16) | |||
| for j in range(self.num_layers): | |||
| begin = self.slice_index[j] | |||
| end = self.slice_index[j + 1] | |||
| stride = 1 | |||
| bbox_targets += (bbox_target[begin:end:stride, ::],) | |||
| bbox_weights += (bbox_weight[begin:end:stride],) | |||
| labels += (label[begin:end:stride],) | |||
| label_weights += (label_weight[begin:end:stride],) | |||
| for i in range(self.num_layers): | |||
| bbox_target_using = () | |||
| bbox_weight_using = () | |||
| label_using = () | |||
| label_weight_using = () | |||
| for j in range(self.batch_size): | |||
| bbox_target_using += (bbox_targets[i + (self.num_layers * j)],) | |||
| bbox_weight_using += (bbox_weights[i + (self.num_layers * j)],) | |||
| label_using += (labels[i + (self.num_layers * j)],) | |||
| label_weight_using += (label_weights[i + (self.num_layers * j)],) | |||
| bbox_target_with_batchsize = self.concat(bbox_target_using) | |||
| bbox_weight_with_batchsize = self.concat(bbox_weight_using) | |||
| label_with_batchsize = self.concat(label_using) | |||
| label_weight_with_batchsize = self.concat(label_weight_using) | |||
| # stop | |||
| bbox_target_ = F.stop_gradient(bbox_target_with_batchsize) | |||
| bbox_weight_ = F.stop_gradient(bbox_weight_with_batchsize) | |||
| label_ = F.stop_gradient(label_with_batchsize) | |||
| label_weight_ = F.stop_gradient(label_weight_with_batchsize) | |||
| cls_score_i = rpn_cls_score[i] | |||
| reg_score_i = rpn_bbox_pred[i] | |||
| loss_cls = self.loss_cls(cls_score_i, label_) | |||
| loss_cls_item = loss_cls * label_weight_ | |||
| loss_cls_item = self.sum_loss(loss_cls_item, (0,)) / self.num_expected_total | |||
| loss_reg = self.loss_bbox(reg_score_i, bbox_target_) | |||
| bbox_weight_ = self.tile(self.reshape(bbox_weight_, (self.feature_anchor_shape[i], 1)), (1, 4)) | |||
| loss_reg = loss_reg * bbox_weight_ | |||
| loss_reg_item = self.sum_loss(loss_reg, (1,)) | |||
| loss_reg_item = self.sum_loss(loss_reg_item, (0,)) / self.num_expected_total | |||
| loss_total = self.rpn_loss_cls_weight * loss_cls_item + self.rpn_loss_reg_weight * loss_reg_item | |||
| loss += loss_total | |||
| loss_print += (loss_total, loss_cls_item, loss_reg_item) | |||
| clsloss += loss_cls_item | |||
| regloss += loss_reg_item | |||
| output = (loss, rpn_cls_score_total, rpn_bbox_pred_total, clsloss, regloss, loss_print) | |||
| else: | |||
| output = (self.placeh1, rpn_cls_score_total, rpn_bbox_pred_total, self.placeh1, self.placeh1, self.placeh1) | |||
| return output | |||
+ 0
- 158
examples/model_security/model_attacks/cv/faster_rcnn/src/config.py
View File
| @@ -1,158 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # =========================================================================== | |||
| """ | |||
| network config setting, will be used in train.py and eval.py | |||
| """ | |||
| from easydict import EasyDict as ed | |||
| config = ed({ | |||
| "img_width": 1280, | |||
| "img_height": 768, | |||
| "keep_ratio": False, | |||
| "flip_ratio": 0.5, | |||
| "photo_ratio": 0.5, | |||
| "expand_ratio": 1.0, | |||
| # anchor | |||
| "feature_shapes": [(192, 320), (96, 160), (48, 80), (24, 40), (12, 20)], | |||
| "anchor_scales": [8], | |||
| "anchor_ratios": [0.5, 1.0, 2.0], | |||
| "anchor_strides": [4, 8, 16, 32, 64], | |||
| "num_anchors": 3, | |||
| # resnet | |||
| "resnet_block": [3, 4, 6, 3], | |||
| "resnet_in_channels": [64, 256, 512, 1024], | |||
| "resnet_out_channels": [256, 512, 1024, 2048], | |||
| # fpn | |||
| "fpn_in_channels": [256, 512, 1024, 2048], | |||
| "fpn_out_channels": 256, | |||
| "fpn_num_outs": 5, | |||
| # rpn | |||
| "rpn_in_channels": 256, | |||
| "rpn_feat_channels": 256, | |||
| "rpn_loss_cls_weight": 1.0, | |||
| "rpn_loss_reg_weight": 1.0, | |||
| "rpn_cls_out_channels": 1, | |||
| "rpn_target_means": [0., 0., 0., 0.], | |||
| "rpn_target_stds": [1.0, 1.0, 1.0, 1.0], | |||
| # bbox_assign_sampler | |||
| "neg_iou_thr": 0.3, | |||
| "pos_iou_thr": 0.7, | |||
| "min_pos_iou": 0.3, | |||
| "num_bboxes": 245520, | |||
| "num_gts": 128, | |||
| "num_expected_neg": 256, | |||
| "num_expected_pos": 128, | |||
| # proposal | |||
| "activate_num_classes": 2, | |||
| "use_sigmoid_cls": True, | |||
| # roi_align | |||
| "roi_layer": dict(type='RoIAlign', out_size=7, sample_num=2), | |||
| "roi_align_out_channels": 256, | |||
| "roi_align_featmap_strides": [4, 8, 16, 32], | |||
| "roi_align_finest_scale": 56, | |||
| "roi_sample_num": 640, | |||
| # bbox_assign_sampler_stage2 | |||
| "neg_iou_thr_stage2": 0.5, | |||
| "pos_iou_thr_stage2": 0.5, | |||
| "min_pos_iou_stage2": 0.5, | |||
| "num_bboxes_stage2": 2000, | |||
| "num_expected_pos_stage2": 128, | |||
| "num_expected_neg_stage2": 512, | |||
| "num_expected_total_stage2": 512, | |||
| # rcnn | |||
| "rcnn_num_layers": 2, | |||
| "rcnn_in_channels": 256, | |||
| "rcnn_fc_out_channels": 1024, | |||
| "rcnn_loss_cls_weight": 1, | |||
| "rcnn_loss_reg_weight": 1, | |||
| "rcnn_target_means": [0., 0., 0., 0.], | |||
| "rcnn_target_stds": [0.1, 0.1, 0.2, 0.2], | |||
| # train proposal | |||
| "rpn_proposal_nms_across_levels": False, | |||
| "rpn_proposal_nms_pre": 2000, | |||
| "rpn_proposal_nms_post": 2000, | |||
| "rpn_proposal_max_num": 2000, | |||
| "rpn_proposal_nms_thr": 0.7, | |||
| "rpn_proposal_min_bbox_size": 0, | |||
| # test proposal | |||
| "rpn_nms_across_levels": False, | |||
| "rpn_nms_pre": 1000, | |||
| "rpn_nms_post": 1000, | |||
| "rpn_max_num": 1000, | |||
| "rpn_nms_thr": 0.7, | |||
| "rpn_min_bbox_min_size": 0, | |||
| "test_score_thr": 0.05, | |||
| "test_iou_thr": 0.5, | |||
| "test_max_per_img": 100, | |||
| "test_batch_size": 1, | |||
| "rpn_head_loss_type": "CrossEntropyLoss", | |||
| "rpn_head_use_sigmoid": True, | |||
| "rpn_head_weight": 1.0, | |||
| # LR | |||
| "base_lr": 0.02, | |||
| "base_step": 58633, | |||
| "total_epoch": 13, | |||
| "warmup_step": 500, | |||
| "warmup_mode": "linear", | |||
| "warmup_ratio": 1/3.0, | |||
| "sgd_step": [8, 11], | |||
| "sgd_momentum": 0.9, | |||
| # train | |||
| "batch_size": 1, | |||
| "loss_scale": 1, | |||
| "momentum": 0.91, | |||
| "weight_decay": 1e-4, | |||
| "epoch_size": 12, | |||
| "save_checkpoint": True, | |||
| "save_checkpoint_epochs": 1, | |||
| "keep_checkpoint_max": 10, | |||
| "save_checkpoint_path": "./", | |||
| "mindrecord_dir": "../MindRecord_COCO_TRAIN", | |||
| "coco_root": "./cocodataset/", | |||
| "train_data_type": "train2017", | |||
| "val_data_type": "val2017", | |||
| "instance_set": "annotations/instances_{}.json", | |||
| "coco_classes": ('background', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', | |||
| 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', | |||
| 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', | |||
| 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', | |||
| 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', | |||
| 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', | |||
| 'kite', 'baseball bat', 'baseball glove', 'skateboard', | |||
| 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', | |||
| 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', | |||
| 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', | |||
| 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', | |||
| 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', | |||
| 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', | |||
| 'refrigerator', 'book', 'clock', 'vase', 'scissors', | |||
| 'teddy bear', 'hair drier', 'toothbrush'), | |||
| "num_classes": 81 | |||
| }) | |||
+ 0
- 505
examples/model_security/model_attacks/cv/faster_rcnn/src/dataset.py
View File
| @@ -1,505 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn dataset""" | |||
| from __future__ import division | |||
| import os | |||
| import numpy as np | |||
| from numpy import random | |||
| import mmcv | |||
| import mindspore.dataset as de | |||
| import mindspore.dataset.vision.c_transforms as C | |||
| import mindspore.dataset.transforms.c_transforms as CC | |||
| import mindspore.common.dtype as mstype | |||
| from mindspore.mindrecord import FileWriter | |||
| from src.config import config | |||
| # pylint: disable=locally-disabled, unused-variable | |||
| def bbox_overlaps(bboxes1, bboxes2, mode='iou'): | |||
| """Calculate the ious between each bbox of bboxes1 and bboxes2. | |||
| Args: | |||
| bboxes1(ndarray): shape (n, 4) | |||
| bboxes2(ndarray): shape (k, 4) | |||
| mode(str): iou (intersection over union) or iof (intersection | |||
| over foreground) | |||
| Returns: | |||
| ious(ndarray): shape (n, k) | |||
| """ | |||
| assert mode in ['iou', 'iof'] | |||
| bboxes1 = bboxes1.astype(np.float32) | |||
| bboxes2 = bboxes2.astype(np.float32) | |||
| rows = bboxes1.shape[0] | |||
| cols = bboxes2.shape[0] | |||
| ious = np.zeros((rows, cols), dtype=np.float32) | |||
| if rows * cols == 0: | |||
| return ious | |||
| exchange = False | |||
| if bboxes1.shape[0] > bboxes2.shape[0]: | |||
| bboxes1, bboxes2 = bboxes2, bboxes1 | |||
| ious = np.zeros((cols, rows), dtype=np.float32) | |||
| exchange = True | |||
| area1 = (bboxes1[:, 2] - bboxes1[:, 0] + 1) * (bboxes1[:, 3] - bboxes1[:, 1] + 1) | |||
| area2 = (bboxes2[:, 2] - bboxes2[:, 0] + 1) * (bboxes2[:, 3] - bboxes2[:, 1] + 1) | |||
| for i in range(bboxes1.shape[0]): | |||
| x_start = np.maximum(bboxes1[i, 0], bboxes2[:, 0]) | |||
| y_start = np.maximum(bboxes1[i, 1], bboxes2[:, 1]) | |||
| x_end = np.minimum(bboxes1[i, 2], bboxes2[:, 2]) | |||
| y_end = np.minimum(bboxes1[i, 3], bboxes2[:, 3]) | |||
| overlap = np.maximum(x_end - x_start + 1, 0) * np.maximum( | |||
| y_end - y_start + 1, 0) | |||
| if mode == 'iou': | |||
| union = area1[i] + area2 - overlap | |||
| else: | |||
| union = area1[i] if not exchange else area2 | |||
| ious[i, :] = overlap / union | |||
| if exchange: | |||
| ious = ious.T | |||
| return ious | |||
| class PhotoMetricDistortion: | |||
| """Photo Metric Distortion""" | |||
| def __init__(self, | |||
| brightness_delta=32, | |||
| contrast_range=(0.5, 1.5), | |||
| saturation_range=(0.5, 1.5), | |||
| hue_delta=18): | |||
| self.brightness_delta = brightness_delta | |||
| self.contrast_lower, self.contrast_upper = contrast_range | |||
| self.saturation_lower, self.saturation_upper = saturation_range | |||
| self.hue_delta = hue_delta | |||
| def __call__(self, img, boxes, labels): | |||
| # random brightness | |||
| img = img.astype('float32') | |||
| if random.randint(2): | |||
| delta = random.uniform(-self.brightness_delta, | |||
| self.brightness_delta) | |||
| img += delta | |||
| # mode == 0 --> do random contrast first | |||
| # mode == 1 --> do random contrast last | |||
| mode = random.randint(2) | |||
| if mode == 1: | |||
| if random.randint(2): | |||
| alpha = random.uniform(self.contrast_lower, | |||
| self.contrast_upper) | |||
| img *= alpha | |||
| # convert color from BGR to HSV | |||
| img = mmcv.bgr2hsv(img) | |||
| # random saturation | |||
| if random.randint(2): | |||
| img[..., 1] *= random.uniform(self.saturation_lower, | |||
| self.saturation_upper) | |||
| # random hue | |||
| if random.randint(2): | |||
| img[..., 0] += random.uniform(-self.hue_delta, self.hue_delta) | |||
| img[..., 0][img[..., 0] > 360] -= 360 | |||
| img[..., 0][img[..., 0] < 0] += 360 | |||
| # convert color from HSV to BGR | |||
| img = mmcv.hsv2bgr(img) | |||
| # random contrast | |||
| if mode == 0: | |||
| if random.randint(2): | |||
| alpha = random.uniform(self.contrast_lower, | |||
| self.contrast_upper) | |||
| img *= alpha | |||
| # randomly swap channels | |||
| if random.randint(2): | |||
| img = img[..., random.permutation(3)] | |||
| return img, boxes, labels | |||
| class Expand: | |||
| """expand image""" | |||
| def __init__(self, mean=(0, 0, 0), to_rgb=True, ratio_range=(1, 4)): | |||
| if to_rgb: | |||
| self.mean = mean[::-1] | |||
| else: | |||
| self.mean = mean | |||
| self.min_ratio, self.max_ratio = ratio_range | |||
| def __call__(self, img, boxes, labels): | |||
| if random.randint(2): | |||
| return img, boxes, labels | |||
| h, w, c = img.shape | |||
| ratio = random.uniform(self.min_ratio, self.max_ratio) | |||
| expand_img = np.full((int(h * ratio), int(w * ratio), c), | |||
| self.mean).astype(img.dtype) | |||
| left = int(random.uniform(0, w * ratio - w)) | |||
| top = int(random.uniform(0, h * ratio - h)) | |||
| expand_img[top:top + h, left:left + w] = img | |||
| img = expand_img | |||
| boxes += np.tile((left, top), 2) | |||
| return img, boxes, labels | |||
| def rescale_column(img, img_shape, gt_bboxes, gt_label, gt_num): | |||
| """rescale operation for image""" | |||
| img_data, scale_factor = mmcv.imrescale(img, (config.img_width, config.img_height), return_scale=True) | |||
| if img_data.shape[0] > config.img_height: | |||
| img_data, scale_factor2 = mmcv.imrescale(img_data, (config.img_height, config.img_width), return_scale=True) | |||
| scale_factor = scale_factor * scale_factor2 | |||
| img_shape = np.append(img_shape, scale_factor) | |||
| img_shape = np.asarray(img_shape, dtype=np.float32) | |||
| gt_bboxes = gt_bboxes * scale_factor | |||
| gt_bboxes[:, 0::2] = np.clip(gt_bboxes[:, 0::2], 0, img_shape[1] - 1) | |||
| gt_bboxes[:, 1::2] = np.clip(gt_bboxes[:, 1::2], 0, img_shape[0] - 1) | |||
| return (img_data, img_shape, gt_bboxes, gt_label, gt_num) | |||
| def resize_column(img, img_shape, gt_bboxes, gt_label, gt_num): | |||
| """resize operation for image""" | |||
| img_data = img | |||
| img_data, w_scale, h_scale = mmcv.imresize( | |||
| img_data, (config.img_width, config.img_height), return_scale=True) | |||
| scale_factor = np.array( | |||
| [w_scale, h_scale, w_scale, h_scale], dtype=np.float32) | |||
| img_shape = (config.img_height, config.img_width, 1.0) | |||
| img_shape = np.asarray(img_shape, dtype=np.float32) | |||
| gt_bboxes = gt_bboxes * scale_factor | |||
| gt_bboxes[:, 0::2] = np.clip(gt_bboxes[:, 0::2], 0, img_shape[1] - 1) | |||
| gt_bboxes[:, 1::2] = np.clip(gt_bboxes[:, 1::2], 0, img_shape[0] - 1) | |||
| return (img_data, img_shape, gt_bboxes, gt_label, gt_num) | |||
| def resize_column_test(img, img_shape, gt_bboxes, gt_label, gt_num): | |||
| """resize operation for image of eval""" | |||
| img_data = img | |||
| img_data, w_scale, h_scale = mmcv.imresize( | |||
| img_data, (config.img_width, config.img_height), return_scale=True) | |||
| scale_factor = np.array( | |||
| [w_scale, h_scale, w_scale, h_scale], dtype=np.float32) | |||
| img_shape = np.append(img_shape, (h_scale, w_scale)) | |||
| img_shape = np.asarray(img_shape, dtype=np.float32) | |||
| gt_bboxes = gt_bboxes * scale_factor | |||
| gt_bboxes[:, 0::2] = np.clip(gt_bboxes[:, 0::2], 0, img_shape[1] - 1) | |||
| gt_bboxes[:, 1::2] = np.clip(gt_bboxes[:, 1::2], 0, img_shape[0] - 1) | |||
| return (img_data, img_shape, gt_bboxes, gt_label, gt_num) | |||
| def impad_to_multiple_column(img, img_shape, gt_bboxes, gt_label, gt_num): | |||
| """impad operation for image""" | |||
| img_data = mmcv.impad(img, (config.img_height, config.img_width)) | |||
| img_data = img_data.astype(np.float32) | |||
| return (img_data, img_shape, gt_bboxes, gt_label, gt_num) | |||
| def imnormalize_column(img, img_shape, gt_bboxes, gt_label, gt_num): | |||
| """imnormalize operation for image""" | |||
| img_data = mmcv.imnormalize(img, [123.675, 116.28, 103.53], [58.395, 57.12, 57.375], True) | |||
| img_data = img_data.astype(np.float32) | |||
| return (img_data, img_shape, gt_bboxes, gt_label, gt_num) | |||
| def flip_column(img, img_shape, gt_bboxes, gt_label, gt_num): | |||
| """flip operation for image""" | |||
| img_data = img | |||
| img_data = mmcv.imflip(img_data) | |||
| flipped = gt_bboxes.copy() | |||
| _, w, _ = img_data.shape | |||
| flipped[..., 0::4] = w - gt_bboxes[..., 2::4] - 1 | |||
| flipped[..., 2::4] = w - gt_bboxes[..., 0::4] - 1 | |||
| return (img_data, img_shape, flipped, gt_label, gt_num) | |||
| def flipped_generation(img, img_shape, gt_bboxes, gt_label, gt_num): | |||
| """flipped generation""" | |||
| img_data = img | |||
| flipped = gt_bboxes.copy() | |||
| _, w, _ = img_data.shape | |||
| flipped[..., 0::4] = w - gt_bboxes[..., 2::4] - 1 | |||
| flipped[..., 2::4] = w - gt_bboxes[..., 0::4] - 1 | |||
| return (img_data, img_shape, flipped, gt_label, gt_num) | |||
| def image_bgr_rgb(img, img_shape, gt_bboxes, gt_label, gt_num): | |||
| img_data = img[:, :, ::-1] | |||
| return (img_data, img_shape, gt_bboxes, gt_label, gt_num) | |||
| def transpose_column(img, img_shape, gt_bboxes, gt_label, gt_num): | |||
| """transpose operation for image""" | |||
| img_data = img.transpose(2, 0, 1).copy() | |||
| img_data = img_data.astype(np.float16) | |||
| img_shape = img_shape.astype(np.float16) | |||
| gt_bboxes = gt_bboxes.astype(np.float16) | |||
| gt_label = gt_label.astype(np.int32) | |||
| gt_num = gt_num.astype(np.bool) | |||
| return (img_data, img_shape, gt_bboxes, gt_label, gt_num) | |||
| def photo_crop_column(img, img_shape, gt_bboxes, gt_label, gt_num): | |||
| """photo crop operation for image""" | |||
| random_photo = PhotoMetricDistortion() | |||
| img_data, gt_bboxes, gt_label = random_photo(img, gt_bboxes, gt_label) | |||
| return (img_data, img_shape, gt_bboxes, gt_label, gt_num) | |||
| def expand_column(img, img_shape, gt_bboxes, gt_label, gt_num): | |||
| """expand operation for image""" | |||
| expand = Expand() | |||
| img, gt_bboxes, gt_label = expand(img, gt_bboxes, gt_label) | |||
| return (img, img_shape, gt_bboxes, gt_label, gt_num) | |||
| def preprocess_fn(image, box, is_training): | |||
| """Preprocess function for dataset.""" | |||
| def _infer_data(image_bgr, image_shape, gt_box_new, gt_label_new, gt_iscrowd_new_revert): | |||
| image_shape = image_shape[:2] | |||
| input_data = image_bgr, image_shape, gt_box_new, gt_label_new, gt_iscrowd_new_revert | |||
| if config.keep_ratio: | |||
| input_data = rescale_column(*input_data) | |||
| else: | |||
| input_data = resize_column_test(*input_data) | |||
| input_data = image_bgr_rgb(*input_data) | |||
| output_data = input_data | |||
| return output_data | |||
| def _data_aug(image, box, is_training): | |||
| """Data augmentation function.""" | |||
| image_bgr = image.copy() | |||
| image_bgr[:, :, 0] = image[:, :, 2] | |||
| image_bgr[:, :, 1] = image[:, :, 1] | |||
| image_bgr[:, :, 2] = image[:, :, 0] | |||
| image_shape = image_bgr.shape[:2] | |||
| gt_box = box[:, :4] | |||
| gt_label = box[:, 4] | |||
| gt_iscrowd = box[:, 5] | |||
| pad_max_number = 128 | |||
| gt_box_new = np.pad(gt_box, ((0, pad_max_number - box.shape[0]), (0, 0)), mode="constant", constant_values=0) | |||
| gt_label_new = np.pad(gt_label, ((0, pad_max_number - box.shape[0])), mode="constant", constant_values=-1) | |||
| gt_iscrowd_new = np.pad(gt_iscrowd, ((0, pad_max_number - box.shape[0])), mode="constant", constant_values=1) | |||
| gt_iscrowd_new_revert = (~(gt_iscrowd_new.astype(np.bool))).astype(np.int32) | |||
| if not is_training: | |||
| return _infer_data(image_bgr, image_shape, gt_box_new, gt_label_new, gt_iscrowd_new_revert) | |||
| input_data = image_bgr, image_shape, gt_box_new, gt_label_new, gt_iscrowd_new_revert | |||
| if config.keep_ratio: | |||
| input_data = rescale_column(*input_data) | |||
| else: | |||
| input_data = resize_column(*input_data) | |||
| input_data = image_bgr_rgb(*input_data) | |||
| output_data = input_data | |||
| return output_data | |||
| return _data_aug(image, box, is_training) | |||
| def create_coco_label(is_training): | |||
| """Get image path and annotation from COCO.""" | |||
| from pycocotools.coco import COCO | |||
| coco_root = config.coco_root | |||
| data_type = config.val_data_type | |||
| if is_training: | |||
| data_type = config.train_data_type | |||
| # Classes need to train or test. | |||
| train_cls = config.coco_classes | |||
| train_cls_dict = {} | |||
| for i, cls in enumerate(train_cls): | |||
| train_cls_dict[cls] = i | |||
| anno_json = os.path.join(coco_root, config.instance_set.format(data_type)) | |||
| coco = COCO(anno_json) | |||
| classs_dict = {} | |||
| cat_ids = coco.loadCats(coco.getCatIds()) | |||
| for cat in cat_ids: | |||
| classs_dict[cat["id"]] = cat["name"] | |||
| image_ids = coco.getImgIds() | |||
| image_files = [] | |||
| image_anno_dict = {} | |||
| for img_id in image_ids: | |||
| image_info = coco.loadImgs(img_id) | |||
| file_name = image_info[0]["file_name"] | |||
| anno_ids = coco.getAnnIds(imgIds=img_id, iscrowd=None) | |||
| anno = coco.loadAnns(anno_ids) | |||
| image_path = os.path.join(coco_root, data_type, file_name) | |||
| annos = [] | |||
| for label in anno: | |||
| bbox = label["bbox"] | |||
| class_name = classs_dict[label["category_id"]] | |||
| if class_name in train_cls: | |||
| x1, x2 = bbox[0], bbox[0] + bbox[2] | |||
| y1, y2 = bbox[1], bbox[1] + bbox[3] | |||
| annos.append([x1, y1, x2, y2] + [train_cls_dict[class_name]] + [int(label["iscrowd"])]) | |||
| image_files.append(image_path) | |||
| if annos: | |||
| image_anno_dict[image_path] = np.array(annos) | |||
| else: | |||
| image_anno_dict[image_path] = np.array([0, 0, 0, 0, 0, 1]) | |||
| return image_files, image_anno_dict | |||
| def anno_parser(annos_str): | |||
| """Parse annotation from string to list.""" | |||
| annos = [] | |||
| for anno_str in annos_str: | |||
| anno = list(map(int, anno_str.strip().split(','))) | |||
| annos.append(anno) | |||
| return annos | |||
| def filter_valid_data(image_dir, anno_path): | |||
| """Filter valid image file, which both in image_dir and anno_path.""" | |||
| image_files = [] | |||
| image_anno_dict = {} | |||
| if not os.path.isdir(image_dir): | |||
| raise RuntimeError("Path given is not valid.") | |||
| if not os.path.isfile(anno_path): | |||
| raise RuntimeError("Annotation file is not valid.") | |||
| with open(anno_path, "rb") as f: | |||
| lines = f.readlines() | |||
| for line in lines: | |||
| line_str = line.decode("utf-8").strip() | |||
| line_split = str(line_str).split(' ') | |||
| file_name = line_split[0] | |||
| image_path = os.path.join(image_dir, file_name) | |||
| if os.path.isfile(image_path): | |||
| image_anno_dict[image_path] = anno_parser(line_split[1:]) | |||
| image_files.append(image_path) | |||
| return image_files, image_anno_dict | |||
| def data_to_mindrecord_byte_image(dataset="coco", is_training=True, prefix="fasterrcnn.mindrecord", file_num=8): | |||
| """Create MindRecord file.""" | |||
| mindrecord_dir = config.mindrecord_dir | |||
| mindrecord_path = os.path.join(mindrecord_dir, prefix) | |||
| writer = FileWriter(mindrecord_path, file_num) | |||
| if dataset == "coco": | |||
| image_files, image_anno_dict = create_coco_label(is_training) | |||
| else: | |||
| image_files, image_anno_dict = filter_valid_data(config.IMAGE_DIR, config.ANNO_PATH) | |||
| fasterrcnn_json = { | |||
| "image": {"type": "bytes"}, | |||
| "annotation": {"type": "int32", "shape": [-1, 6]}, | |||
| } | |||
| writer.add_schema(fasterrcnn_json, "fasterrcnn_json") | |||
| for image_name in image_files: | |||
| with open(image_name, 'rb') as f: | |||
| img = f.read() | |||
| annos = np.array(image_anno_dict[image_name], dtype=np.int32) | |||
| row = {"image": img, "annotation": annos} | |||
| writer.write_raw_data([row]) | |||
| writer.commit() | |||
| def create_fasterrcnn_dataset(mindrecord_file, batch_size=2, repeat_num=12, device_num=1, rank_id=0, | |||
| is_training=True, num_parallel_workers=4): | |||
| """Creatr FasterRcnn dataset with MindDataset.""" | |||
| ds = de.MindDataset(mindrecord_file, columns_list=["image", "annotation"], num_shards=device_num, shard_id=rank_id, | |||
| num_parallel_workers=1, shuffle=False) | |||
| decode = C.Decode() | |||
| ds = ds.map(operations=decode, input_columns=["image"], num_parallel_workers=1) | |||
| compose_map_func = (lambda image, annotation: preprocess_fn(image, annotation, is_training)) | |||
| hwc_to_chw = C.HWC2CHW() | |||
| normalize_op = C.Normalize((123.675, 116.28, 103.53), (58.395, 57.12, 57.375)) | |||
| horizontally_op = C.RandomHorizontalFlip(1) | |||
| type_cast0 = CC.TypeCast(mstype.float32) | |||
| type_cast1 = CC.TypeCast(mstype.float16) | |||
| type_cast2 = CC.TypeCast(mstype.int32) | |||
| type_cast3 = CC.TypeCast(mstype.bool_) | |||
| if is_training: | |||
| ds = ds.map(operations=compose_map_func, input_columns=["image", "annotation"], | |||
| output_columns=["image", "image_shape", "box", "label", "valid_num"], | |||
| column_order=["image", "image_shape", "box", "label", "valid_num"], | |||
| num_parallel_workers=num_parallel_workers) | |||
| flip = (np.random.rand() < config.flip_ratio) | |||
| if flip: | |||
| ds = ds.map(operations=[normalize_op, type_cast0], input_columns=["image"], | |||
| num_parallel_workers=12) | |||
| ds = ds.map(operations=flipped_generation, | |||
| input_columns=["image", "image_shape", "box", "label", "valid_num"], | |||
| num_parallel_workers=num_parallel_workers) | |||
| else: | |||
| ds = ds.map(operations=[normalize_op, type_cast0], input_columns=["image"], | |||
| num_parallel_workers=12) | |||
| ds = ds.map(operations=[hwc_to_chw, type_cast1], input_columns=["image"], | |||
| num_parallel_workers=12) | |||
| else: | |||
| ds = ds.map(operations=compose_map_func, | |||
| input_columns=["image", "annotation"], | |||
| output_columns=["image", "image_shape", "box", "label", "valid_num"], | |||
| column_order=["image", "image_shape", "box", "label", "valid_num"], | |||
| num_parallel_workers=num_parallel_workers) | |||
| ds = ds.map(operations=[normalize_op, hwc_to_chw, type_cast1], input_columns=["image"], | |||
| num_parallel_workers=24) | |||
| # transpose_column from python to c | |||
| ds = ds.map(operations=[type_cast1], input_columns=["image_shape"]) | |||
| ds = ds.map(operations=[type_cast1], input_columns=["box"]) | |||
| ds = ds.map(operations=[type_cast2], input_columns=["label"]) | |||
| ds = ds.map(operations=[type_cast3], input_columns=["valid_num"]) | |||
| ds = ds.batch(batch_size, drop_remainder=True) | |||
| ds = ds.repeat(repeat_num) | |||
| return ds | |||
+ 0
- 42
examples/model_security/model_attacks/cv/faster_rcnn/src/lr_schedule.py
View File
| @@ -1,42 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """lr generator for fasterrcnn""" | |||
| import math | |||
| def linear_warmup_learning_rate(current_step, warmup_steps, base_lr, init_lr): | |||
| lr_inc = (float(base_lr) - float(init_lr)) / float(warmup_steps) | |||
| learning_rate = float(init_lr) + lr_inc * current_step | |||
| return learning_rate | |||
| def a_cosine_learning_rate(current_step, base_lr, warmup_steps, decay_steps): | |||
| base = float(current_step - warmup_steps) / float(decay_steps) | |||
| learning_rate = (1 + math.cos(base * math.pi)) / 2 * base_lr | |||
| return learning_rate | |||
| def dynamic_lr(config, rank_size=1): | |||
| """dynamic learning rate generator""" | |||
| base_lr = config.base_lr | |||
| base_step = (config.base_step // rank_size) + rank_size | |||
| total_steps = int(base_step * config.total_epoch) | |||
| warmup_steps = int(config.warmup_step) | |||
| lr = [] | |||
| for i in range(total_steps): | |||
| if i < warmup_steps: | |||
| lr.append(linear_warmup_learning_rate(i, warmup_steps, base_lr, base_lr * config.warmup_ratio)) | |||
| else: | |||
| lr.append(a_cosine_learning_rate(i, base_lr, warmup_steps, total_steps)) | |||
| return lr | |||
+ 0
- 184
examples/model_security/model_attacks/cv/faster_rcnn/src/network_define.py
View File
| @@ -1,184 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """FasterRcnn training network wrapper.""" | |||
| import time | |||
| import numpy as np | |||
| import mindspore.nn as nn | |||
| from mindspore.common.tensor import Tensor | |||
| from mindspore.ops import functional as F | |||
| from mindspore.ops import composite as C | |||
| from mindspore import ParameterTuple | |||
| from mindspore.train.callback import Callback | |||
| from mindspore.nn.wrap.grad_reducer import DistributedGradReducer | |||
| # pylint: disable=locally-disabled, missing-docstring, unused-argument | |||
| time_stamp_init = False | |||
| time_stamp_first = 0 | |||
| class LossCallBack(Callback): | |||
| """ | |||
| Monitor the loss in training. | |||
| If the loss is NAN or INF terminating training. | |||
| Note: | |||
| If per_print_times is 0 do not print loss. | |||
| Args: | |||
| per_print_times (int): Print loss every times. Default: 1. | |||
| """ | |||
| def __init__(self, per_print_times=1, rank_id=0): | |||
| super(LossCallBack, self).__init__() | |||
| if not isinstance(per_print_times, int) or per_print_times < 0: | |||
| raise ValueError("print_step must be int and >= 0.") | |||
| self._per_print_times = per_print_times | |||
| self.count = 0 | |||
| self.rpn_loss_sum = 0 | |||
| self.rcnn_loss_sum = 0 | |||
| self.rpn_cls_loss_sum = 0 | |||
| self.rpn_reg_loss_sum = 0 | |||
| self.rcnn_cls_loss_sum = 0 | |||
| self.rcnn_reg_loss_sum = 0 | |||
| self.rank_id = rank_id | |||
| global time_stamp_init, time_stamp_first | |||
| if not time_stamp_init: | |||
| time_stamp_first = time.time() | |||
| time_stamp_init = True | |||
| def step_end(self, run_context): | |||
| cb_params = run_context.original_args() | |||
| rpn_loss = cb_params.net_outputs[0].asnumpy() | |||
| rcnn_loss = cb_params.net_outputs[1].asnumpy() | |||
| rpn_cls_loss = cb_params.net_outputs[2].asnumpy() | |||
| rpn_reg_loss = cb_params.net_outputs[3].asnumpy() | |||
| rcnn_cls_loss = cb_params.net_outputs[4].asnumpy() | |||
| rcnn_reg_loss = cb_params.net_outputs[5].asnumpy() | |||
| self.count += 1 | |||
| self.rpn_loss_sum += float(rpn_loss) | |||
| self.rcnn_loss_sum += float(rcnn_loss) | |||
| self.rpn_cls_loss_sum += float(rpn_cls_loss) | |||
| self.rpn_reg_loss_sum += float(rpn_reg_loss) | |||
| self.rcnn_cls_loss_sum += float(rcnn_cls_loss) | |||
| self.rcnn_reg_loss_sum += float(rcnn_reg_loss) | |||
| cur_step_in_epoch = (cb_params.cur_step_num - 1) % cb_params.batch_num + 1 | |||
| if self.count >= 1: | |||
| global time_stamp_first | |||
| time_stamp_current = time.time() | |||
| rpn_loss = self.rpn_loss_sum/self.count | |||
| rcnn_loss = self.rcnn_loss_sum/self.count | |||
| rpn_cls_loss = self.rpn_cls_loss_sum/self.count | |||
| rpn_reg_loss = self.rpn_reg_loss_sum/self.count | |||
| rcnn_cls_loss = self.rcnn_cls_loss_sum/self.count | |||
| rcnn_reg_loss = self.rcnn_reg_loss_sum/self.count | |||
| total_loss = rpn_loss + rcnn_loss | |||
| loss_file = open("./loss_{}.log".format(self.rank_id), "a+") | |||
| loss_file.write("%lu epoch: %s step: %s ,rpn_loss: %.5f, rcnn_loss: %.5f, rpn_cls_loss: %.5f, " | |||
| "rpn_reg_loss: %.5f, rcnn_cls_loss: %.5f, rcnn_reg_loss: %.5f, total_loss: %.5f" % | |||
| (time_stamp_current - time_stamp_first, cb_params.cur_epoch_num, cur_step_in_epoch, | |||
| rpn_loss, rcnn_loss, rpn_cls_loss, rpn_reg_loss, | |||
| rcnn_cls_loss, rcnn_reg_loss, total_loss)) | |||
| loss_file.write("\n") | |||
| loss_file.close() | |||
| self.count = 0 | |||
| self.rpn_loss_sum = 0 | |||
| self.rcnn_loss_sum = 0 | |||
| self.rpn_cls_loss_sum = 0 | |||
| self.rpn_reg_loss_sum = 0 | |||
| self.rcnn_cls_loss_sum = 0 | |||
| self.rcnn_reg_loss_sum = 0 | |||
| class LossNet(nn.Cell): | |||
| """FasterRcnn loss method""" | |||
| def construct(self, x1, x2, x3, x4, x5, x6): | |||
| return x1 + x2 | |||
| class WithLossCell(nn.Cell): | |||
| """ | |||
| Wrap the network with loss function to compute loss. | |||
| Args: | |||
| backbone (Cell): The target network to wrap. | |||
| loss_fn (Cell): The loss function used to compute loss. | |||
| """ | |||
| def __init__(self, backbone, loss_fn): | |||
| super(WithLossCell, self).__init__(auto_prefix=False) | |||
| self._backbone = backbone | |||
| self._loss_fn = loss_fn | |||
| def construct(self, x, img_shape, gt_bboxe, gt_label, gt_num): | |||
| loss1, loss2, loss3, loss4, loss5, loss6 = self._backbone(x, img_shape, gt_bboxe, gt_label, gt_num) | |||
| return self._loss_fn(loss1, loss2, loss3, loss4, loss5, loss6) | |||
| @property | |||
| def backbone_network(self): | |||
| """ | |||
| Get the backbone network. | |||
| Returns: | |||
| Cell, return backbone network. | |||
| """ | |||
| return self._backbone | |||
| class TrainOneStepCell(nn.Cell): | |||
| """ | |||
| Network training package class. | |||
| Append an optimizer to the training network after that the construct function | |||
| can be called to create the backward graph. | |||
| Args: | |||
| network (Cell): The training network. | |||
| network_backbone (Cell): The forward network. | |||
| optimizer (Cell): Optimizer for updating the weights. | |||
| sens (Number): The adjust parameter. Default value is 1.0. | |||
| reduce_flag (bool): The reduce flag. Default value is False. | |||
| mean (bool): Allreduce method. Default value is False. | |||
| degree (int): Device number. Default value is None. | |||
| """ | |||
| def __init__(self, network, network_backbone, optimizer, sens=1.0, reduce_flag=False, mean=True, degree=None): | |||
| super(TrainOneStepCell, self).__init__(auto_prefix=False) | |||
| self.network = network | |||
| self.network.set_grad() | |||
| self.backbone = network_backbone | |||
| self.weights = ParameterTuple(network.trainable_params()) | |||
| self.optimizer = optimizer | |||
| self.grad = C.GradOperation(get_by_list=True, | |||
| sens_param=True) | |||
| self.sens = Tensor((np.ones((1,)) * sens).astype(np.float16)) | |||
| self.reduce_flag = reduce_flag | |||
| if reduce_flag: | |||
| self.grad_reducer = DistributedGradReducer(optimizer.parameters, mean, degree) | |||
| def construct(self, x, img_shape, gt_bboxe, gt_label, gt_num): | |||
| weights = self.weights | |||
| loss1, loss2, loss3, loss4, loss5, loss6 = self.backbone(x, img_shape, gt_bboxe, gt_label, gt_num) | |||
| grads = self.grad(self.network, weights)(x, img_shape, gt_bboxe, gt_label, gt_num, self.sens) | |||
| if self.reduce_flag: | |||
| grads = self.grad_reducer(grads) | |||
| return F.depend(loss1, self.optimizer(grads)), loss2, loss3, loss4, loss5, loss6 | |||
+ 0
- 227
examples/model_security/model_attacks/cv/faster_rcnn/src/util.py
View File
| @@ -1,227 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """coco eval for fasterrcnn""" | |||
| import json | |||
| import numpy as np | |||
| from pycocotools.coco import COCO | |||
| from pycocotools.cocoeval import COCOeval | |||
| import mmcv | |||
| # pylint: disable=locally-disabled, invalid-name | |||
| _init_value = np.array(0.0) | |||
| summary_init = { | |||
| 'Precision/mAP': _init_value, | |||
| 'Precision/mAP@.50IOU': _init_value, | |||
| 'Precision/mAP@.75IOU': _init_value, | |||
| 'Precision/mAP (small)': _init_value, | |||
| 'Precision/mAP (medium)': _init_value, | |||
| 'Precision/mAP (large)': _init_value, | |||
| 'Recall/AR@1': _init_value, | |||
| 'Recall/AR@10': _init_value, | |||
| 'Recall/AR@100': _init_value, | |||
| 'Recall/AR@100 (small)': _init_value, | |||
| 'Recall/AR@100 (medium)': _init_value, | |||
| 'Recall/AR@100 (large)': _init_value, | |||
| } | |||
| def coco_eval(result_files, result_types, coco, max_dets=(100, 300, 1000), single_result=False): | |||
| """coco eval for fasterrcnn""" | |||
| anns = json.load(open(result_files['bbox'])) | |||
| if not anns: | |||
| return summary_init | |||
| if mmcv.is_str(coco): | |||
| coco = COCO(coco) | |||
| assert isinstance(coco, COCO) | |||
| for res_type in result_types: | |||
| result_file = result_files[res_type] | |||
| assert result_file.endswith('.json') | |||
| coco_dets = coco.loadRes(result_file) | |||
| gt_img_ids = coco.getImgIds() | |||
| det_img_ids = coco_dets.getImgIds() | |||
| iou_type = 'bbox' if res_type == 'proposal' else res_type | |||
| cocoEval = COCOeval(coco, coco_dets, iou_type) | |||
| if res_type == 'proposal': | |||
| cocoEval.params.useCats = 0 | |||
| cocoEval.params.maxDets = list(max_dets) | |||
| tgt_ids = gt_img_ids if not single_result else det_img_ids | |||
| if single_result: | |||
| res_dict = dict() | |||
| for id_i in tgt_ids: | |||
| cocoEval = COCOeval(coco, coco_dets, iou_type) | |||
| if res_type == 'proposal': | |||
| cocoEval.params.useCats = 0 | |||
| cocoEval.params.maxDets = list(max_dets) | |||
| cocoEval.params.imgIds = [id_i] | |||
| cocoEval.evaluate() | |||
| cocoEval.accumulate() | |||
| cocoEval.summarize() | |||
| res_dict.update({coco.imgs[id_i]['file_name']: cocoEval.stats[1]}) | |||
| cocoEval = COCOeval(coco, coco_dets, iou_type) | |||
| if res_type == 'proposal': | |||
| cocoEval.params.useCats = 0 | |||
| cocoEval.params.maxDets = list(max_dets) | |||
| cocoEval.params.imgIds = tgt_ids | |||
| cocoEval.evaluate() | |||
| cocoEval.accumulate() | |||
| cocoEval.summarize() | |||
| summary_metrics = { | |||
| 'Precision/mAP': cocoEval.stats[0], | |||
| 'Precision/mAP@.50IOU': cocoEval.stats[1], | |||
| 'Precision/mAP@.75IOU': cocoEval.stats[2], | |||
| 'Precision/mAP (small)': cocoEval.stats[3], | |||
| 'Precision/mAP (medium)': cocoEval.stats[4], | |||
| 'Precision/mAP (large)': cocoEval.stats[5], | |||
| 'Recall/AR@1': cocoEval.stats[6], | |||
| 'Recall/AR@10': cocoEval.stats[7], | |||
| 'Recall/AR@100': cocoEval.stats[8], | |||
| 'Recall/AR@100 (small)': cocoEval.stats[9], | |||
| 'Recall/AR@100 (medium)': cocoEval.stats[10], | |||
| 'Recall/AR@100 (large)': cocoEval.stats[11], | |||
| } | |||
| return summary_metrics | |||
| def xyxy2xywh(bbox): | |||
| _bbox = bbox.tolist() | |||
| return [ | |||
| _bbox[0], | |||
| _bbox[1], | |||
| _bbox[2] - _bbox[0] + 1, | |||
| _bbox[3] - _bbox[1] + 1, | |||
| ] | |||
| def bbox2result_1image(bboxes, labels, num_classes): | |||
| """Convert detection results to a list of numpy arrays. | |||
| Args: | |||
| bboxes (Tensor): shape (n, 5) | |||
| labels (Tensor): shape (n, ) | |||
| num_classes (int): class number, including background class | |||
| Returns: | |||
| list(ndarray): bbox results of each class | |||
| """ | |||
| if bboxes.shape[0] == 0: | |||
| result = [np.zeros((0, 5), dtype=np.float32) for i in range(num_classes - 1)] | |||
| else: | |||
| result = [bboxes[labels == i, :] for i in range(num_classes - 1)] | |||
| return result | |||
| def proposal2json(dataset, results): | |||
| """convert proposal to json mode""" | |||
| img_ids = dataset.getImgIds() | |||
| json_results = [] | |||
| dataset_len = dataset.get_dataset_size()*2 | |||
| for idx in range(dataset_len): | |||
| img_id = img_ids[idx] | |||
| bboxes = results[idx] | |||
| for i in range(bboxes.shape[0]): | |||
| data = dict() | |||
| data['image_id'] = img_id | |||
| data['bbox'] = xyxy2xywh(bboxes[i]) | |||
| data['score'] = float(bboxes[i][4]) | |||
| data['category_id'] = 1 | |||
| json_results.append(data) | |||
| return json_results | |||
| def det2json(dataset, results): | |||
| """convert det to json mode""" | |||
| cat_ids = dataset.getCatIds() | |||
| img_ids = dataset.getImgIds() | |||
| json_results = [] | |||
| dataset_len = len(img_ids) | |||
| for idx in range(dataset_len): | |||
| img_id = img_ids[idx] | |||
| if idx == len(results): break | |||
| result = results[idx] | |||
| for label, result_label in enumerate(result): | |||
| bboxes = result_label | |||
| for i in range(bboxes.shape[0]): | |||
| data = dict() | |||
| data['image_id'] = img_id | |||
| data['bbox'] = xyxy2xywh(bboxes[i]) | |||
| data['score'] = float(bboxes[i][4]) | |||
| data['category_id'] = cat_ids[label] | |||
| json_results.append(data) | |||
| return json_results | |||
| def segm2json(dataset, results): | |||
| """convert segm to json mode""" | |||
| bbox_json_results = [] | |||
| segm_json_results = [] | |||
| for idx in range(len(dataset)): | |||
| img_id = dataset.img_ids[idx] | |||
| det, seg = results[idx] | |||
| for label, det_label in enumerate(det): | |||
| # bbox results | |||
| bboxes = det_label | |||
| for i in range(bboxes.shape[0]): | |||
| data = dict() | |||
| data['image_id'] = img_id | |||
| data['bbox'] = xyxy2xywh(bboxes[i]) | |||
| data['score'] = float(bboxes[i][4]) | |||
| data['category_id'] = dataset.cat_ids[label] | |||
| bbox_json_results.append(data) | |||
| if len(seg) == 2: | |||
| segms = seg[0][label] | |||
| mask_score = seg[1][label] | |||
| else: | |||
| segms = seg[label] | |||
| mask_score = [bbox[4] for bbox in bboxes] | |||
| for i in range(bboxes.shape[0]): | |||
| data = dict() | |||
| data['image_id'] = img_id | |||
| data['score'] = float(mask_score[i]) | |||
| data['category_id'] = dataset.cat_ids[label] | |||
| segms[i]['counts'] = segms[i]['counts'].decode() | |||
| data['segmentation'] = segms[i] | |||
| segm_json_results.append(data) | |||
| return bbox_json_results, segm_json_results | |||
| def results2json(dataset, results, out_file): | |||
| """convert result convert to json mode""" | |||
| result_files = dict() | |||
| if isinstance(results[0], list): | |||
| json_results = det2json(dataset, results) | |||
| result_files['bbox'] = '{}.{}.json'.format(out_file, 'bbox') | |||
| result_files['proposal'] = '{}.{}.json'.format(out_file, 'bbox') | |||
| mmcv.dump(json_results, result_files['bbox']) | |||
| elif isinstance(results[0], tuple): | |||
| json_results = segm2json(dataset, results) | |||
| result_files['bbox'] = '{}.{}.json'.format(out_file, 'bbox') | |||
| result_files['proposal'] = '{}.{}.json'.format(out_file, 'bbox') | |||
| result_files['segm'] = '{}.{}.json'.format(out_file, 'segm') | |||
| mmcv.dump(json_results[0], result_files['bbox']) | |||
| mmcv.dump(json_results[1], result_files['segm']) | |||
| elif isinstance(results[0], np.ndarray): | |||
| json_results = proposal2json(dataset, results) | |||
| result_files['proposal'] = '{}.{}.json'.format(out_file, 'proposal') | |||
| mmcv.dump(json_results, result_files['proposal']) | |||
| else: | |||
| raise TypeError('invalid type of results') | |||
| return result_files | |||
+ 0
- 154
examples/model_security/model_attacks/cv/yolov3_darknet53/coco_attack_deepfool.py
View File
| @@ -1,154 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Generate adversarial example for yolov3_darknet53 by DeepFool""" | |||
| import os | |||
| import argparse | |||
| import datetime | |||
| import numpy as np | |||
| from mindspore import Tensor | |||
| from mindspore.nn import Cell | |||
| from mindspore.ops import operations as P | |||
| from mindspore.context import ParallelMode | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| import mindspore as ms | |||
| from mindarmour.adv_robustness.attacks import DeepFool | |||
| from src.yolo import YOLOV3DarkNet53 | |||
| from src.logger import get_logger | |||
| from src.yolo_dataset import create_yolo_dataset | |||
| from src.config import ConfigYOLOV3DarkNet53 | |||
| def parse_args(): | |||
| """Parse arguments.""" | |||
| parser = argparse.ArgumentParser('mindspore coco testing') | |||
| # device related | |||
| parser.add_argument('--data_dir', type=str, default='', help='train data dir') | |||
| parser.add_argument('--pretrained', default='', type=str, help='model_path, local pretrained model to load') | |||
| parser.add_argument('--samples_num', default=1, type=int, help='Number of sample to be generated.') | |||
| parser.add_argument('--log_path', type=str, default='outputs/', help='checkpoint save location') | |||
| parser.add_argument('--testing_shape', type=str, default='', help='shape for test ') | |||
| args, _ = parser.parse_known_args() | |||
| args.data_root = os.path.join(args.data_dir, 'val2014') | |||
| args.annFile = os.path.join(args.data_dir, 'annotations/instances_val2014.json') | |||
| return args | |||
| def conver_testing_shape(args): | |||
| """Convert testing shape to list.""" | |||
| testing_shape = [int(args.testing_shape), int(args.testing_shape)] | |||
| return testing_shape | |||
| class SolveOutput(Cell): | |||
| """Solve output of the target network to adapt DeepFool.""" | |||
| def __init__(self, network): | |||
| super(SolveOutput, self).__init__() | |||
| self._network = network | |||
| self._reshape = P.Reshape() | |||
| def construct(self, image, input_shape): | |||
| prediction = self._network(image, input_shape) | |||
| output_big = prediction[0] | |||
| output_big = self._reshape(output_big, (output_big.shape[0], -1, 85)) | |||
| output_big_boxes = output_big[:, :, 0: 5] | |||
| output_big_logits = output_big[:, :, 5:] | |||
| return output_big_boxes, output_big_logits | |||
| def test(): | |||
| """The function of eval.""" | |||
| args = parse_args() | |||
| devid = int(os.getenv('DEVICE_ID')) if os.getenv('DEVICE_ID') else 0 | |||
| context.set_context(mode=context.GRAPH_MODE, device_target='Ascend', save_graphs=True, device_id=devid) | |||
| # logger | |||
| args.outputs_dir = os.path.join(args.log_path, | |||
| datetime.datetime.now().strftime('%Y-%m-%d_time_%H_%M_%S')) | |||
| rank_id = int(os.environ.get('RANK_ID')) if os.environ.get('RANK_ID') else 0 | |||
| args.logger = get_logger(args.outputs_dir, rank_id) | |||
| context.reset_auto_parallel_context() | |||
| parallel_mode = ParallelMode.STAND_ALONE | |||
| context.set_auto_parallel_context(parallel_mode=parallel_mode, gradients_mean=True, device_num=1) | |||
| args.logger.info('Creating Network....') | |||
| network = SolveOutput(YOLOV3DarkNet53(is_training=False)) | |||
| data_root = args.data_root | |||
| ann_file = args.annFile | |||
| args.logger.info(args.pretrained) | |||
| if os.path.isfile(args.pretrained): | |||
| param_dict = load_checkpoint(args.pretrained) | |||
| param_dict_new = {} | |||
| for key, values in param_dict.items(): | |||
| if key.startswith('moments.'): | |||
| continue | |||
| elif key.startswith('yolo_network.'): | |||
| param_dict_new[key[13:]] = values | |||
| else: | |||
| param_dict_new[key] = values | |||
| load_param_into_net(network, param_dict_new) | |||
| args.logger.info('load_model {} success'.format(args.pretrained)) | |||
| else: | |||
| args.logger.info('{} not exists or not a pre-trained file'.format(args.pretrained)) | |||
| assert FileNotFoundError('{} not exists or not a pre-trained file'.format(args.pretrained)) | |||
| exit(1) | |||
| config = ConfigYOLOV3DarkNet53() | |||
| if args.testing_shape: | |||
| config.test_img_shape = conver_testing_shape(args) | |||
| ds, data_size = create_yolo_dataset(data_root, ann_file, is_training=False, batch_size=1, | |||
| max_epoch=1, device_num=1, rank=rank_id, shuffle=False, | |||
| config=config) | |||
| args.logger.info('testing shape : {}'.format(config.test_img_shape)) | |||
| args.logger.info('totol {} images to eval'.format(data_size)) | |||
| network.set_train(False) | |||
| # build attacker | |||
| attack = DeepFool(network, num_classes=80, model_type='detection', reserve_ratio=0.9, bounds=(0, 1)) | |||
| input_shape = Tensor(tuple(config.test_img_shape), ms.float32) | |||
| args.logger.info('Start inference....') | |||
| batch_num = args.samples_num | |||
| adv_example = [] | |||
| for i, data in enumerate(ds.create_dict_iterator(num_epochs=1)): | |||
| if i >= batch_num: | |||
| break | |||
| image = data["image"] | |||
| image_shape = data["image_shape"] | |||
| gt_boxes, gt_logits = network(image, input_shape) | |||
| gt_boxes, gt_logits = gt_boxes.asnumpy(), gt_logits.asnumpy() | |||
| gt_labels = np.argmax(gt_logits, axis=2) | |||
| adv_img = attack.generate((image.asnumpy(), image_shape.asnumpy()), (gt_boxes, gt_labels)) | |||
| adv_example.append(adv_img) | |||
| np.save('adv_example.npy', adv_example) | |||
| if __name__ == "__main__": | |||
| test() | |||
+ 0
- 14
examples/model_security/model_attacks/cv/yolov3_darknet53/src/__init__.py
View File
| @@ -1,14 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
+ 0
- 68
examples/model_security/model_attacks/cv/yolov3_darknet53/src/config.py
View File
| @@ -1,68 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Config parameters for Darknet based yolov3_darknet53 models.""" | |||
| class ConfigYOLOV3DarkNet53: | |||
| """ | |||
| Config parameters for the yolov3_darknet53. | |||
| Examples: | |||
| ConfigYOLOV3DarkNet53() | |||
| """ | |||
| # train_param | |||
| # data augmentation related | |||
| hue = 0.1 | |||
| saturation = 1.5 | |||
| value = 1.5 | |||
| jitter = 0.3 | |||
| resize_rate = 1 | |||
| multi_scale = [[320, 320], | |||
| [352, 352], | |||
| [384, 384], | |||
| [416, 416], | |||
| [448, 448], | |||
| [480, 480], | |||
| [512, 512], | |||
| [544, 544], | |||
| [576, 576], | |||
| [608, 608] | |||
| ] | |||
| num_classes = 80 | |||
| max_box = 50 | |||
| backbone_input_shape = [32, 64, 128, 256, 512] | |||
| backbone_shape = [64, 128, 256, 512, 1024] | |||
| backbone_layers = [1, 2, 8, 8, 4] | |||
| # confidence under ignore_threshold means no object when training | |||
| ignore_threshold = 0.7 | |||
| # h->w | |||
| anchor_scales = [(10, 13), | |||
| (16, 30), | |||
| (33, 23), | |||
| (30, 61), | |||
| (62, 45), | |||
| (59, 119), | |||
| (116, 90), | |||
| (156, 198), | |||
| (373, 326)] | |||
| out_channel = 255 | |||
| # test_param | |||
| test_img_shape = [416, 416] | |||
+ 0
- 80
examples/model_security/model_attacks/cv/yolov3_darknet53/src/convert_weight.py
View File
| @@ -1,80 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Convert weight to mindspore ckpt.""" | |||
| import os | |||
| import argparse | |||
| import numpy as np | |||
| from mindspore.train.serialization import save_checkpoint | |||
| from mindspore import Tensor | |||
| from src.yolo import YOLOV3DarkNet53 | |||
| def load_weight(weights_file): | |||
| """Loads pre-trained weights.""" | |||
| if not os.path.isfile(weights_file): | |||
| raise ValueError(f'"{weights_file}" is not a valid weight file.') | |||
| with open(weights_file, 'rb') as fp: | |||
| np.fromfile(fp, dtype=np.int32, count=5) | |||
| return np.fromfile(fp, dtype=np.float32) | |||
| def build_network(): | |||
| """Build YOLOv3 network.""" | |||
| network = YOLOV3DarkNet53(is_training=True) | |||
| params = network.get_parameters() | |||
| params = [p for p in params if 'backbone' in p.name] | |||
| return params | |||
| def convert(weights_file, output_file): | |||
| """Conver weight to mindspore ckpt.""" | |||
| params = build_network() | |||
| weights = load_weight(weights_file) | |||
| index = 0 | |||
| param_list = [] | |||
| for i in range(0, len(params), 5): | |||
| weight = params[i] | |||
| mean = params[i+1] | |||
| var = params[i+2] | |||
| gamma = params[i+3] | |||
| beta = params[i+4] | |||
| beta_data = weights[index: index+beta.size()].reshape(beta.shape) | |||
| index += beta.size() | |||
| gamma_data = weights[index: index+gamma.size()].reshape(gamma.shape) | |||
| index += gamma.size() | |||
| mean_data = weights[index: index+mean.size()].reshape(mean.shape) | |||
| index += mean.size() | |||
| var_data = weights[index: index + var.size()].reshape(var.shape) | |||
| index += var.size() | |||
| weight_data = weights[index: index+weight.size()].reshape(weight.shape) | |||
| index += weight.size() | |||
| param_list.append({'name': weight.name, 'type': weight.dtype, 'shape': weight.shape, | |||
| 'data': Tensor(weight_data)}) | |||
| param_list.append({'name': mean.name, 'type': mean.dtype, 'shape': mean.shape, 'data': Tensor(mean_data)}) | |||
| param_list.append({'name': var.name, 'type': var.dtype, 'shape': var.shape, 'data': Tensor(var_data)}) | |||
| param_list.append({'name': gamma.name, 'type': gamma.dtype, 'shape': gamma.shape, 'data': Tensor(gamma_data)}) | |||
| param_list.append({'name': beta.name, 'type': beta.dtype, 'shape': beta.shape, 'data': Tensor(beta_data)}) | |||
| save_checkpoint(param_list, output_file) | |||
| if __name__ == "__main__": | |||
| parser = argparse.ArgumentParser(description="yolov3 weight convert.") | |||
| parser.add_argument("--input_file", type=str, default="./darknet53.conv.74", help="input file path.") | |||
| parser.add_argument("--output_file", type=str, default="./ackbone_darknet53.ckpt", help="output file path.") | |||
| args_opt = parser.parse_args() | |||
| convert(args_opt.input_file, args_opt.output_file) | |||
+ 0
- 212
examples/model_security/model_attacks/cv/yolov3_darknet53/src/darknet.py
View File
| @@ -1,212 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """DarkNet model.""" | |||
| import mindspore.nn as nn | |||
| from mindspore.ops import operations as P | |||
| # pylint: disable=locally-disables, missing-docstring | |||
| def conv_block(in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride, | |||
| dilation=1): | |||
| """Get a conv2d batchnorm and relu layer""" | |||
| pad_mode = 'same' | |||
| padding = 0 | |||
| return nn.SequentialCell( | |||
| [nn.Conv2d(in_channels, | |||
| out_channels, | |||
| kernel_size=kernel_size, | |||
| stride=stride, | |||
| padding=padding, | |||
| dilation=dilation, | |||
| pad_mode=pad_mode), | |||
| nn.BatchNorm2d(out_channels, momentum=0.1), | |||
| nn.ReLU()] | |||
| ) | |||
| class ResidualBlock(nn.Cell): | |||
| """ | |||
| DarkNet V1 residual block definition. | |||
| Args: | |||
| in_channels: Integer. Input channel. | |||
| out_channels: Integer. Output channel. | |||
| Returns: | |||
| Tensor, output tensor. | |||
| Examples: | |||
| ResidualBlock(3, 208) | |||
| """ | |||
| expansion = 4 | |||
| def __init__(self, | |||
| in_channels, | |||
| out_channels): | |||
| super(ResidualBlock, self).__init__() | |||
| out_chls = out_channels//2 | |||
| self.conv1 = conv_block(in_channels, out_chls, kernel_size=1, stride=1) | |||
| self.conv2 = conv_block(out_chls, out_channels, kernel_size=3, stride=1) | |||
| self.add = P.Add() | |||
| def construct(self, x): | |||
| identity = x | |||
| out = self.conv1(x) | |||
| out = self.conv2(out) | |||
| out = self.add(out, identity) | |||
| return out | |||
| class DarkNet(nn.Cell): | |||
| """ | |||
| DarkNet V1 network. | |||
| Args: | |||
| block: Cell. Block for network. | |||
| layer_nums: List. Numbers of different layers. | |||
| in_channels: Integer. Input channel. | |||
| out_channels: Integer. Output channel. | |||
| detect: Bool. Whether detect or not. Default:False. | |||
| Returns: | |||
| Tuple, tuple of output tensor,(f1,f2,f3,f4,f5). | |||
| Examples: | |||
| DarkNet(ResidualBlock, | |||
| [1, 2, 8, 8, 4], | |||
| [32, 64, 128, 256, 512], | |||
| [64, 128, 256, 512, 1024], | |||
| 100) | |||
| """ | |||
| def __init__(self, | |||
| block, | |||
| layer_nums, | |||
| in_channels, | |||
| out_channels, | |||
| detect=False): | |||
| super(DarkNet, self).__init__() | |||
| self.outchannel = out_channels[-1] | |||
| self.detect = detect | |||
| if not len(layer_nums) == len(in_channels) == len(out_channels) == 5: | |||
| raise ValueError("the length of layer_num, inchannel, outchannel list must be 5!") | |||
| self.conv0 = conv_block(3, | |||
| in_channels[0], | |||
| kernel_size=3, | |||
| stride=1) | |||
| self.conv1 = conv_block(in_channels[0], | |||
| out_channels[0], | |||
| kernel_size=3, | |||
| stride=2) | |||
| self.layer1 = self._make_layer(block, | |||
| layer_nums[0], | |||
| in_channel=out_channels[0], | |||
| out_channel=out_channels[0]) | |||
| self.conv2 = conv_block(in_channels[1], | |||
| out_channels[1], | |||
| kernel_size=3, | |||
| stride=2) | |||
| self.layer2 = self._make_layer(block, | |||
| layer_nums[1], | |||
| in_channel=out_channels[1], | |||
| out_channel=out_channels[1]) | |||
| self.conv3 = conv_block(in_channels[2], | |||
| out_channels[2], | |||
| kernel_size=3, | |||
| stride=2) | |||
| self.layer3 = self._make_layer(block, | |||
| layer_nums[2], | |||
| in_channel=out_channels[2], | |||
| out_channel=out_channels[2]) | |||
| self.conv4 = conv_block(in_channels[3], | |||
| out_channels[3], | |||
| kernel_size=3, | |||
| stride=2) | |||
| self.layer4 = self._make_layer(block, | |||
| layer_nums[3], | |||
| in_channel=out_channels[3], | |||
| out_channel=out_channels[3]) | |||
| self.conv5 = conv_block(in_channels[4], | |||
| out_channels[4], | |||
| kernel_size=3, | |||
| stride=2) | |||
| self.layer5 = self._make_layer(block, | |||
| layer_nums[4], | |||
| in_channel=out_channels[4], | |||
| out_channel=out_channels[4]) | |||
| def _make_layer(self, block, layer_num, in_channel, out_channel): | |||
| """ | |||
| Make Layer for DarkNet. | |||
| :param block: Cell. DarkNet block. | |||
| :param layer_num: Integer. Layer number. | |||
| :param in_channel: Integer. Input channel. | |||
| :param out_channel: Integer. Output channel. | |||
| Examples: | |||
| _make_layer(ConvBlock, 1, 128, 256) | |||
| """ | |||
| layers = [] | |||
| darkblk = block(in_channel, out_channel) | |||
| layers.append(darkblk) | |||
| for _ in range(1, layer_num): | |||
| darkblk = block(out_channel, out_channel) | |||
| layers.append(darkblk) | |||
| return nn.SequentialCell(layers) | |||
| def construct(self, x): | |||
| c1 = self.conv0(x) | |||
| c2 = self.conv1(c1) | |||
| c3 = self.layer1(c2) | |||
| c4 = self.conv2(c3) | |||
| c5 = self.layer2(c4) | |||
| c6 = self.conv3(c5) | |||
| c7 = self.layer3(c6) | |||
| c8 = self.conv4(c7) | |||
| c9 = self.layer4(c8) | |||
| c10 = self.conv5(c9) | |||
| c11 = self.layer5(c10) | |||
| if self.detect: | |||
| return c7, c9, c11 | |||
| return c11 | |||
| def get_out_channels(self): | |||
| return self.outchannel | |||
| def darknet53(): | |||
| """ | |||
| Get DarkNet53 neural network. | |||
| Returns: | |||
| Cell, cell instance of DarkNet53 neural network. | |||
| Examples: | |||
| darknet53() | |||
| """ | |||
| return DarkNet(ResidualBlock, [1, 2, 8, 8, 4], | |||
| [32, 64, 128, 256, 512], | |||
| [64, 128, 256, 512, 1024]) | |||
+ 0
- 60
examples/model_security/model_attacks/cv/yolov3_darknet53/src/distributed_sampler.py
View File
| @@ -1,60 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Yolo dataset distributed sampler.""" | |||
| from __future__ import division | |||
| import math | |||
| import numpy as np | |||
| class DistributedSampler: | |||
| """Distributed sampler.""" | |||
| def __init__(self, dataset_size, num_replicas=None, rank=None, shuffle=True): | |||
| if num_replicas is None: | |||
| print("***********Setting world_size to 1 since it is not passed in ******************") | |||
| num_replicas = 1 | |||
| if rank is None: | |||
| print("***********Setting rank to 0 since it is not passed in ******************") | |||
| rank = 0 | |||
| self.dataset_size = dataset_size | |||
| self.num_replicas = num_replicas | |||
| self.rank = rank | |||
| self.epoch = 0 | |||
| self.num_samples = int(math.ceil(dataset_size * 1.0 / self.num_replicas)) | |||
| self.total_size = self.num_samples * self.num_replicas | |||
| self.shuffle = shuffle | |||
| def __iter__(self): | |||
| # deterministically shuffle based on epoch | |||
| if self.shuffle: | |||
| indices = np.random.RandomState(seed=self.epoch).permutation(self.dataset_size) | |||
| # np.array type. number from 0 to len(dataset_size)-1, used as index of dataset | |||
| indices = indices.tolist() | |||
| self.epoch += 1 | |||
| # change to list type | |||
| else: | |||
| indices = list(range(self.dataset_size)) | |||
| # add extra samples to make it evenly divisible | |||
| indices += indices[:(self.total_size - len(indices))] | |||
| assert len(indices) == self.total_size | |||
| # subsample | |||
| indices = indices[self.rank:self.total_size:self.num_replicas] | |||
| assert len(indices) == self.num_samples | |||
| return iter(indices) | |||
| def __len__(self): | |||
| return self.num_samples | |||
+ 0
- 204
examples/model_security/model_attacks/cv/yolov3_darknet53/src/initializer.py
View File
| @@ -1,204 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Parameter init.""" | |||
| import math | |||
| from functools import reduce | |||
| import numpy as np | |||
| from mindspore.common import initializer as init | |||
| from mindspore.common.initializer import Initializer as MeInitializer | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| import mindspore.nn as nn | |||
| from .util import load_backbone | |||
| def calculate_gain(nonlinearity, param=None): | |||
| r"""Return the recommended gain value for the given nonlinearity function. | |||
| The values are as follows: | |||
| ================= ==================================================== | |||
| nonlinearity gain | |||
| ================= ==================================================== | |||
| Linear / Identity :math:`1` | |||
| Conv{1,2,3}D :math:`1` | |||
| Sigmoid :math:`1` | |||
| Tanh :math:`\frac{5}{3}` | |||
| ReLU :math:`\sqrt{2}` | |||
| Leaky Relu :math:`\sqrt{\frac{2}{1 + \text{negative\_slope}^2}}` | |||
| ================= ==================================================== | |||
| Args: | |||
| nonlinearity: the non-linear function (`nn.functional` name) | |||
| param: optional parameter for the non-linear function | |||
| Examples: | |||
| >>> gain = nn.init.calculate_gain('leaky_relu', 0.2) # leaky_relu with negative_slope=0.2 | |||
| """ | |||
| linear_fns = ['linear', 'conv1d', 'conv2d', 'conv3d', 'conv_transpose1d', 'conv_transpose2d', 'conv_transpose3d'] | |||
| if nonlinearity in linear_fns or nonlinearity == 'sigmoid': | |||
| return 1 | |||
| if nonlinearity == 'tanh': | |||
| return 5.0 / 3 | |||
| if nonlinearity == 'relu': | |||
| return math.sqrt(2.0) | |||
| if nonlinearity == 'leaky_relu': | |||
| if param is None: | |||
| negative_slope = 0.01 | |||
| elif not isinstance(param, bool) and isinstance(param, int) or isinstance(param, float): | |||
| # True/False are instances of int, hence check above | |||
| negative_slope = param | |||
| else: | |||
| raise ValueError("negative_slope {} not a valid number".format(param)) | |||
| return math.sqrt(2.0 / (1 + negative_slope ** 2)) | |||
| raise ValueError("Unsupported nonlinearity {}".format(nonlinearity)) | |||
| def _assignment(arr, num): | |||
| """Assign the value of 'num' and 'arr'.""" | |||
| if arr.shape == (): | |||
| arr = arr.reshape((1)) | |||
| arr[:] = num | |||
| arr = arr.reshape(()) | |||
| else: | |||
| if isinstance(num, np.ndarray): | |||
| arr[:] = num[:] | |||
| else: | |||
| arr[:] = num | |||
| return arr | |||
| def _calculate_correct_fan(array, mode): | |||
| mode = mode.lower() | |||
| valid_modes = ['fan_in', 'fan_out'] | |||
| if mode not in valid_modes: | |||
| raise ValueError("Mode {} not supported, please use one of {}".format(mode, valid_modes)) | |||
| fan_in, fan_out = _calculate_fan_in_and_fan_out(array) | |||
| return fan_in if mode == 'fan_in' else fan_out | |||
| def kaiming_uniform_(arr, a=0, mode='fan_in', nonlinearity='leaky_relu'): | |||
| r"""Fills the input `Tensor` with values according to the method | |||
| described in `Delving deep into rectifiers: Surpassing human-level | |||
| performance on ImageNet classification` - He, K. et al. (2015), using a | |||
| uniform distribution. The resulting tensor will have values sampled from | |||
| :math:`\mathcal{U}(-\text{bound}, \text{bound})` where | |||
| .. math:: | |||
| \text{bound} = \text{gain} \times \sqrt{\frac{3}{\text{fan\_mode}}} | |||
| Also known as He initialization. | |||
| Args: | |||
| tensor: an n-dimensional `Tensor` | |||
| a: the negative slope of the rectifier used after this layer (only | |||
| used with ``'leaky_relu'``) | |||
| mode: either ``'fan_in'`` (default) or ``'fan_out'``. Choosing ``'fan_in'`` | |||
| preserves the magnitude of the variance of the weights in the | |||
| forward pass. Choosing ``'fan_out'`` preserves the magnitudes in the | |||
| backwards pass. | |||
| nonlinearity: the non-linear function (`nn.functional` name), | |||
| recommended to use only with ``'relu'`` or ``'leaky_relu'`` (default). | |||
| Examples: | |||
| >>> w = np.empty(3, 5) | |||
| >>> nn.init.kaiming_uniform_(w, mode='fan_in', nonlinearity='relu') | |||
| """ | |||
| fan = _calculate_correct_fan(arr, mode) | |||
| gain = calculate_gain(nonlinearity, a) | |||
| std = gain / math.sqrt(fan) | |||
| bound = math.sqrt(3.0) * std # Calculate uniform bounds from standard deviation | |||
| return np.random.uniform(-bound, bound, arr.shape) | |||
| def _calculate_fan_in_and_fan_out(arr): | |||
| """Calculate fan in and fan out.""" | |||
| dimensions = len(arr.shape) | |||
| if dimensions < 2: | |||
| raise ValueError("Fan in and fan out can not be computed for array with fewer than 2 dimensions") | |||
| num_input_fmaps = arr.shape[1] | |||
| num_output_fmaps = arr.shape[0] | |||
| receptive_field_size = 1 | |||
| if dimensions > 2: | |||
| receptive_field_size = reduce(lambda x, y: x * y, arr.shape[2:]) | |||
| fan_in = num_input_fmaps * receptive_field_size | |||
| fan_out = num_output_fmaps * receptive_field_size | |||
| return fan_in, fan_out | |||
| class KaimingUniform(MeInitializer): | |||
| """Kaiming uniform initializer.""" | |||
| def __init__(self, a=0, mode='fan_in', nonlinearity='leaky_relu'): | |||
| super(KaimingUniform, self).__init__() | |||
| self.a = a | |||
| self.mode = mode | |||
| self.nonlinearity = nonlinearity | |||
| def _initialize(self, arr): | |||
| tmp = kaiming_uniform_(arr, self.a, self.mode, self.nonlinearity) | |||
| _assignment(arr, tmp) | |||
| def default_recurisive_init(custom_cell): | |||
| """Initialize parameter.""" | |||
| for _, cell in custom_cell.cells_and_names(): | |||
| if isinstance(cell, nn.Conv2d): | |||
| cell.weight.set_data(init.initializer(KaimingUniform(a=math.sqrt(5)), | |||
| cell.weight.shape, | |||
| cell.weight.dtype)) | |||
| if cell.bias is not None: | |||
| fan_in, _ = _calculate_fan_in_and_fan_out(cell.weight) | |||
| bound = 1 / math.sqrt(fan_in) | |||
| cell.bias.set_data(init.initializer(init.Uniform(bound), | |||
| cell.bias.shape, | |||
| cell.bias.dtype)) | |||
| elif isinstance(cell, nn.Dense): | |||
| cell.weight.set_data(init.initializer(KaimingUniform(a=math.sqrt(5)), | |||
| cell.weight.shape, | |||
| cell.weight.dtype)) | |||
| if cell.bias is not None: | |||
| fan_in, _ = _calculate_fan_in_and_fan_out(cell.weight) | |||
| bound = 1 / math.sqrt(fan_in) | |||
| cell.bias.set_data(init.initializer(init.Uniform(bound), | |||
| cell.bias.shape, | |||
| cell.bias.dtype)) | |||
| elif isinstance(cell, (nn.BatchNorm2d, nn.BatchNorm1d)): | |||
| pass | |||
| def load_yolov3_params(args, network): | |||
| """Load yolov3 darknet parameter from checkpoint.""" | |||
| if args.pretrained_backbone: | |||
| network = load_backbone(network, args.pretrained_backbone, args) | |||
| args.logger.info('load pre-trained backbone {} into network'.format(args.pretrained_backbone)) | |||
| else: | |||
| args.logger.info('Not load pre-trained backbone, please be careful') | |||
| if args.resume_yolov3: | |||
| param_dict = load_checkpoint(args.resume_yolov3) | |||
| param_dict_new = {} | |||
| for key, values in param_dict.items(): | |||
| if key.startswith('moments.'): | |||
| continue | |||
| elif key.startswith('yolo_network.'): | |||
| param_dict_new[key[13:]] = values | |||
| args.logger.info('in resume {}'.format(key)) | |||
| else: | |||
| param_dict_new[key] = values | |||
| args.logger.info('in resume {}'.format(key)) | |||
| args.logger.info('resume finished') | |||
| load_param_into_net(network, param_dict_new) | |||
| args.logger.info('load_model {} success'.format(args.resume_yolov3)) | |||
+ 0
- 80
examples/model_security/model_attacks/cv/yolov3_darknet53/src/logger.py
View File
| @@ -1,80 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Custom Logger.""" | |||
| import os | |||
| import sys | |||
| import logging | |||
| from datetime import datetime | |||
| class LOGGER(logging.Logger): | |||
| """ | |||
| Logger. | |||
| Args: | |||
| logger_name: String. Logger name. | |||
| rank: Integer. Rank id. | |||
| """ | |||
| def __init__(self, logger_name, rank=0): | |||
| super(LOGGER, self).__init__(logger_name) | |||
| self.rank = rank | |||
| if rank % 8 == 0: | |||
| console = logging.StreamHandler(sys.stdout) | |||
| console.setLevel(logging.INFO) | |||
| formatter = logging.Formatter('%(asctime)s:%(levelname)s:%(message)s') | |||
| console.setFormatter(formatter) | |||
| self.addHandler(console) | |||
| def setup_logging_file(self, log_dir, rank=0): | |||
| """Setup logging file.""" | |||
| self.rank = rank | |||
| if not os.path.exists(log_dir): | |||
| os.makedirs(log_dir, exist_ok=True) | |||
| log_name = datetime.now().strftime('%Y-%m-%d_time_%H_%M_%S') + '_rank_{}.log'.format(rank) | |||
| self.log_fn = os.path.join(log_dir, log_name) | |||
| fh = logging.FileHandler(self.log_fn) | |||
| fh.setLevel(logging.INFO) | |||
| formatter = logging.Formatter('%(asctime)s:%(levelname)s:%(message)s') | |||
| fh.setFormatter(formatter) | |||
| self.addHandler(fh) | |||
| def info(self, msg, *args, **kwargs): | |||
| if self.isEnabledFor(logging.INFO): | |||
| self._log(logging.INFO, msg, args, **kwargs) | |||
| def save_args(self, args): | |||
| self.info('Args:') | |||
| args_dict = vars(args) | |||
| for key in args_dict.keys(): | |||
| self.info('--> %s: %s', key, args_dict[key]) | |||
| self.info('') | |||
| def important_info(self, msg, *args, **kwargs): | |||
| if self.isEnabledFor(logging.INFO) and self.rank == 0: | |||
| line_width = 2 | |||
| important_msg = '\n' | |||
| important_msg += ('*'*70 + '\n')*line_width | |||
| important_msg += ('*'*line_width + '\n')*2 | |||
| important_msg += '*'*line_width + ' '*8 + msg + '\n' | |||
| important_msg += ('*'*line_width + '\n')*2 | |||
| important_msg += ('*'*70 + '\n')*line_width | |||
| self.info(important_msg, *args, **kwargs) | |||
| def get_logger(path, rank): | |||
| """Get Logger.""" | |||
| logger = LOGGER('yolov3_darknet53', rank) | |||
| logger.setup_logging_file(path, rank) | |||
| return logger | |||
+ 0
- 70
examples/model_security/model_attacks/cv/yolov3_darknet53/src/loss.py
View File
| @@ -1,70 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """YOLOV3 loss.""" | |||
| from mindspore.ops import operations as P | |||
| import mindspore.nn as nn | |||
| class XYLoss(nn.Cell): | |||
| """Loss for x and y.""" | |||
| def __init__(self): | |||
| super(XYLoss, self).__init__() | |||
| self.cross_entropy = P.SigmoidCrossEntropyWithLogits() | |||
| self.reduce_sum = P.ReduceSum() | |||
| def construct(self, object_mask, box_loss_scale, predict_xy, true_xy): | |||
| xy_loss = object_mask * box_loss_scale * self.cross_entropy(predict_xy, true_xy) | |||
| xy_loss = self.reduce_sum(xy_loss, ()) | |||
| return xy_loss | |||
| class WHLoss(nn.Cell): | |||
| """Loss for w and h.""" | |||
| def __init__(self): | |||
| super(WHLoss, self).__init__() | |||
| self.square = P.Square() | |||
| self.reduce_sum = P.ReduceSum() | |||
| def construct(self, object_mask, box_loss_scale, predict_wh, true_wh): | |||
| wh_loss = object_mask * box_loss_scale * 0.5 * P.Square()(true_wh - predict_wh) | |||
| wh_loss = self.reduce_sum(wh_loss, ()) | |||
| return wh_loss | |||
| class ConfidenceLoss(nn.Cell): | |||
| """Loss for confidence.""" | |||
| def __init__(self): | |||
| super(ConfidenceLoss, self).__init__() | |||
| self.cross_entropy = P.SigmoidCrossEntropyWithLogits() | |||
| self.reduce_sum = P.ReduceSum() | |||
| def construct(self, object_mask, predict_confidence, ignore_mask): | |||
| confidence_loss = self.cross_entropy(predict_confidence, object_mask) | |||
| confidence_loss = object_mask * confidence_loss + (1 - object_mask) * confidence_loss * ignore_mask | |||
| confidence_loss = self.reduce_sum(confidence_loss, ()) | |||
| return confidence_loss | |||
| class ClassLoss(nn.Cell): | |||
| """Loss for classification.""" | |||
| def __init__(self): | |||
| super(ClassLoss, self).__init__() | |||
| self.cross_entropy = P.SigmoidCrossEntropyWithLogits() | |||
| self.reduce_sum = P.ReduceSum() | |||
| def construct(self, object_mask, predict_class, class_probs): | |||
| class_loss = object_mask * self.cross_entropy(predict_class, class_probs) | |||
| class_loss = self.reduce_sum(class_loss, ()) | |||
| return class_loss | |||
+ 0
- 182
examples/model_security/model_attacks/cv/yolov3_darknet53/src/lr_scheduler.py
View File
| @@ -1,182 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Learning rate scheduler.""" | |||
| import math | |||
| from collections import Counter | |||
| import numpy as np | |||
| # pylint: disable=locally-disables, invalid-name | |||
| def linear_warmup_lr(current_step, warmup_steps, base_lr, init_lr): | |||
| """Linear learning rate.""" | |||
| lr_inc = (float(base_lr) - float(init_lr)) / float(warmup_steps) | |||
| lr = float(init_lr) + lr_inc * current_step | |||
| return lr | |||
| def warmup_step_lr(lr, lr_epochs, steps_per_epoch, warmup_epochs, max_epoch, gamma=0.1): | |||
| """Warmup step learning rate.""" | |||
| base_lr = lr | |||
| warmup_init_lr = 0 | |||
| total_steps = int(max_epoch * steps_per_epoch) | |||
| warmup_steps = int(warmup_epochs * steps_per_epoch) | |||
| milestones = lr_epochs | |||
| milestones_steps = [] | |||
| for milestone in milestones: | |||
| milestones_step = milestone * steps_per_epoch | |||
| milestones_steps.append(milestones_step) | |||
| lr_each_step = [] | |||
| lr = base_lr | |||
| milestones_steps_counter = Counter(milestones_steps) | |||
| for i in range(total_steps): | |||
| if i < warmup_steps: | |||
| lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr) | |||
| else: | |||
| lr = lr * gamma**milestones_steps_counter[i] | |||
| lr_each_step.append(lr) | |||
| return np.array(lr_each_step).astype(np.float32) | |||
| def multi_step_lr(lr, milestones, steps_per_epoch, max_epoch, gamma=0.1): | |||
| return warmup_step_lr(lr, milestones, steps_per_epoch, 0, max_epoch, gamma=gamma) | |||
| def step_lr(lr, epoch_size, steps_per_epoch, max_epoch, gamma=0.1): | |||
| lr_epochs = [] | |||
| for i in range(1, max_epoch): | |||
| if i % epoch_size == 0: | |||
| lr_epochs.append(i) | |||
| return multi_step_lr(lr, lr_epochs, steps_per_epoch, max_epoch, gamma=gamma) | |||
| def warmup_cosine_annealing_lr(lr, steps_per_epoch, warmup_epochs, max_epoch, T_max, eta_min=0): | |||
| """Cosine annealing learning rate.""" | |||
| base_lr = lr | |||
| warmup_init_lr = 0 | |||
| total_steps = int(max_epoch * steps_per_epoch) | |||
| warmup_steps = int(warmup_epochs * steps_per_epoch) | |||
| lr_each_step = [] | |||
| for i in range(total_steps): | |||
| last_epoch = i // steps_per_epoch | |||
| if i < warmup_steps: | |||
| lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr) | |||
| else: | |||
| lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi*last_epoch / T_max)) / 2 | |||
| lr_each_step.append(lr) | |||
| return np.array(lr_each_step).astype(np.float32) | |||
| def warmup_cosine_annealing_lr_V2(lr, steps_per_epoch, warmup_epochs, max_epoch, T_max, eta_min=0): | |||
| """Cosine annealing learning rate V2.""" | |||
| base_lr = lr | |||
| warmup_init_lr = 0 | |||
| total_steps = int(max_epoch * steps_per_epoch) | |||
| warmup_steps = int(warmup_epochs * steps_per_epoch) | |||
| last_lr = 0 | |||
| last_epoch_V1 = 0 | |||
| T_max_V2 = int(max_epoch*1/3) | |||
| lr_each_step = [] | |||
| for i in range(total_steps): | |||
| last_epoch = i // steps_per_epoch | |||
| if i < warmup_steps: | |||
| lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr) | |||
| else: | |||
| if i < total_steps*2/3: | |||
| lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi*last_epoch / T_max)) / 2 | |||
| last_lr = lr | |||
| last_epoch_V1 = last_epoch | |||
| else: | |||
| base_lr = last_lr | |||
| last_epoch = last_epoch-last_epoch_V1 | |||
| lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi * last_epoch / T_max_V2)) / 2 | |||
| lr_each_step.append(lr) | |||
| return np.array(lr_each_step).astype(np.float32) | |||
| def warmup_cosine_annealing_lr_sample(lr, steps_per_epoch, warmup_epochs, max_epoch, T_max, eta_min=0): | |||
| """Warmup cosine annealing learning rate.""" | |||
| start_sample_epoch = 60 | |||
| step_sample = 2 | |||
| tobe_sampled_epoch = 60 | |||
| end_sampled_epoch = start_sample_epoch + step_sample*tobe_sampled_epoch | |||
| max_sampled_epoch = max_epoch+tobe_sampled_epoch | |||
| T_max = max_sampled_epoch | |||
| base_lr = lr | |||
| warmup_init_lr = 0 | |||
| total_steps = int(max_epoch * steps_per_epoch) | |||
| total_sampled_steps = int(max_sampled_epoch * steps_per_epoch) | |||
| warmup_steps = int(warmup_epochs * steps_per_epoch) | |||
| lr_each_step = [] | |||
| for i in range(total_sampled_steps): | |||
| last_epoch = i // steps_per_epoch | |||
| if last_epoch in range(start_sample_epoch, end_sampled_epoch, step_sample): | |||
| continue | |||
| if i < warmup_steps: | |||
| lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr) | |||
| else: | |||
| lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi*last_epoch / T_max)) / 2 | |||
| lr_each_step.append(lr) | |||
| assert total_steps == len(lr_each_step) | |||
| return np.array(lr_each_step).astype(np.float32) | |||
| def get_lr(args): | |||
| """generate learning rate.""" | |||
| if args.lr_scheduler == 'exponential': | |||
| lr = warmup_step_lr(args.lr, | |||
| args.lr_epochs, | |||
| args.steps_per_epoch, | |||
| args.warmup_epochs, | |||
| args.max_epoch, | |||
| gamma=args.lr_gamma, | |||
| ) | |||
| elif args.lr_scheduler == 'cosine_annealing': | |||
| lr = warmup_cosine_annealing_lr(args.lr, | |||
| args.steps_per_epoch, | |||
| args.warmup_epochs, | |||
| args.max_epoch, | |||
| args.T_max, | |||
| args.eta_min) | |||
| elif args.lr_scheduler == 'cosine_annealing_V2': | |||
| lr = warmup_cosine_annealing_lr_V2(args.lr, | |||
| args.steps_per_epoch, | |||
| args.warmup_epochs, | |||
| args.max_epoch, | |||
| args.T_max, | |||
| args.eta_min) | |||
| elif args.lr_scheduler == 'cosine_annealing_sample': | |||
| lr = warmup_cosine_annealing_lr_sample(args.lr, | |||
| args.steps_per_epoch, | |||
| args.warmup_epochs, | |||
| args.max_epoch, | |||
| args.T_max, | |||
| args.eta_min) | |||
| else: | |||
| raise NotImplementedError(args.lr_scheduler) | |||
| return lr | |||
+ 0
- 595
examples/model_security/model_attacks/cv/yolov3_darknet53/src/transforms.py
View File
| @@ -1,595 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Preprocess dataset.""" | |||
| import random | |||
| import threading | |||
| import copy | |||
| import numpy as np | |||
| from PIL import Image | |||
| import cv2 | |||
| # pylint: disable=locally-disables, unused-argument, invalid-name | |||
| def _rand(a=0., b=1.): | |||
| return np.random.rand() * (b - a) + a | |||
| def bbox_iou(bbox_a, bbox_b, offset=0): | |||
| """Calculate Intersection-Over-Union(IOU) of two bounding boxes. | |||
| Parameters | |||
| ---------- | |||
| bbox_a : numpy.ndarray | |||
| An ndarray with shape :math:`(N, 4)`. | |||
| bbox_b : numpy.ndarray | |||
| An ndarray with shape :math:`(M, 4)`. | |||
| offset : float or int, default is 0 | |||
| The ``offset`` is used to control the whether the width(or height) is computed as | |||
| (right - left + ``offset``). | |||
| Note that the offset must be 0 for normalized bboxes, whose ranges are in ``[0, 1]``. | |||
| Returns | |||
| ------- | |||
| numpy.ndarray | |||
| An ndarray with shape :math:`(N, M)` indicates IOU between each pairs of | |||
| bounding boxes in `bbox_a` and `bbox_b`. | |||
| """ | |||
| if bbox_a.shape[1] < 4 or bbox_b.shape[1] < 4: | |||
| raise IndexError("Bounding boxes axis 1 must have at least length 4") | |||
| tl = np.maximum(bbox_a[:, None, :2], bbox_b[:, :2]) | |||
| br = np.minimum(bbox_a[:, None, 2:4], bbox_b[:, 2:4]) | |||
| area_i = np.prod(br - tl + offset, axis=2) * (tl < br).all(axis=2) | |||
| area_a = np.prod(bbox_a[:, 2:4] - bbox_a[:, :2] + offset, axis=1) | |||
| area_b = np.prod(bbox_b[:, 2:4] - bbox_b[:, :2] + offset, axis=1) | |||
| return area_i / (area_a[:, None] + area_b - area_i) | |||
| def statistic_normalize_img(img, statistic_norm): | |||
| """Statistic normalize images.""" | |||
| # img: RGB | |||
| if isinstance(img, Image.Image): | |||
| img = np.array(img) | |||
| img = img/255. | |||
| mean = np.array([0.485, 0.456, 0.406]) | |||
| std = np.array([0.229, 0.224, 0.225]) | |||
| if statistic_norm: | |||
| img = (img - mean) / std | |||
| return img | |||
| def get_interp_method(interp, sizes=()): | |||
| """ | |||
| Get the interpolation method for resize functions. | |||
| The major purpose of this function is to wrap a random interp method selection | |||
| and a auto-estimation method. | |||
| Note: | |||
| When shrinking an image, it will generally look best with AREA-based | |||
| interpolation, whereas, when enlarging an image, it will generally look best | |||
| with Bicubic or Bilinear. | |||
| Args: | |||
| interp (int): Interpolation method for all resizing operations. | |||
| - 0: Nearest Neighbors Interpolation. | |||
| - 1: Bilinear interpolation. | |||
| - 2: Bicubic interpolation over 4x4 pixel neighborhood. | |||
| - 3: Nearest Neighbors. Originally it should be Area-based, as we cannot find Area-based, | |||
| so we use NN instead. Area-based (resampling using pixel area relation). | |||
| It may be a preferred method for image decimation, as it gives moire-free results. | |||
| But when the image is zoomed, it is similar to the Nearest Neighbors method. (used by default). | |||
| - 4: Lanczos interpolation over 8x8 pixel neighborhood. | |||
| - 9: Cubic for enlarge, area for shrink, bilinear for others. | |||
| - 10: Random select from interpolation method mentioned above. | |||
| sizes (tuple): Format should like (old_height, old_width, new_height, new_width), | |||
| if None provided, auto(9) will return Area(2) anyway. Default: () | |||
| Returns: | |||
| int, interp method from 0 to 4. | |||
| """ | |||
| if interp == 9: | |||
| if sizes: | |||
| assert len(sizes) == 4 | |||
| oh, ow, nh, nw = sizes | |||
| if nh > oh and nw > ow: | |||
| return 2 | |||
| if nh < oh and nw < ow: | |||
| return 0 | |||
| return 1 | |||
| return 2 | |||
| if interp == 10: | |||
| return random.randint(0, 4) | |||
| if interp not in (0, 1, 2, 3, 4): | |||
| raise ValueError('Unknown interp method %d' % interp) | |||
| return interp | |||
| def pil_image_reshape(interp): | |||
| """Reshape pil image.""" | |||
| reshape_type = { | |||
| 0: Image.NEAREST, | |||
| 1: Image.BILINEAR, | |||
| 2: Image.BICUBIC, | |||
| 3: Image.NEAREST, | |||
| 4: Image.LANCZOS, | |||
| } | |||
| return reshape_type[interp] | |||
| def _preprocess_true_boxes(true_boxes, anchors, in_shape, num_classes, | |||
| max_boxes, label_smooth, label_smooth_factor=0.1): | |||
| """Preprocess annotation boxes.""" | |||
| anchors = np.array(anchors) | |||
| num_layers = anchors.shape[0] // 3 | |||
| anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]] | |||
| true_boxes = np.array(true_boxes, dtype='float32') | |||
| input_shape = np.array(in_shape, dtype='int32') | |||
| boxes_xy = (true_boxes[..., 0:2] + true_boxes[..., 2:4]) // 2. | |||
| # trans to box center point | |||
| boxes_wh = true_boxes[..., 2:4] - true_boxes[..., 0:2] | |||
| # input_shape is [h, w] | |||
| true_boxes[..., 0:2] = boxes_xy / input_shape[::-1] | |||
| true_boxes[..., 2:4] = boxes_wh / input_shape[::-1] | |||
| # true_boxes [x, y, w, h] | |||
| grid_shapes = [input_shape // 32, input_shape // 16, input_shape // 8] | |||
| # grid_shape [h, w] | |||
| y_true = [np.zeros((grid_shapes[l][0], grid_shapes[l][1], len(anchor_mask[l]), | |||
| 5 + num_classes), dtype='float32') for l in range(num_layers)] | |||
| # y_true [gridy, gridx] | |||
| anchors = np.expand_dims(anchors, 0) | |||
| anchors_max = anchors / 2. | |||
| anchors_min = -anchors_max | |||
| valid_mask = boxes_wh[..., 0] > 0 | |||
| wh = boxes_wh[valid_mask] | |||
| if wh.size > 0: | |||
| wh = np.expand_dims(wh, -2) | |||
| boxes_max = wh / 2. | |||
| boxes_min = -boxes_max | |||
| intersect_min = np.maximum(boxes_min, anchors_min) | |||
| intersect_max = np.minimum(boxes_max, anchors_max) | |||
| intersect_wh = np.maximum(intersect_max - intersect_min, 0.) | |||
| intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1] | |||
| box_area = wh[..., 0] * wh[..., 1] | |||
| anchor_area = anchors[..., 0] * anchors[..., 1] | |||
| iou = intersect_area / (box_area + anchor_area - intersect_area) | |||
| best_anchor = np.argmax(iou, axis=-1) | |||
| for t, n in enumerate(best_anchor): | |||
| for l in range(num_layers): | |||
| if n in anchor_mask[l]: | |||
| i = np.floor(true_boxes[t, 0] * grid_shapes[l][1]).astype('int32') # grid_y | |||
| j = np.floor(true_boxes[t, 1] * grid_shapes[l][0]).astype('int32') # grid_x | |||
| k = anchor_mask[l].index(n) | |||
| c = true_boxes[t, 4].astype('int32') | |||
| y_true[l][j, i, k, 0:4] = true_boxes[t, 0:4] | |||
| y_true[l][j, i, k, 4] = 1. | |||
| # lable-smooth | |||
| if label_smooth: | |||
| sigma = label_smooth_factor/(num_classes-1) | |||
| y_true[l][j, i, k, 5:] = sigma | |||
| y_true[l][j, i, k, 5+c] = 1-label_smooth_factor | |||
| else: | |||
| y_true[l][j, i, k, 5 + c] = 1. | |||
| # pad_gt_boxes for avoiding dynamic shape | |||
| pad_gt_box0 = np.zeros(shape=[max_boxes, 4], dtype=np.float32) | |||
| pad_gt_box1 = np.zeros(shape=[max_boxes, 4], dtype=np.float32) | |||
| pad_gt_box2 = np.zeros(shape=[max_boxes, 4], dtype=np.float32) | |||
| mask0 = np.reshape(y_true[0][..., 4:5], [-1]) | |||
| gt_box0 = np.reshape(y_true[0][..., 0:4], [-1, 4]) | |||
| # gt_box [boxes, [x,y,w,h]] | |||
| gt_box0 = gt_box0[mask0 == 1] | |||
| # gt_box0: get all boxes which have object | |||
| pad_gt_box0[:gt_box0.shape[0]] = gt_box0 | |||
| # gt_box0.shape[0]: total number of boxes in gt_box0 | |||
| # top N of pad_gt_box0 is real box, and after are pad by zero | |||
| mask1 = np.reshape(y_true[1][..., 4:5], [-1]) | |||
| gt_box1 = np.reshape(y_true[1][..., 0:4], [-1, 4]) | |||
| gt_box1 = gt_box1[mask1 == 1] | |||
| pad_gt_box1[:gt_box1.shape[0]] = gt_box1 | |||
| mask2 = np.reshape(y_true[2][..., 4:5], [-1]) | |||
| gt_box2 = np.reshape(y_true[2][..., 0:4], [-1, 4]) | |||
| gt_box2 = gt_box2[mask2 == 1] | |||
| pad_gt_box2[:gt_box2.shape[0]] = gt_box2 | |||
| return y_true[0], y_true[1], y_true[2], pad_gt_box0, pad_gt_box1, pad_gt_box2 | |||
| def _reshape_data(image, image_size): | |||
| """Reshape image.""" | |||
| if not isinstance(image, Image.Image): | |||
| image = Image.fromarray(image) | |||
| ori_w, ori_h = image.size | |||
| ori_image_shape = np.array([ori_w, ori_h], np.int32) | |||
| # original image shape fir:H sec:W | |||
| h, w = image_size | |||
| interp = get_interp_method(interp=9, sizes=(ori_h, ori_w, h, w)) | |||
| image = image.resize((w, h), pil_image_reshape(interp)) | |||
| image_data = statistic_normalize_img(image, statistic_norm=True) | |||
| if len(image_data.shape) == 2: | |||
| image_data = np.expand_dims(image_data, axis=-1) | |||
| image_data = np.concatenate([image_data, image_data, image_data], axis=-1) | |||
| image_data = image_data.astype(np.float32) | |||
| return image_data, ori_image_shape | |||
| def color_distortion(img, hue, sat, val, device_num): | |||
| """Color distortion.""" | |||
| hue = _rand(-hue, hue) | |||
| sat = _rand(1, sat) if _rand() < .5 else 1 / _rand(1, sat) | |||
| val = _rand(1, val) if _rand() < .5 else 1 / _rand(1, val) | |||
| if device_num != 1: | |||
| cv2.setNumThreads(1) | |||
| x = cv2.cvtColor(img, cv2.COLOR_RGB2HSV_FULL) | |||
| x = x / 255. | |||
| x[..., 0] += hue | |||
| x[..., 0][x[..., 0] > 1] -= 1 | |||
| x[..., 0][x[..., 0] < 0] += 1 | |||
| x[..., 1] *= sat | |||
| x[..., 2] *= val | |||
| x[x > 1] = 1 | |||
| x[x < 0] = 0 | |||
| x = x * 255. | |||
| x = x.astype(np.uint8) | |||
| image_data = cv2.cvtColor(x, cv2.COLOR_HSV2RGB_FULL) | |||
| return image_data | |||
| def filp_pil_image(img): | |||
| return img.transpose(Image.FLIP_LEFT_RIGHT) | |||
| def convert_gray_to_color(img): | |||
| if len(img.shape) == 2: | |||
| img = np.expand_dims(img, axis=-1) | |||
| img = np.concatenate([img, img, img], axis=-1) | |||
| return img | |||
| def _is_iou_satisfied_constraint(min_iou, max_iou, box, crop_box): | |||
| iou = bbox_iou(box, crop_box) | |||
| return min_iou <= iou.min() and max_iou >= iou.max() | |||
| def _choose_candidate_by_constraints(max_trial, input_w, input_h, image_w, image_h, jitter, box, use_constraints): | |||
| """Choose candidate by constraints.""" | |||
| if use_constraints: | |||
| constraints = ( | |||
| (0.1, None), | |||
| (0.3, None), | |||
| (0.5, None), | |||
| (0.7, None), | |||
| (0.9, None), | |||
| (None, 1), | |||
| ) | |||
| else: | |||
| constraints = ( | |||
| (None, None), | |||
| ) | |||
| # add default candidate | |||
| candidates = [(0, 0, input_w, input_h)] | |||
| for constraint in constraints: | |||
| min_iou, max_iou = constraint | |||
| min_iou = -np.inf if min_iou is None else min_iou | |||
| max_iou = np.inf if max_iou is None else max_iou | |||
| for _ in range(max_trial): | |||
| # box_data should have at least one box | |||
| new_ar = float(input_w) / float(input_h) * _rand(1 - jitter, 1 + jitter) / _rand(1 - jitter, 1 + jitter) | |||
| scale = _rand(0.25, 2) | |||
| if new_ar < 1: | |||
| nh = int(scale * input_h) | |||
| nw = int(nh * new_ar) | |||
| else: | |||
| nw = int(scale * input_w) | |||
| nh = int(nw / new_ar) | |||
| dx = int(_rand(0, input_w - nw)) | |||
| dy = int(_rand(0, input_h - nh)) | |||
| if box.size > 0: | |||
| t_box = copy.deepcopy(box) | |||
| t_box[:, [0, 2]] = t_box[:, [0, 2]] * float(nw) / float(image_w) + dx | |||
| t_box[:, [1, 3]] = t_box[:, [1, 3]] * float(nh) / float(image_h) + dy | |||
| crop_box = np.array((0, 0, input_w, input_h)) | |||
| if not _is_iou_satisfied_constraint(min_iou, max_iou, t_box, crop_box[np.newaxis]): | |||
| continue | |||
| else: | |||
| candidates.append((dx, dy, nw, nh)) | |||
| else: | |||
| raise Exception("!!! annotation box is less than 1") | |||
| return candidates | |||
| def _correct_bbox_by_candidates(candidates, input_w, input_h, image_w, | |||
| image_h, flip, box, box_data, allow_outside_center): | |||
| """Calculate correct boxes.""" | |||
| while candidates: | |||
| if len(candidates) > 1: | |||
| # ignore default candidate which do not crop | |||
| candidate = candidates.pop(np.random.randint(1, len(candidates))) | |||
| else: | |||
| candidate = candidates.pop(np.random.randint(0, len(candidates))) | |||
| dx, dy, nw, nh = candidate | |||
| t_box = copy.deepcopy(box) | |||
| t_box[:, [0, 2]] = t_box[:, [0, 2]] * float(nw) / float(image_w) + dx | |||
| t_box[:, [1, 3]] = t_box[:, [1, 3]] * float(nh) / float(image_h) + dy | |||
| if flip: | |||
| t_box[:, [0, 2]] = input_w - t_box[:, [2, 0]] | |||
| if allow_outside_center: | |||
| pass | |||
| else: | |||
| t_box = t_box[np.logical_and((t_box[:, 0] + t_box[:, 2])/2. >= 0., (t_box[:, 1] + t_box[:, 3])/2. >= 0.)] | |||
| t_box = t_box[np.logical_and((t_box[:, 0] + t_box[:, 2]) / 2. <= input_w, | |||
| (t_box[:, 1] + t_box[:, 3]) / 2. <= input_h)] | |||
| # recorrect x, y for case x,y < 0 reset to zero, after dx and dy, some box can smaller than zero | |||
| t_box[:, 0:2][t_box[:, 0:2] < 0] = 0 | |||
| # recorrect w,h not higher than input size | |||
| t_box[:, 2][t_box[:, 2] > input_w] = input_w | |||
| t_box[:, 3][t_box[:, 3] > input_h] = input_h | |||
| box_w = t_box[:, 2] - t_box[:, 0] | |||
| box_h = t_box[:, 3] - t_box[:, 1] | |||
| # discard invalid box: w or h smaller than 1 pixel | |||
| t_box = t_box[np.logical_and(box_w > 1, box_h > 1)] | |||
| if t_box.shape[0] > 0: | |||
| # break if number of find t_box | |||
| box_data[: len(t_box)] = t_box | |||
| return box_data, candidate | |||
| raise Exception('all candidates can not satisfied re-correct bbox') | |||
| def _data_aug(image, box, jitter, hue, sat, val, image_input_size, max_boxes, | |||
| anchors, num_classes, max_trial=10, device_num=1): | |||
| """Crop an image randomly with bounding box constraints. | |||
| This data augmentation is used in training of | |||
| Single Shot Multibox Detector [#]_. More details can be found in | |||
| data augmentation section of the original paper. | |||
| .. [#] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, | |||
| Scott Reed, Cheng-Yang Fu, Alexander C. Berg. | |||
| SSD: Single Shot MultiBox Detector. ECCV 2016.""" | |||
| if not isinstance(image, Image.Image): | |||
| image = Image.fromarray(image) | |||
| image_w, image_h = image.size | |||
| input_h, input_w = image_input_size | |||
| np.random.shuffle(box) | |||
| if len(box) > max_boxes: | |||
| box = box[:max_boxes] | |||
| flip = _rand() < .5 | |||
| box_data = np.zeros((max_boxes, 5)) | |||
| candidates = _choose_candidate_by_constraints(use_constraints=False, | |||
| max_trial=max_trial, | |||
| input_w=input_w, | |||
| input_h=input_h, | |||
| image_w=image_w, | |||
| image_h=image_h, | |||
| jitter=jitter, | |||
| box=box) | |||
| box_data, candidate = _correct_bbox_by_candidates(candidates=candidates, | |||
| input_w=input_w, | |||
| input_h=input_h, | |||
| image_w=image_w, | |||
| image_h=image_h, | |||
| flip=flip, | |||
| box=box, | |||
| box_data=box_data, | |||
| allow_outside_center=True) | |||
| dx, dy, nw, nh = candidate | |||
| interp = get_interp_method(interp=10) | |||
| image = image.resize((nw, nh), pil_image_reshape(interp)) | |||
| # place image, gray color as back graoud | |||
| new_image = Image.new('RGB', (input_w, input_h), (128, 128, 128)) | |||
| new_image.paste(image, (dx, dy)) | |||
| image = new_image | |||
| if flip: | |||
| image = filp_pil_image(image) | |||
| image = np.array(image) | |||
| image = convert_gray_to_color(image) | |||
| image_data = color_distortion(image, hue, sat, val, device_num) | |||
| image_data = statistic_normalize_img(image_data, statistic_norm=True) | |||
| image_data = image_data.astype(np.float32) | |||
| return image_data, box_data | |||
| def preprocess_fn(image, box, config, input_size, device_num): | |||
| """Preprocess data function.""" | |||
| config_anchors = config.anchor_scales | |||
| anchors = np.array([list(x) for x in config_anchors]) | |||
| max_boxes = config.max_box | |||
| num_classes = config.num_classes | |||
| jitter = config.jitter | |||
| hue = config.hue | |||
| sat = config.saturation | |||
| val = config.value | |||
| image, anno = _data_aug(image, box, jitter=jitter, hue=hue, sat=sat, val=val, | |||
| image_input_size=input_size, max_boxes=max_boxes, | |||
| num_classes=num_classes, anchors=anchors, device_num=device_num) | |||
| return image, anno | |||
| def reshape_fn(image, img_id, config): | |||
| input_size = config.test_img_shape | |||
| image, ori_image_shape = _reshape_data(image, image_size=input_size) | |||
| return image, ori_image_shape, img_id | |||
| class MultiScaleTrans: | |||
| """Multi scale transform.""" | |||
| def __init__(self, config, device_num): | |||
| self.config = config | |||
| self.seed = 0 | |||
| self.size_list = [] | |||
| self.resize_rate = config.resize_rate | |||
| self.dataset_size = config.dataset_size | |||
| self.size_dict = {} | |||
| self.seed_num = int(1e6) | |||
| self.seed_list = self.generate_seed_list(seed_num=self.seed_num) | |||
| self.resize_count_num = int(np.ceil(self.dataset_size / self.resize_rate)) | |||
| self.device_num = device_num | |||
| self.anchor_scales = config.anchor_scales | |||
| self.num_classes = config.num_classes | |||
| self.max_box = config.max_box | |||
| self.label_smooth = config.label_smooth | |||
| self.label_smooth_factor = config.label_smooth_factor | |||
| def generate_seed_list(self, init_seed=1234, seed_num=int(1e6), seed_range=(1, 1000)): | |||
| seed_list = [] | |||
| random.seed(init_seed) | |||
| for _ in range(seed_num): | |||
| seed = random.randint(seed_range[0], seed_range[1]) | |||
| seed_list.append(seed) | |||
| return seed_list | |||
| def __call__(self, imgs, annos, x1, x2, x3, x4, x5, x6, batchInfo): | |||
| epoch_num = batchInfo.get_epoch_num() | |||
| size_idx = int(batchInfo.get_batch_num() / self.resize_rate) | |||
| seed_key = self.seed_list[(epoch_num * self.resize_count_num + size_idx) % self.seed_num] | |||
| ret_imgs = [] | |||
| ret_annos = [] | |||
| bbox1 = [] | |||
| bbox2 = [] | |||
| bbox3 = [] | |||
| gt1 = [] | |||
| gt2 = [] | |||
| gt3 = [] | |||
| if self.size_dict.get(seed_key, None) is None: | |||
| random.seed(seed_key) | |||
| new_size = random.choice(self.config.multi_scale) | |||
| self.size_dict[seed_key] = new_size | |||
| seed = seed_key | |||
| input_size = self.size_dict[seed] | |||
| for img, anno in zip(imgs, annos): | |||
| img, anno = preprocess_fn(img, anno, self.config, input_size, self.device_num) | |||
| ret_imgs.append(img.transpose(2, 0, 1).copy()) | |||
| bbox_true_1, bbox_true_2, bbox_true_3, gt_box1, gt_box2, gt_box3 = \ | |||
| _preprocess_true_boxes(true_boxes=anno, anchors=self.anchor_scales, in_shape=img.shape[0:2], | |||
| num_classes=self.num_classes, max_boxes=self.max_box, | |||
| label_smooth=self.label_smooth, label_smooth_factor=self.label_smooth_factor) | |||
| bbox1.append(bbox_true_1) | |||
| bbox2.append(bbox_true_2) | |||
| bbox3.append(bbox_true_3) | |||
| gt1.append(gt_box1) | |||
| gt2.append(gt_box2) | |||
| gt3.append(gt_box3) | |||
| ret_annos.append(0) | |||
| return np.array(ret_imgs), np.array(ret_annos), np.array(bbox1), np.array(bbox2), np.array(bbox3), \ | |||
| np.array(gt1), np.array(gt2), np.array(gt3) | |||
| def thread_batch_preprocess_true_box(annos, config, input_shape, result_index, batch_bbox_true_1, batch_bbox_true_2, | |||
| batch_bbox_true_3, batch_gt_box1, batch_gt_box2, batch_gt_box3): | |||
| """Preprocess true box for multi-thread.""" | |||
| i = 0 | |||
| for anno in annos: | |||
| bbox_true_1, bbox_true_2, bbox_true_3, gt_box1, gt_box2, gt_box3 = \ | |||
| _preprocess_true_boxes(true_boxes=anno, anchors=config.anchor_scales, in_shape=input_shape, | |||
| num_classes=config.num_classes, max_boxes=config.max_box, | |||
| label_smooth=config.label_smooth, label_smooth_factor=config.label_smooth_factor) | |||
| batch_bbox_true_1[result_index + i] = bbox_true_1 | |||
| batch_bbox_true_2[result_index + i] = bbox_true_2 | |||
| batch_bbox_true_3[result_index + i] = bbox_true_3 | |||
| batch_gt_box1[result_index + i] = gt_box1 | |||
| batch_gt_box2[result_index + i] = gt_box2 | |||
| batch_gt_box3[result_index + i] = gt_box3 | |||
| i = i + 1 | |||
| def batch_preprocess_true_box(annos, config, input_shape): | |||
| """Preprocess true box with multi-thread.""" | |||
| batch_bbox_true_1 = [] | |||
| batch_bbox_true_2 = [] | |||
| batch_bbox_true_3 = [] | |||
| batch_gt_box1 = [] | |||
| batch_gt_box2 = [] | |||
| batch_gt_box3 = [] | |||
| threads = [] | |||
| step = 4 | |||
| for index in range(0, len(annos), step): | |||
| for _ in range(step): | |||
| batch_bbox_true_1.append(None) | |||
| batch_bbox_true_2.append(None) | |||
| batch_bbox_true_3.append(None) | |||
| batch_gt_box1.append(None) | |||
| batch_gt_box2.append(None) | |||
| batch_gt_box3.append(None) | |||
| step_anno = annos[index: index + step] | |||
| t = threading.Thread(target=thread_batch_preprocess_true_box, | |||
| args=(step_anno, config, input_shape, index, batch_bbox_true_1, batch_bbox_true_2, | |||
| batch_bbox_true_3, batch_gt_box1, batch_gt_box2, batch_gt_box3)) | |||
| t.start() | |||
| threads.append(t) | |||
| for t in threads: | |||
| t.join() | |||
| return np.array(batch_bbox_true_1), np.array(batch_bbox_true_2), np.array(batch_bbox_true_3), \ | |||
| np.array(batch_gt_box1), np.array(batch_gt_box2), np.array(batch_gt_box3) | |||
| def batch_preprocess_true_box_single(annos, config, input_shape): | |||
| """Preprocess true boxes.""" | |||
| batch_bbox_true_1 = [] | |||
| batch_bbox_true_2 = [] | |||
| batch_bbox_true_3 = [] | |||
| batch_gt_box1 = [] | |||
| batch_gt_box2 = [] | |||
| batch_gt_box3 = [] | |||
| for anno in annos: | |||
| bbox_true_1, bbox_true_2, bbox_true_3, gt_box1, gt_box2, gt_box3 = \ | |||
| _preprocess_true_boxes(true_boxes=anno, anchors=config.anchor_scales, in_shape=input_shape, | |||
| num_classes=config.num_classes, max_boxes=config.max_box, | |||
| label_smooth=config.label_smooth, label_smooth_factor=config.label_smooth_factor) | |||
| batch_bbox_true_1.append(bbox_true_1) | |||
| batch_bbox_true_2.append(bbox_true_2) | |||
| batch_bbox_true_3.append(bbox_true_3) | |||
| batch_gt_box1.append(gt_box1) | |||
| batch_gt_box2.append(gt_box2) | |||
| batch_gt_box3.append(gt_box3) | |||
| return np.array(batch_bbox_true_1), np.array(batch_bbox_true_2), np.array(batch_bbox_true_3), \ | |||
| np.array(batch_gt_box1), np.array(batch_gt_box2), np.array(batch_gt_box3) | |||
+ 0
- 187
examples/model_security/model_attacks/cv/yolov3_darknet53/src/util.py
View File
| @@ -1,187 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """Util class or function.""" | |||
| from mindspore.train.serialization import load_checkpoint | |||
| import mindspore.nn as nn | |||
| import mindspore.common.dtype as mstype | |||
| from .yolo import YoloLossBlock | |||
| class AverageMeter: | |||
| """Computes and stores the average and current value""" | |||
| def __init__(self, name, fmt=':f', tb_writer=None): | |||
| self.name = name | |||
| self.fmt = fmt | |||
| self.reset() | |||
| self.tb_writer = tb_writer | |||
| self.cur_step = 1 | |||
| self.val = 0 | |||
| self.avg = 0 | |||
| self.sum = 0 | |||
| self.count = 0 | |||
| def reset(self): | |||
| self.val = 0 | |||
| self.avg = 0 | |||
| self.sum = 0 | |||
| self.count = 0 | |||
| def update(self, val, n=1): | |||
| self.val = val | |||
| self.sum += val * n | |||
| self.count += n | |||
| self.avg = self.sum / self.count | |||
| if self.tb_writer is not None: | |||
| self.tb_writer.add_scalar(self.name, self.val, self.cur_step) | |||
| self.cur_step += 1 | |||
| def __str__(self): | |||
| fmtstr = '{name}:{avg' + self.fmt + '}' | |||
| return fmtstr.format(**self.__dict__) | |||
| def load_backbone(net, ckpt_path, args): | |||
| """Load darknet53 backbone checkpoint.""" | |||
| param_dict = load_checkpoint(ckpt_path) | |||
| yolo_backbone_prefix = 'feature_map.backbone' | |||
| darknet_backbone_prefix = 'network.backbone' | |||
| find_param = [] | |||
| not_found_param = [] | |||
| net.init_parameters_data() | |||
| for name, cell in net.cells_and_names(): | |||
| if name.startswith(yolo_backbone_prefix): | |||
| name = name.replace(yolo_backbone_prefix, darknet_backbone_prefix) | |||
| if isinstance(cell, (nn.Conv2d, nn.Dense)): | |||
| darknet_weight = '{}.weight'.format(name) | |||
| darknet_bias = '{}.bias'.format(name) | |||
| if darknet_weight in param_dict: | |||
| cell.weight.set_data(param_dict[darknet_weight].data) | |||
| find_param.append(darknet_weight) | |||
| else: | |||
| not_found_param.append(darknet_weight) | |||
| if darknet_bias in param_dict: | |||
| cell.bias.set_data(param_dict[darknet_bias].data) | |||
| find_param.append(darknet_bias) | |||
| else: | |||
| not_found_param.append(darknet_bias) | |||
| elif isinstance(cell, (nn.BatchNorm2d, nn.BatchNorm1d)): | |||
| darknet_moving_mean = '{}.moving_mean'.format(name) | |||
| darknet_moving_variance = '{}.moving_variance'.format(name) | |||
| darknet_gamma = '{}.gamma'.format(name) | |||
| darknet_beta = '{}.beta'.format(name) | |||
| if darknet_moving_mean in param_dict: | |||
| cell.moving_mean.set_data(param_dict[darknet_moving_mean].data) | |||
| find_param.append(darknet_moving_mean) | |||
| else: | |||
| not_found_param.append(darknet_moving_mean) | |||
| if darknet_moving_variance in param_dict: | |||
| cell.moving_variance.set_data(param_dict[darknet_moving_variance].data) | |||
| find_param.append(darknet_moving_variance) | |||
| else: | |||
| not_found_param.append(darknet_moving_variance) | |||
| if darknet_gamma in param_dict: | |||
| cell.gamma.set_data(param_dict[darknet_gamma].data) | |||
| find_param.append(darknet_gamma) | |||
| else: | |||
| not_found_param.append(darknet_gamma) | |||
| if darknet_beta in param_dict: | |||
| cell.beta.set_data(param_dict[darknet_beta].data) | |||
| find_param.append(darknet_beta) | |||
| else: | |||
| not_found_param.append(darknet_beta) | |||
| args.logger.info('================found_param {}========='.format(len(find_param))) | |||
| args.logger.info(find_param) | |||
| args.logger.info('================not_found_param {}========='.format(len(not_found_param))) | |||
| args.logger.info(not_found_param) | |||
| args.logger.info('=====load {} successfully ====='.format(ckpt_path)) | |||
| return net | |||
| def default_wd_filter(x): | |||
| """default weight decay filter.""" | |||
| parameter_name = x.name | |||
| if parameter_name.endswith('.bias'): | |||
| # all bias not using weight decay | |||
| return False | |||
| if parameter_name.endswith('.gamma'): | |||
| # bn weight bias not using weight decay, be carefully for now x not include BN | |||
| return False | |||
| if parameter_name.endswith('.beta'): | |||
| # bn weight bias not using weight decay, be carefully for now x not include BN | |||
| return False | |||
| return True | |||
| def get_param_groups(network): | |||
| """Param groups for optimizer.""" | |||
| decay_params = [] | |||
| no_decay_params = [] | |||
| for x in network.trainable_params(): | |||
| parameter_name = x.name | |||
| if parameter_name.endswith('.bias'): | |||
| # all bias not using weight decay | |||
| no_decay_params.append(x) | |||
| elif parameter_name.endswith('.gamma'): | |||
| # bn weight bias not using weight decay, be carefully for now x not include BN | |||
| no_decay_params.append(x) | |||
| elif parameter_name.endswith('.beta'): | |||
| # bn weight bias not using weight decay, be carefully for now x not include BN | |||
| no_decay_params.append(x) | |||
| else: | |||
| decay_params.append(x) | |||
| return [{'params': no_decay_params, 'weight_decay': 0.0}, {'params': decay_params}] | |||
| class ShapeRecord: | |||
| """Log image shape.""" | |||
| def __init__(self): | |||
| self.shape_record = { | |||
| 320: 0, | |||
| 352: 0, | |||
| 384: 0, | |||
| 416: 0, | |||
| 448: 0, | |||
| 480: 0, | |||
| 512: 0, | |||
| 544: 0, | |||
| 576: 0, | |||
| 608: 0, | |||
| 'total': 0 | |||
| } | |||
| def set(self, shape): | |||
| if len(shape) > 1: | |||
| shape = shape[0] | |||
| shape = int(shape) | |||
| self.shape_record[shape] += 1 | |||
| self.shape_record['total'] += 1 | |||
| def show(self, logger): | |||
| for key in self.shape_record: | |||
| rate = self.shape_record[key] / float(self.shape_record['total']) | |||
| logger.info('shape {}: {:.2f}%'.format(key, rate*100)) | |||
| def keep_loss_fp32(network): | |||
| """Keep loss of network with float32""" | |||
| for _, cell in network.cells_and_names(): | |||
| if isinstance(cell, (YoloLossBlock,)): | |||
| cell.to_float(mstype.float32) | |||
+ 0
- 441
examples/model_security/model_attacks/cv/yolov3_darknet53/src/yolo.py
View File
| @@ -1,441 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """YOLOv3 based on DarkNet.""" | |||
| import mindspore as ms | |||
| import mindspore.nn as nn | |||
| from mindspore.common.tensor import Tensor | |||
| from mindspore import context | |||
| from mindspore.context import ParallelMode | |||
| from mindspore.parallel._auto_parallel_context import auto_parallel_context | |||
| from mindspore.communication.management import get_group_size | |||
| from mindspore.ops import operations as P | |||
| from mindspore.ops import functional as F | |||
| from mindspore.ops import composite as C | |||
| from src.darknet import DarkNet, ResidualBlock | |||
| from src.config import ConfigYOLOV3DarkNet53 | |||
| from src.loss import XYLoss, WHLoss, ConfidenceLoss, ClassLoss | |||
| # pylint: disable=locally-disables, missing-docstring, invalid-name | |||
| def _conv_bn_relu(in_channel, | |||
| out_channel, | |||
| ksize, | |||
| stride=1, | |||
| padding=0, | |||
| dilation=1, | |||
| alpha=0.1, | |||
| momentum=0.9, | |||
| eps=1e-5, | |||
| pad_mode="same"): | |||
| """Get a conv2d batchnorm and relu layer""" | |||
| return nn.SequentialCell( | |||
| [nn.Conv2d(in_channel, | |||
| out_channel, | |||
| kernel_size=ksize, | |||
| stride=stride, | |||
| padding=padding, | |||
| dilation=dilation, | |||
| pad_mode=pad_mode), | |||
| nn.BatchNorm2d(out_channel, momentum=momentum, eps=eps), | |||
| nn.LeakyReLU(alpha)] | |||
| ) | |||
| class YoloBlock(nn.Cell): | |||
| """ | |||
| YoloBlock for YOLOv3. | |||
| Args: | |||
| in_channels: Integer. Input channel. | |||
| out_chls: Interger. Middle channel. | |||
| out_channels: Integer. Output channel. | |||
| Returns: | |||
| Tuple, tuple of output tensor,(f1,f2,f3). | |||
| Examples: | |||
| YoloBlock(1024, 512, 255) | |||
| """ | |||
| def __init__(self, in_channels, out_chls, out_channels): | |||
| super(YoloBlock, self).__init__() | |||
| out_chls_2 = out_chls*2 | |||
| self.conv0 = _conv_bn_relu(in_channels, out_chls, ksize=1) | |||
| self.conv1 = _conv_bn_relu(out_chls, out_chls_2, ksize=3) | |||
| self.conv2 = _conv_bn_relu(out_chls_2, out_chls, ksize=1) | |||
| self.conv3 = _conv_bn_relu(out_chls, out_chls_2, ksize=3) | |||
| self.conv4 = _conv_bn_relu(out_chls_2, out_chls, ksize=1) | |||
| self.conv5 = _conv_bn_relu(out_chls, out_chls_2, ksize=3) | |||
| self.conv6 = nn.Conv2d(out_chls_2, out_channels, kernel_size=1, stride=1, has_bias=True) | |||
| def construct(self, x): | |||
| c1 = self.conv0(x) | |||
| c2 = self.conv1(c1) | |||
| c3 = self.conv2(c2) | |||
| c4 = self.conv3(c3) | |||
| c5 = self.conv4(c4) | |||
| c6 = self.conv5(c5) | |||
| out = self.conv6(c6) | |||
| return c5, out | |||
| class YOLOv3(nn.Cell): | |||
| """ | |||
| YOLOv3 Network. | |||
| Note: | |||
| backbone = darknet53 | |||
| Args: | |||
| backbone_shape: List. Darknet output channels shape. | |||
| backbone: Cell. Backbone Network. | |||
| out_channel: Interger. Output channel. | |||
| Returns: | |||
| Tensor, output tensor. | |||
| Examples: | |||
| YOLOv3(backbone_shape=[64, 128, 256, 512, 1024] | |||
| backbone=darknet53(), | |||
| out_channel=255) | |||
| """ | |||
| def __init__(self, backbone_shape, backbone, out_channel): | |||
| super(YOLOv3, self).__init__() | |||
| self.out_channel = out_channel | |||
| self.backbone = backbone | |||
| self.backblock0 = YoloBlock(backbone_shape[-1], out_chls=backbone_shape[-2], out_channels=out_channel) | |||
| self.conv1 = _conv_bn_relu(in_channel=backbone_shape[-2], out_channel=backbone_shape[-2]//2, ksize=1) | |||
| self.backblock1 = YoloBlock(in_channels=backbone_shape[-2]+backbone_shape[-3], | |||
| out_chls=backbone_shape[-3], | |||
| out_channels=out_channel) | |||
| self.conv2 = _conv_bn_relu(in_channel=backbone_shape[-3], out_channel=backbone_shape[-3]//2, ksize=1) | |||
| self.backblock2 = YoloBlock(in_channels=backbone_shape[-3]+backbone_shape[-4], | |||
| out_chls=backbone_shape[-4], | |||
| out_channels=out_channel) | |||
| self.concat = P.Concat(axis=1) | |||
| def construct(self, x): | |||
| # input_shape of x is (batch_size, 3, h, w) | |||
| # feature_map1 is (batch_size, backbone_shape[2], h/8, w/8) | |||
| # feature_map2 is (batch_size, backbone_shape[3], h/16, w/16) | |||
| # feature_map3 is (batch_size, backbone_shape[4], h/32, w/32) | |||
| img_hight = P.Shape()(x)[2] | |||
| img_width = P.Shape()(x)[3] | |||
| feature_map1, feature_map2, feature_map3 = self.backbone(x) | |||
| con1, big_object_output = self.backblock0(feature_map3) | |||
| con1 = self.conv1(con1) | |||
| ups1 = P.ResizeNearestNeighbor((img_hight / 16, img_width / 16))(con1) | |||
| con1 = self.concat((ups1, feature_map2)) | |||
| con2, medium_object_output = self.backblock1(con1) | |||
| con2 = self.conv2(con2) | |||
| ups2 = P.ResizeNearestNeighbor((img_hight / 8, img_width / 8))(con2) | |||
| con3 = self.concat((ups2, feature_map1)) | |||
| _, small_object_output = self.backblock2(con3) | |||
| return big_object_output, medium_object_output, small_object_output | |||
| class DetectionBlock(nn.Cell): | |||
| """ | |||
| YOLOv3 detection Network. It will finally output the detection result. | |||
| Args: | |||
| scale: Character. | |||
| config: ConfigYOLOV3DarkNet53, Configuration instance. | |||
| is_training: Bool, Whether train or not, default True. | |||
| Returns: | |||
| Tuple, tuple of output tensor,(f1,f2,f3). | |||
| Examples: | |||
| DetectionBlock(scale='l',stride=32) | |||
| """ | |||
| def __init__(self, scale, config=ConfigYOLOV3DarkNet53(), is_training=True): | |||
| super(DetectionBlock, self).__init__() | |||
| self.config = config | |||
| if scale == 's': | |||
| idx = (0, 1, 2) | |||
| elif scale == 'm': | |||
| idx = (3, 4, 5) | |||
| elif scale == 'l': | |||
| idx = (6, 7, 8) | |||
| else: | |||
| raise KeyError("Invalid scale value for DetectionBlock") | |||
| self.anchors = Tensor([self.config.anchor_scales[i] for i in idx], ms.float32) | |||
| self.num_anchors_per_scale = 3 | |||
| self.num_attrib = 4+1+self.config.num_classes | |||
| self.lambda_coord = 1 | |||
| self.sigmoid = nn.Sigmoid() | |||
| self.reshape = P.Reshape() | |||
| self.tile = P.Tile() | |||
| self.concat = P.Concat(axis=-1) | |||
| self.conf_training = is_training | |||
| def construct(self, x, input_shape): | |||
| num_batch = P.Shape()(x)[0] | |||
| grid_size = P.Shape()(x)[2:4] | |||
| # Reshape and transpose the feature to [n, grid_size[0], grid_size[1], 3, num_attrib] | |||
| prediction = P.Reshape()(x, (num_batch, | |||
| self.num_anchors_per_scale, | |||
| self.num_attrib, | |||
| grid_size[0], | |||
| grid_size[1])) | |||
| prediction = P.Transpose()(prediction, (0, 3, 4, 1, 2)) | |||
| range_x = range(grid_size[1]) | |||
| range_y = range(grid_size[0]) | |||
| grid_x = P.Cast()(F.tuple_to_array(range_x), ms.float32) | |||
| grid_y = P.Cast()(F.tuple_to_array(range_y), ms.float32) | |||
| # Tensor of shape [grid_size[0], grid_size[1], 1, 1] representing the coordinate of x/y axis for each grid | |||
| # [batch, gridx, gridy, 1, 1] | |||
| grid_x = self.tile(self.reshape(grid_x, (1, 1, -1, 1, 1)), (1, grid_size[0], 1, 1, 1)) | |||
| grid_y = self.tile(self.reshape(grid_y, (1, -1, 1, 1, 1)), (1, 1, grid_size[1], 1, 1)) | |||
| # Shape is [grid_size[0], grid_size[1], 1, 2] | |||
| grid = self.concat((grid_x, grid_y)) | |||
| box_xy = prediction[:, :, :, :, :2] | |||
| box_wh = prediction[:, :, :, :, 2:4] | |||
| box_confidence = prediction[:, :, :, :, 4:5] | |||
| box_probs = prediction[:, :, :, :, 5:] | |||
| # gridsize1 is x | |||
| # gridsize0 is y | |||
| box_xy = (self.sigmoid(box_xy) + grid) / P.Cast()(F.tuple_to_array((grid_size[1], grid_size[0])), ms.float32) | |||
| # box_wh is w->h | |||
| box_wh = P.Exp()(box_wh) * self.anchors / input_shape | |||
| box_confidence = self.sigmoid(box_confidence) | |||
| box_probs = self.sigmoid(box_probs) | |||
| if self.conf_training: | |||
| return grid, prediction, box_xy, box_wh | |||
| return self.concat((box_xy, box_wh, box_confidence, box_probs)) | |||
| class Iou(nn.Cell): | |||
| """Calculate the iou of boxes""" | |||
| def __init__(self): | |||
| super(Iou, self).__init__() | |||
| self.min = P.Minimum() | |||
| self.max = P.Maximum() | |||
| def construct(self, box1, box2): | |||
| # box1: pred_box [batch, gx, gy, anchors, 1, 4] ->4: [x_center, y_center, w, h] | |||
| # box2: gt_box [batch, 1, 1, 1, maxbox, 4] | |||
| # convert to topLeft and rightDown | |||
| box1_xy = box1[:, :, :, :, :, :2] | |||
| box1_wh = box1[:, :, :, :, :, 2:4] | |||
| box1_mins = box1_xy - box1_wh / F.scalar_to_array(2.0) # topLeft | |||
| box1_maxs = box1_xy + box1_wh / F.scalar_to_array(2.0) # rightDown | |||
| box2_xy = box2[:, :, :, :, :, :2] | |||
| box2_wh = box2[:, :, :, :, :, 2:4] | |||
| box2_mins = box2_xy - box2_wh / F.scalar_to_array(2.0) | |||
| box2_maxs = box2_xy + box2_wh / F.scalar_to_array(2.0) | |||
| intersect_mins = self.max(box1_mins, box2_mins) | |||
| intersect_maxs = self.min(box1_maxs, box2_maxs) | |||
| intersect_wh = self.max(intersect_maxs - intersect_mins, F.scalar_to_array(0.0)) | |||
| # P.squeeze: for effiecient slice | |||
| intersect_area = P.Squeeze(-1)(intersect_wh[:, :, :, :, :, 0:1]) * \ | |||
| P.Squeeze(-1)(intersect_wh[:, :, :, :, :, 1:2]) | |||
| box1_area = P.Squeeze(-1)(box1_wh[:, :, :, :, :, 0:1]) * P.Squeeze(-1)(box1_wh[:, :, :, :, :, 1:2]) | |||
| box2_area = P.Squeeze(-1)(box2_wh[:, :, :, :, :, 0:1]) * P.Squeeze(-1)(box2_wh[:, :, :, :, :, 1:2]) | |||
| iou = intersect_area / (box1_area + box2_area - intersect_area) | |||
| # iou : [batch, gx, gy, anchors, maxboxes] | |||
| return iou | |||
| class YoloLossBlock(nn.Cell): | |||
| """ | |||
| Loss block cell of YOLOV3 network. | |||
| """ | |||
| def __init__(self, scale, config=ConfigYOLOV3DarkNet53()): | |||
| super(YoloLossBlock, self).__init__() | |||
| self.config = config | |||
| if scale == 's': | |||
| # anchor mask | |||
| idx = (0, 1, 2) | |||
| elif scale == 'm': | |||
| idx = (3, 4, 5) | |||
| elif scale == 'l': | |||
| idx = (6, 7, 8) | |||
| else: | |||
| raise KeyError("Invalid scale value for DetectionBlock") | |||
| self.anchors = Tensor([self.config.anchor_scales[i] for i in idx], ms.float32) | |||
| self.ignore_threshold = Tensor(self.config.ignore_threshold, ms.float32) | |||
| self.concat = P.Concat(axis=-1) | |||
| self.iou = Iou() | |||
| self.reduce_max = P.ReduceMax(keep_dims=False) | |||
| self.xy_loss = XYLoss() | |||
| self.wh_loss = WHLoss() | |||
| self.confidenceLoss = ConfidenceLoss() | |||
| self.classLoss = ClassLoss() | |||
| def construct(self, grid, prediction, pred_xy, pred_wh, y_true, gt_box, input_shape): | |||
| # prediction : origin output from yolo | |||
| # pred_xy: (sigmoid(xy)+grid)/grid_size | |||
| # pred_wh: (exp(wh)*anchors)/input_shape | |||
| # y_true : after normalize | |||
| # gt_box: [batch, maxboxes, xyhw] after normalize | |||
| object_mask = y_true[:, :, :, :, 4:5] | |||
| class_probs = y_true[:, :, :, :, 5:] | |||
| grid_shape = P.Shape()(prediction)[1:3] | |||
| grid_shape = P.Cast()(F.tuple_to_array(grid_shape[::-1]), ms.float32) | |||
| pred_boxes = self.concat((pred_xy, pred_wh)) | |||
| true_xy = y_true[:, :, :, :, :2] * grid_shape - grid | |||
| true_wh = y_true[:, :, :, :, 2:4] | |||
| true_wh = P.Select()(P.Equal()(true_wh, 0.0), | |||
| P.Fill()(P.DType()(true_wh), | |||
| P.Shape()(true_wh), 1.0), | |||
| true_wh) | |||
| true_wh = P.Log()(true_wh / self.anchors * input_shape) | |||
| # 2-w*h for large picture, use small scale, since small obj need more precise | |||
| box_loss_scale = 2 - y_true[:, :, :, :, 2:3] * y_true[:, :, :, :, 3:4] | |||
| gt_shape = P.Shape()(gt_box) | |||
| gt_box = P.Reshape()(gt_box, (gt_shape[0], 1, 1, 1, gt_shape[1], gt_shape[2])) | |||
| # add one more dimension for broadcast | |||
| iou = self.iou(P.ExpandDims()(pred_boxes, -2), gt_box) | |||
| # gt_box is x,y,h,w after normalize | |||
| # [batch, grid[0], grid[1], num_anchor, num_gt] | |||
| best_iou = self.reduce_max(iou, -1) | |||
| # [batch, grid[0], grid[1], num_anchor] | |||
| # ignore_mask IOU too small | |||
| ignore_mask = best_iou < self.ignore_threshold | |||
| ignore_mask = P.Cast()(ignore_mask, ms.float32) | |||
| ignore_mask = P.ExpandDims()(ignore_mask, -1) | |||
| # ignore_mask backpro will cause a lot maximunGrad and minimumGrad time consume. | |||
| # so we turn off its gradient | |||
| ignore_mask = F.stop_gradient(ignore_mask) | |||
| xy_loss = self.xy_loss(object_mask, box_loss_scale, prediction[:, :, :, :, :2], true_xy) | |||
| wh_loss = self.wh_loss(object_mask, box_loss_scale, prediction[:, :, :, :, 2:4], true_wh) | |||
| confidence_loss = self.confidenceLoss(object_mask, prediction[:, :, :, :, 4:5], ignore_mask) | |||
| class_loss = self.classLoss(object_mask, prediction[:, :, :, :, 5:], class_probs) | |||
| loss = xy_loss + wh_loss + confidence_loss + class_loss | |||
| batch_size = P.Shape()(prediction)[0] | |||
| return loss / batch_size | |||
| class YOLOV3DarkNet53(nn.Cell): | |||
| """ | |||
| Darknet based YOLOV3 network. | |||
| Args: | |||
| is_training: Bool. Whether train or not. | |||
| Returns: | |||
| Cell, cell instance of Darknet based YOLOV3 neural network. | |||
| Examples: | |||
| YOLOV3DarkNet53(True) | |||
| """ | |||
| def __init__(self, is_training): | |||
| super(YOLOV3DarkNet53, self).__init__() | |||
| self.config = ConfigYOLOV3DarkNet53() | |||
| # YOLOv3 network | |||
| self.feature_map = YOLOv3(backbone=DarkNet(ResidualBlock, self.config.backbone_layers, | |||
| self.config.backbone_input_shape, | |||
| self.config.backbone_shape, | |||
| detect=True), | |||
| backbone_shape=self.config.backbone_shape, | |||
| out_channel=self.config.out_channel) | |||
| # prediction on the default anchor boxes | |||
| self.detect_1 = DetectionBlock('l', is_training=is_training) | |||
| self.detect_2 = DetectionBlock('m', is_training=is_training) | |||
| self.detect_3 = DetectionBlock('s', is_training=is_training) | |||
| def construct(self, x, input_shape): | |||
| big_object_output, medium_object_output, small_object_output = self.feature_map(x) | |||
| output_big = self.detect_1(big_object_output, input_shape) | |||
| output_me = self.detect_2(medium_object_output, input_shape) | |||
| output_small = self.detect_3(small_object_output, input_shape) | |||
| # big is the final output which has smallest feature map | |||
| return output_big, output_me, output_small | |||
| class YoloWithLossCell(nn.Cell): | |||
| """YOLOV3 loss.""" | |||
| def __init__(self, network): | |||
| super(YoloWithLossCell, self).__init__() | |||
| self.yolo_network = network | |||
| self.config = ConfigYOLOV3DarkNet53() | |||
| self.loss_big = YoloLossBlock('l', self.config) | |||
| self.loss_me = YoloLossBlock('m', self.config) | |||
| self.loss_small = YoloLossBlock('s', self.config) | |||
| def construct(self, x, y_true_0, y_true_1, y_true_2, gt_0, gt_1, gt_2, input_shape): | |||
| yolo_out = self.yolo_network(x, input_shape) | |||
| loss_l = self.loss_big(*yolo_out[0], y_true_0, gt_0, input_shape) | |||
| loss_m = self.loss_me(*yolo_out[1], y_true_1, gt_1, input_shape) | |||
| loss_s = self.loss_small(*yolo_out[2], y_true_2, gt_2, input_shape) | |||
| return loss_l + loss_m + loss_s | |||
| class TrainingWrapper(nn.Cell): | |||
| """Training wrapper.""" | |||
| def __init__(self, network, optimizer, sens=1.0): | |||
| super(TrainingWrapper, self).__init__(auto_prefix=False) | |||
| self.network = network | |||
| self.network.set_grad() | |||
| self.weights = optimizer.parameters | |||
| self.optimizer = optimizer | |||
| self.grad = C.GradOperation(get_by_list=True, sens_param=True) | |||
| self.sens = sens | |||
| self.reducer_flag = False | |||
| self.grad_reducer = None | |||
| self.parallel_mode = context.get_auto_parallel_context("parallel_mode") | |||
| if self.parallel_mode in [ParallelMode.DATA_PARALLEL, ParallelMode.HYBRID_PARALLEL]: | |||
| self.reducer_flag = True | |||
| if self.reducer_flag: | |||
| mean = context.get_auto_parallel_context("gradients_mean") | |||
| if auto_parallel_context().get_device_num_is_set(): | |||
| degree = context.get_auto_parallel_context("device_num") | |||
| else: | |||
| degree = get_group_size() | |||
| self.grad_reducer = nn.DistributedGradReducer(optimizer.parameters, mean, degree) | |||
| def construct(self, *args): | |||
| weights = self.weights | |||
| loss = self.network(*args) | |||
| sens = P.Fill()(P.DType()(loss), P.Shape()(loss), self.sens) | |||
| grads = self.grad(self.network, weights)(*args, sens) | |||
| if self.reducer_flag: | |||
| grads = self.grad_reducer(grads) | |||
| return F.depend(loss, self.optimizer(grads)) | |||
+ 0
- 192
examples/model_security/model_attacks/cv/yolov3_darknet53/src/yolo_dataset.py
View File
| @@ -1,192 +0,0 @@ | |||
| # Copyright 2020 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| # ============================================================================ | |||
| """YOLOV3 dataset.""" | |||
| import os | |||
| import multiprocessing | |||
| import cv2 | |||
| from PIL import Image | |||
| from pycocotools.coco import COCO | |||
| import mindspore.dataset as de | |||
| import mindspore.dataset.vision.c_transforms as CV | |||
| from src.distributed_sampler import DistributedSampler | |||
| from src.transforms import reshape_fn, MultiScaleTrans | |||
| # pylint: disable=locally-disables, invalid-name | |||
| min_keypoints_per_image = 10 | |||
| def _has_only_empty_bbox(anno): | |||
| return all(any(o <= 1 for o in obj["bbox"][2:]) for obj in anno) | |||
| def _count_visible_keypoints(anno): | |||
| return sum(sum(1 for v in ann["keypoints"][2::3] if v > 0) for ann in anno) | |||
| def has_valid_annotation(anno): | |||
| """Check annotation file.""" | |||
| # if it's empty, there is no annotation | |||
| if not anno: | |||
| return False | |||
| # if all boxes have close to zero area, there is no annotation | |||
| if _has_only_empty_bbox(anno): | |||
| return False | |||
| # keypoints task have a slight different critera for considering | |||
| # if an annotation is valid | |||
| if "keypoints" not in anno[0]: | |||
| return True | |||
| # for keypoint detection tasks, only consider valid images those | |||
| # containing at least min_keypoints_per_image | |||
| if _count_visible_keypoints(anno) >= min_keypoints_per_image: | |||
| return True | |||
| return False | |||
| class COCOYoloDataset: | |||
| """YOLOV3 Dataset for COCO.""" | |||
| def __init__(self, root, ann_file, remove_images_without_annotations=True, | |||
| filter_crowd_anno=True, is_training=True): | |||
| self.coco = COCO(ann_file) | |||
| self.root = root | |||
| self.img_ids = list(sorted(self.coco.imgs.keys())) | |||
| self.filter_crowd_anno = filter_crowd_anno | |||
| self.is_training = is_training | |||
| # filter images without any annotations | |||
| if remove_images_without_annotations: | |||
| img_ids = [] | |||
| for img_id in self.img_ids: | |||
| ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=None) | |||
| anno = self.coco.loadAnns(ann_ids) | |||
| if has_valid_annotation(anno): | |||
| img_ids.append(img_id) | |||
| self.img_ids = img_ids | |||
| self.categories = {cat["id"]: cat["name"] for cat in self.coco.cats.values()} | |||
| self.cat_ids_to_continuous_ids = { | |||
| v: i for i, v in enumerate(self.coco.getCatIds()) | |||
| } | |||
| self.continuous_ids_cat_ids = { | |||
| v: k for k, v in self.cat_ids_to_continuous_ids.items() | |||
| } | |||
| def __getitem__(self, index): | |||
| """ | |||
| Args: | |||
| index (int): Index | |||
| Returns: | |||
| (img, target) (tuple): target is a dictionary contains "bbox", "segmentation" or "keypoints", | |||
| generated by the image's annotation. img is a PIL image. | |||
| """ | |||
| coco = self.coco | |||
| img_id = self.img_ids[index] | |||
| img_path = coco.loadImgs(img_id)[0]["file_name"] | |||
| img = Image.open(os.path.join(self.root, img_path)).convert("RGB") | |||
| if not self.is_training: | |||
| return img, img_id | |||
| ann_ids = coco.getAnnIds(imgIds=img_id) | |||
| target = coco.loadAnns(ann_ids) | |||
| # filter crowd annotations | |||
| if self.filter_crowd_anno: | |||
| annos = [anno for anno in target if anno["iscrowd"] == 0] | |||
| else: | |||
| annos = [anno for anno in target] | |||
| target = {} | |||
| boxes = [anno["bbox"] for anno in annos] | |||
| target["bboxes"] = boxes | |||
| classes = [anno["category_id"] for anno in annos] | |||
| classes = [self.cat_ids_to_continuous_ids[cl] for cl in classes] | |||
| target["labels"] = classes | |||
| bboxes = target['bboxes'] | |||
| labels = target['labels'] | |||
| out_target = [] | |||
| for bbox, label in zip(bboxes, labels): | |||
| tmp = [] | |||
| # convert to [x_min y_min x_max y_max] | |||
| bbox = self._convetTopDown(bbox) | |||
| tmp.extend(bbox) | |||
| tmp.append(int(label)) | |||
| # tmp [x_min y_min x_max y_max, label] | |||
| out_target.append(tmp) | |||
| return img, out_target, [], [], [], [], [], [] | |||
| def __len__(self): | |||
| return len(self.img_ids) | |||
| def _convetTopDown(self, bbox): | |||
| x_min = bbox[0] | |||
| y_min = bbox[1] | |||
| w = bbox[2] | |||
| h = bbox[3] | |||
| return [x_min, y_min, x_min+w, y_min+h] | |||
| def create_yolo_dataset(image_dir, anno_path, batch_size, max_epoch, device_num, rank, | |||
| config=None, is_training=True, shuffle=True): | |||
| """Create dataset for YOLOV3.""" | |||
| cv2.setNumThreads(0) | |||
| if is_training: | |||
| filter_crowd = True | |||
| remove_empty_anno = True | |||
| else: | |||
| filter_crowd = False | |||
| remove_empty_anno = False | |||
| yolo_dataset = COCOYoloDataset(root=image_dir, ann_file=anno_path, filter_crowd_anno=filter_crowd, | |||
| remove_images_without_annotations=remove_empty_anno, is_training=is_training) | |||
| distributed_sampler = DistributedSampler(len(yolo_dataset), device_num, rank, shuffle=shuffle) | |||
| hwc_to_chw = CV.HWC2CHW() | |||
| config.dataset_size = len(yolo_dataset) | |||
| cores = multiprocessing.cpu_count() | |||
| num_parallel_workers = int(cores / device_num) | |||
| if is_training: | |||
| multi_scale_trans = MultiScaleTrans(config, device_num) | |||
| dataset_column_names = ["image", "annotation", "bbox1", "bbox2", "bbox3", | |||
| "gt_box1", "gt_box2", "gt_box3"] | |||
| if device_num != 8: | |||
| ds = de.GeneratorDataset(yolo_dataset, column_names=dataset_column_names, | |||
| num_parallel_workers=min(32, num_parallel_workers), | |||
| sampler=distributed_sampler) | |||
| ds = ds.batch(batch_size, per_batch_map=multi_scale_trans, input_columns=dataset_column_names, | |||
| num_parallel_workers=min(32, num_parallel_workers), drop_remainder=True) | |||
| else: | |||
| ds = de.GeneratorDataset(yolo_dataset, column_names=dataset_column_names, sampler=distributed_sampler) | |||
| ds = ds.batch(batch_size, per_batch_map=multi_scale_trans, input_columns=dataset_column_names, | |||
| num_parallel_workers=min(8, num_parallel_workers), drop_remainder=True) | |||
| else: | |||
| ds = de.GeneratorDataset(yolo_dataset, column_names=["image", "img_id"], | |||
| sampler=distributed_sampler) | |||
| compose_map_func = (lambda image, img_id: reshape_fn(image, img_id, config)) | |||
| ds = ds.map(operations=compose_map_func, input_columns=["image", "img_id"], | |||
| output_columns=["image", "image_shape", "img_id"], | |||
| column_order=["image", "image_shape", "img_id"], | |||
| num_parallel_workers=8) | |||
| ds = ds.map(operations=hwc_to_chw, input_columns=["image"], num_parallel_workers=8) | |||
| ds = ds.batch(batch_size, drop_remainder=True) | |||
| ds = ds.repeat(max_epoch) | |||
| return ds, len(yolo_dataset) | |||
+ 0
- 0
examples/model_security/model_attacks/white_box/__init__.py
View File
+ 0
- 111
examples/model_security/model_attacks/white_box/mnist_attack_mdi2fgsm.py
View File
| @@ -1,111 +0,0 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| import time | |||
| import numpy as np | |||
| from scipy.special import softmax | |||
| from mindspore import Model | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore.train.serialization import load_checkpoint, load_param_into_net | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindarmour.adv_robustness.attacks import MomentumDiverseInputIterativeMethod | |||
| from mindarmour.adv_robustness.evaluations import AttackEvaluate | |||
| from mindarmour.utils.logger import LogUtil | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| LOGGER = LogUtil.get_instance() | |||
| TAG = 'M_DI2_FGSM_Test' | |||
| LOGGER.set_level('INFO') | |||
| def test_momentum_diverse_input_iterative_method(): | |||
| """ | |||
| M-DI2-FGSM Attack Test for CPU device. | |||
| """ | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| # upload trained network | |||
| ckpt_path = '../../../common/networks/lenet5/trained_ckpt_file/checkpoint_lenet-10_1875.ckpt' | |||
| net = LeNet5() | |||
| load_dict = load_checkpoint(ckpt_path) | |||
| load_param_into_net(net, load_dict) | |||
| # get test data | |||
| data_list = "../../../common/dataset/MNIST/test" | |||
| batch_size = 32 | |||
| ds = generate_mnist_dataset(data_list, batch_size) | |||
| # prediction accuracy before attack | |||
| model = Model(net) | |||
| batch_num = 32 # the number of batches of attacking samples | |||
| test_images = [] | |||
| test_labels = [] | |||
| predict_labels = [] | |||
| i = 0 | |||
| for data in ds.create_tuple_iterator(output_numpy=True): | |||
| i += 1 | |||
| images = data[0].astype(np.float32) | |||
| labels = data[1] | |||
| test_images.append(images) | |||
| test_labels.append(labels) | |||
| pred_labels = np.argmax(model.predict(Tensor(images)).asnumpy(), | |||
| axis=1) | |||
| predict_labels.append(pred_labels) | |||
| if i >= batch_num: | |||
| break | |||
| predict_labels = np.concatenate(predict_labels) | |||
| true_labels = np.concatenate(test_labels) | |||
| accuracy = np.mean(np.equal(predict_labels, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy before attacking is : %s", accuracy) | |||
| # attacking | |||
| loss = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| attack = MomentumDiverseInputIterativeMethod(net, loss_fn=loss) | |||
| start_time = time.clock() | |||
| adv_data = attack.batch_generate(np.concatenate(test_images), | |||
| true_labels, batch_size=32) | |||
| stop_time = time.clock() | |||
| pred_logits_adv = model.predict(Tensor(adv_data)).asnumpy() | |||
| # rescale predict confidences into (0, 1). | |||
| pred_logits_adv = softmax(pred_logits_adv, axis=1) | |||
| pred_labels_adv = np.argmax(pred_logits_adv, axis=1) | |||
| accuracy_adv = np.mean(np.equal(pred_labels_adv, true_labels)) | |||
| LOGGER.info(TAG, "prediction accuracy after attacking is : %s", accuracy_adv) | |||
| attack_evaluate = AttackEvaluate(np.concatenate(test_images).transpose(0, 2, 3, 1), | |||
| np.eye(10)[true_labels], | |||
| adv_data.transpose(0, 2, 3, 1), | |||
| pred_logits_adv) | |||
| LOGGER.info(TAG, 'mis-classification rate of adversaries is : %s', | |||
| attack_evaluate.mis_classification_rate()) | |||
| LOGGER.info(TAG, 'The average confidence of adversarial class is : %s', | |||
| attack_evaluate.avg_conf_adv_class()) | |||
| LOGGER.info(TAG, 'The average confidence of true class is : %s', | |||
| attack_evaluate.avg_conf_true_class()) | |||
| LOGGER.info(TAG, 'The average distance (l0, l2, linf) between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_lp_distance()) | |||
| LOGGER.info(TAG, 'The average structural similarity between original ' | |||
| 'samples and adversarial samples are: %s', | |||
| attack_evaluate.avg_ssim()) | |||
| LOGGER.info(TAG, 'The average costing time is %s', | |||
| (stop_time - start_time)/(batch_num*batch_size)) | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="CPU") | |||
| test_momentum_diverse_input_iterative_method() | |||
+ 0
- 0
examples/model_security/model_defenses/__init__.py
View File
+ 0
- 116
examples/model_security/model_defenses/mnist_defense_nad.py
View File
| @@ -1,116 +0,0 @@ | |||
| # Copyright 2019 Huawei Technologies Co., Ltd | |||
| # | |||
| # Licensed under the Apache License, Version 2.0 (the "License"); | |||
| # you may not use this file except in compliance with the License. | |||
| # You may obtain a copy of the License at | |||
| # | |||
| # http://www.apache.org/licenses/LICENSE-2.0 | |||
| # | |||
| # Unless required by applicable law or agreed to in writing, software | |||
| # distributed under the License is distributed on an "AS IS" BASIS, | |||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |||
| # See the License for the specific language governing permissions and | |||
| # limitations under the License. | |||
| """defense example using nad""" | |||
| import os | |||
| import numpy as np | |||
| from mindspore import Tensor | |||
| from mindspore import context | |||
| from mindspore import nn | |||
| from mindspore.nn import SoftmaxCrossEntropyWithLogits | |||
| from mindspore.train import Model | |||
| from mindspore.train.callback import LossMonitor | |||
| from mindarmour.adv_robustness.attacks import FastGradientSignMethod | |||
| from mindarmour.adv_robustness.defenses import NaturalAdversarialDefense | |||
| from mindarmour.utils.logger import LogUtil | |||
| from examples.common.networks.lenet5.lenet5_net import LeNet5 | |||
| from examples.common.dataset.data_processing import generate_mnist_dataset | |||
| LOGGER = LogUtil.get_instance() | |||
| LOGGER.set_level("INFO") | |||
| TAG = 'Nad_Example' | |||
| def test_nad_method(): | |||
| """ | |||
| NAD-Defense test. | |||
| """ | |||
| mnist_path = "../../common/dataset/MNIST" | |||
| batch_size = 32 | |||
| # 1. train original model | |||
| ds_train = generate_mnist_dataset(os.path.join(mnist_path, "train"), | |||
| batch_size=batch_size, repeat_size=1) | |||
| net = LeNet5() | |||
| loss = SoftmaxCrossEntropyWithLogits(sparse=True) | |||
| opt = nn.Momentum(net.trainable_params(), 0.01, 0.09) | |||
| model = Model(net, loss, opt, metrics=None) | |||
| model.train(10, ds_train, callbacks=[LossMonitor()], | |||
| dataset_sink_mode=False) | |||
| # 2. get test data | |||
| ds_test = generate_mnist_dataset(os.path.join(mnist_path, "test"), | |||
| batch_size=batch_size, repeat_size=1) | |||
| inputs = [] | |||
| labels = [] | |||
| for data in ds_test.create_tuple_iterator(output_numpy=True): | |||
| inputs.append(data[0].astype(np.float32)) | |||
| labels.append(data[1]) | |||
| inputs = np.concatenate(inputs) | |||
| labels = np.concatenate(labels) | |||
| # 3. get accuracy of test data on original model | |||
| net.set_train(False) | |||
| logits = net(Tensor(inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc = np.mean(labels == label_pred) | |||
| LOGGER.info(TAG, 'accuracy of TEST data on original model is : %s', acc) | |||
| # 4. get adv of test data | |||
| attack = FastGradientSignMethod(net, eps=0.3, loss_fn=loss) | |||
| adv_data = attack.batch_generate(inputs, labels) | |||
| LOGGER.info(TAG, 'adv_data.shape is : %s', adv_data.shape) | |||
| # 5. get accuracy of adv data on original model | |||
| net.set_train(False) | |||
| logits = net(Tensor(adv_data)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc = np.mean(labels == label_pred) | |||
| LOGGER.info(TAG, 'accuracy of adv data on original model is : %s', acc) | |||
| # 6. defense | |||
| ds_train = generate_mnist_dataset(os.path.join(mnist_path, "train"), | |||
| batch_size=batch_size, repeat_size=1) | |||
| inputs_train = [] | |||
| labels_train = [] | |||
| for data in ds_train.create_tuple_iterator(output_numpy=True): | |||
| inputs_train.append(data[0].astype(np.float32)) | |||
| labels_train.append(data[1]) | |||
| inputs_train = np.concatenate(inputs_train) | |||
| labels_train = np.concatenate(labels_train) | |||
| net.set_train() | |||
| nad = NaturalAdversarialDefense(net, loss_fn=loss, optimizer=opt, | |||
| bounds=(0.0, 1.0), eps=0.3) | |||
| nad.batch_defense(inputs_train, labels_train, batch_size=32, epochs=10) | |||
| # 7. get accuracy of test data on defensed model | |||
| net.set_train(False) | |||
| logits = net(Tensor(inputs)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc = np.mean(labels == label_pred) | |||
| LOGGER.info(TAG, 'accuracy of TEST data on defensed model is : %s', acc) | |||
| # 8. get accuracy of adv data on defensed model | |||
| logits = net(Tensor(adv_data)).asnumpy() | |||
| label_pred = np.argmax(logits, axis=1) | |||
| acc = np.mean(labels == label_pred) | |||
| LOGGER.info(TAG, 'accuracy of adv data on defensed model is : %s', acc) | |||
| if __name__ == '__main__': | |||
| # device_target can be "CPU", "GPU" or "Ascend" | |||
| context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") | |||
| test_nad_method() | |||
+ 0
- 66
examples/privacy/README.md
View File
| @@ -1,66 +0,0 @@ | |||
| # Application demos of privacy stealing and privacy protection | |||
| ## Introduction | |||
| Although machine learning could obtain a generic model based on training data, it has been proved that the trained | |||
| model may disclose the information of training data (such as the membership inference attack). | |||
| Differential privacy training is an effective method proposed to overcome this problem, in which Gaussian noise is | |||
| added while training. There are mainly three parts for differential privacy(DP) training: noise-generating | |||
| mechanism, DP optimizer and DP monitor. We have implemented a novel noise-generating mechanisms: adaptive decay | |||
| noise mechanism. DP monitor is used to compute the privacy budget while training. | |||
| Suppress Privacy training is a novel method to protect privacy distinct from the noise addition method | |||
| (such as DP), in which the negligible model parameter is removed gradually to achieve a better balance between | |||
| accuracy and privacy. | |||
| ## 1. Adaptive decay DP training | |||
| With adaptive decay mechanism, the magnitude of the Gaussian noise would be decayed as the training step grows, which | |||
| resulting a stable convergence. | |||
| ```sh | |||
| cd examples/privacy/diff_privacy | |||
| python lenet5_dp_ada_gaussian.py | |||
| ``` | |||
| ## 2. Adaptive norm clip training | |||
| With adaptive norm clip mechanism, the norm clip of the gradients would be changed according to the norm values of | |||
| them, which can adjust the ratio of noise and original gradients. | |||
| ```sh | |||
| cd examples/privacy/diff_privacy | |||
| python lenet5_dp.py | |||
| ``` | |||
| ## 3. Membership inference evaluation | |||
| By this evaluation method, we could judge whether a sample is belongs to training dataset or not. | |||
| ```sh | |||
| cd examples/privacy/membership_inference_attack | |||
| python train.py --data_path home_path_to_cifar100 --ckpt_path ./ | |||
| python example_vgg_cifar.py --data_path home_path_to_cifar100 --pre_trained 0-100_781.ckpt | |||
| ``` | |||
| ## 4. Suppress privacy training | |||
| With suppress privacy mechanism, the values of some trainable parameters (such as conv layers and fully connected | |||
| layers) are set to zero as the training step grows, which can | |||
| achieve a better balance between accuracy and privacy | |||
| ```sh | |||
| cd examples/privacy/sup_privacy | |||
| python sup_privacy.py | |||
| ``` | |||
| ## 5. Image inversion attack | |||
| Inversion attack means reconstructing an image based on its deep representations. For example, | |||
| reconstruct a MNIST image based on its output through LeNet5. The mechanism behind it is that well-trained | |||
| model can "remember" those training dataset. Therefore, inversion attack can be used to estimate the privacy | |||
| leakage of training tasks. | |||
| ```sh | |||
| cd examples/privacy/inversion_attack | |||
| python mnist_inversion_attack.py | |||
| ``` | |||